 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePvDeConv: Point-Voxel Deconvolution for Autoencoding CAD Construction in 3D
Paper and Code
Jan 12, 2021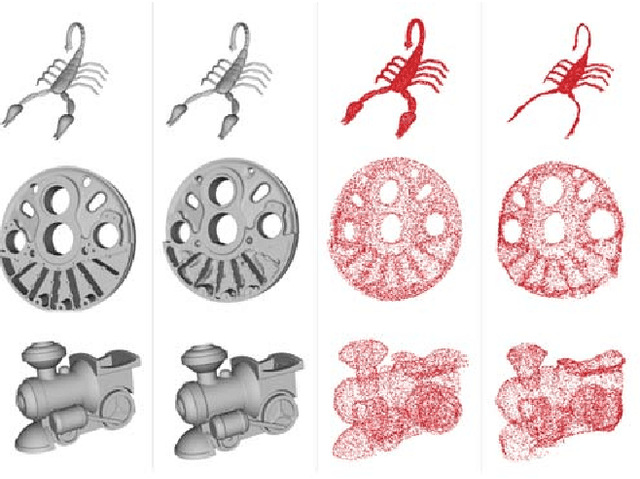



We propose a Point-Voxel DeConvolution (PVDeConv) module for 3D data autoencoder. To demonstrate its efficiency we learn to synthesize high-resolution point clouds of 10k points that densely describe the underlying geometry of Computer Aided Design (CAD) models. Scanning artifacts, such as protrusions, missing parts, smoothed edges and holes, inevitably appear in real 3D scans of fabricated CAD objects. Learning the original CAD model construction from a 3D scan requires a ground truth to be available together with the corresponding 3D scan of an object. To solve the gap, we introduce a new dedicated dataset, the CC3D, containing 50k+ pairs of CAD models and their corresponding 3D meshes. This dataset is used to learn a convolutional autoencoder for point clouds sampled from the pairs of 3D scans - CAD models. The challenges of this new dataset are demonstrated in comparison with other generative point cloud sampling models trained on ShapeNet. The CC3D autoencoder is efficient with respect to memory consumption and training time as compared to stateof-the-art models for 3D data generation.