 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Banking Dataset: Understanding Client Needs through Event Sequences
Sep 26, 2024Financial organizations collect a huge amount of data about clients that typically has a temporal (sequential) structure and is collected from various sources (modalities). Due to privacy issues, there are no large-scale open-source multimodal datasets of event sequences, which significantly limits the research in this area. In this paper, we present the industrial-scale publicly available multimodal banking dataset, MBD, that contains more than 1.5M corporate clients with several modalities: 950M bank transactions, 1B geo position events, 5M embeddings of dialogues with technical support and monthly aggregated purchases of four bank's products. All entries are properly anonymized from real proprietary bank data. Using this dataset, we introduce a novel benchmark with two business tasks: campaigning (purchase prediction in the next month) and matching of clients. We provide numerical results that demonstrate the superiority of our multi-modal baselines over single-modal techniques for each task. As a result, the proposed dataset can open new perspectives and facilitate the future development of practically important large-scale multimodal algorithms for event sequences. HuggingFace Link: https://huggingface.co/datasets/ai-lab/MBD Github Link: https://github.com/Dzhambo/MBD
DeTPP: Leveraging Object Detection for Robust Long-Horizon Event Prediction
Aug 23, 2024Forecasting future events over extended periods, known as long-horizon prediction, is a fundamental task in various domains, including retail, finance, healthcare, and social networks. Traditional methods, such as Marked Temporal Point Processes (MTPP), typically use autoregressive models to predict multiple future events. However, these models frequently encounter issues such as converging to constant or repetitive outputs, which significantly limits their effectiveness and applicability. To overcome these limitations, we propose DeTPP (Detection-based Temporal Point Processes), a novel approach inspired by object detection methods from computer vision. DeTPP utilizes a novel matching-based loss function that selectively focuses on reliably predictable events, enhancing both training robustness and inference diversity. Our method sets a new state-of-the-art in long-horizon event prediction, significantly outperforming existing MTPP and next-K approaches. The implementation of DeTPP is publicly available on GitHub.
HoTPP Benchmark: Are We Good at the Long Horizon Events Forecasting?
Jun 20, 2024



In sequential event prediction, which finds applications in finance, retail, social networks, and healthcare, a crucial task is forecasting multiple future events within a specified time horizon. Traditionally, this has been addressed through autoregressive generation using next-event prediction models, such as Marked Temporal Point Processes. However, autoregressive methods use their own output for future predictions, potentially reducing quality as the prediction horizon extends. In this paper, we challenge traditional approaches by introducing a novel benchmark, HoTPP, specifically designed to evaluate a model's ability to predict event sequences over a horizon. This benchmark features a new metric inspired by object detection in computer vision, addressing the limitations of existing metrics in assessing models with imprecise time-step predictions. Our evaluations on established datasets employing various models demonstrate that high accuracy in next-event prediction does not necessarily translate to superior horizon prediction, and vice versa. HoTPP aims to serve as a valuable tool for developing more robust event sequence prediction methods, ultimately paving the way for further advancements in the field.
Catching Image Retrieval Generalization
Jun 23, 2023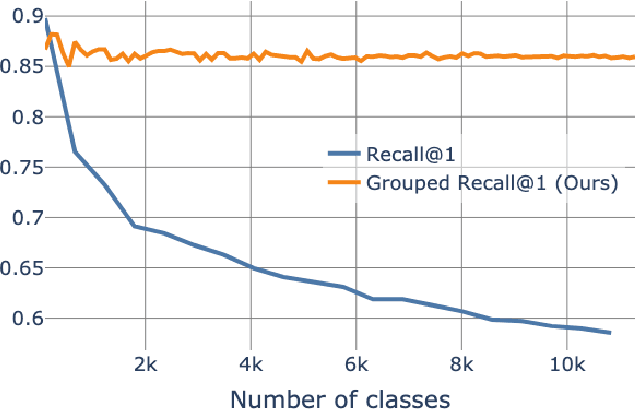

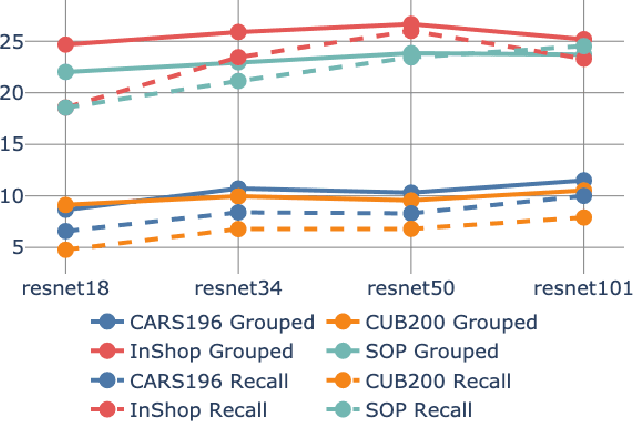

The concepts of overfitting and generalization are vital for evaluating machine learning models. In this work, we show that the popular Recall@K metric depends on the number of classes in the dataset, which limits its ability to estimate generalization. To fix this issue, we propose a new metric, which measures retrieval performance, and, unlike Recall@K, estimates generalization. We apply the proposed metric to popular image retrieval methods and provide new insights about deep metric learning generalization.
Diversifying Deep Ensembles: A Saliency Map Approach for Enhanced OOD Detection, Calibration, and Accuracy
May 19, 2023



Deep ensembles achieved state-of-the-art results in classification and out-of-distribution (OOD) detection; however, their effectiveness remains limited due to the homogeneity of learned patterns within the ensemble. To overcome this challenge, our study introduces a novel approach that promotes diversity among ensemble members by leveraging saliency maps. By incorporating saliency map diversification, our method outperforms conventional ensemble techniques in multiple classification and OOD detection tasks, while also improving calibration. Experiments on well-established OpenOOD benchmarks highlight the potential of our method in practical applications.
Deep Image Retrieval is not Robust to Label Noise
May 23, 2022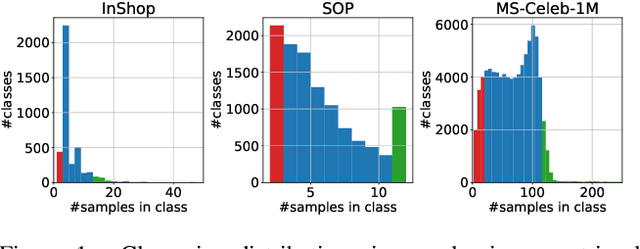
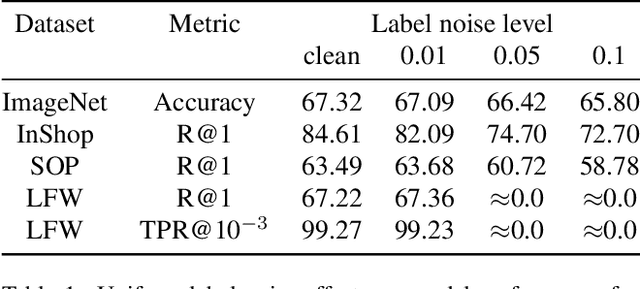
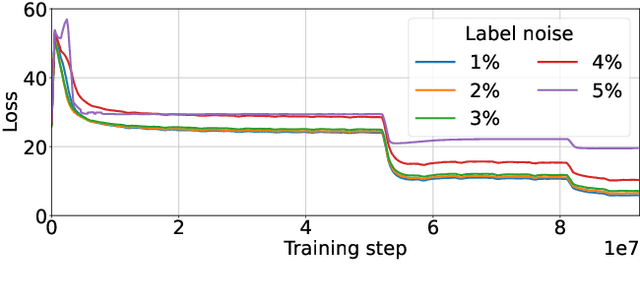
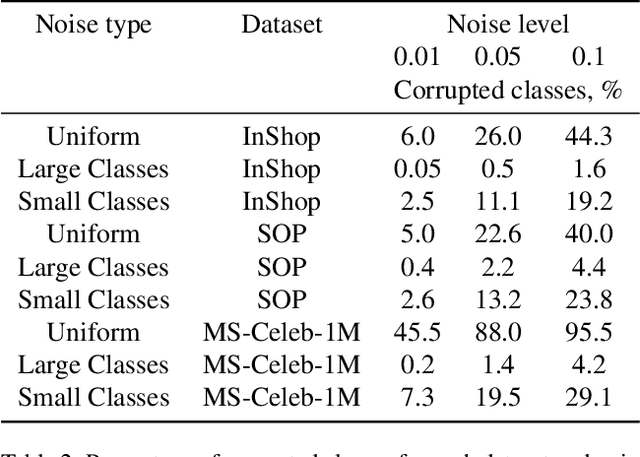
Large-scale datasets are essential for the success of deep learning in image retrieval. However, manual assessment errors and semi-supervised annotation techniques can lead to label noise even in popular datasets. As previous works primarily studied annotation quality in image classification tasks, it is still unclear how label noise affects deep learning approaches to image retrieval. In this work, we show that image retrieval methods are less robust to label noise than image classification ones. Furthermore, we, for the first time, investigate different types of label noise specific to image retrieval tasks and study their effect on model performance.
EXACT: How to Train Your Accuracy
May 19, 2022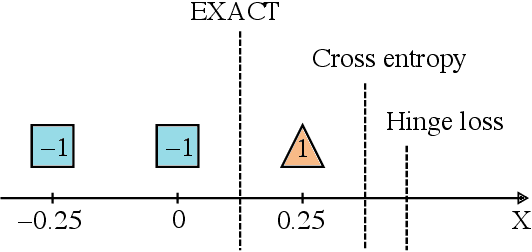

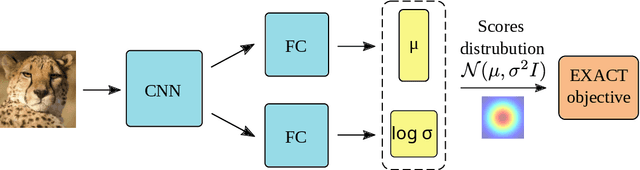
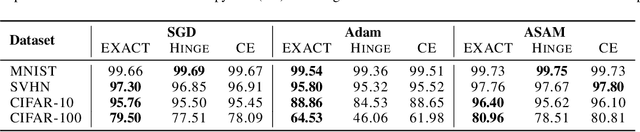
Classification tasks are usually evaluated in terms of accuracy. However, accuracy is discontinuous and cannot be directly optimized using gradient ascent. Popular methods minimize cross-entropy, Hinge loss, or other surrogate losses, which can lead to suboptimal results. In this paper, we propose a new optimization framework by introducing stochasticity to a model's output and optimizing expected accuracy, i.e. accuracy of the stochastic model. Extensive experiments on image classification show that the proposed optimization method is a powerful alternative to widely used classification losses.
Probabilistic Embeddings Revisited
Feb 14, 2022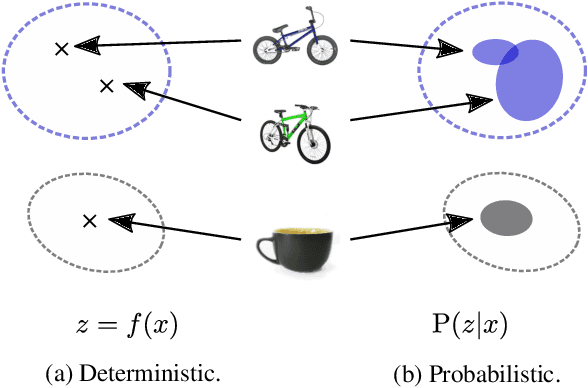
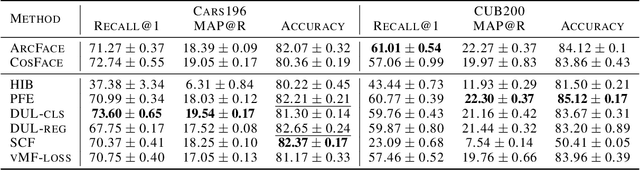
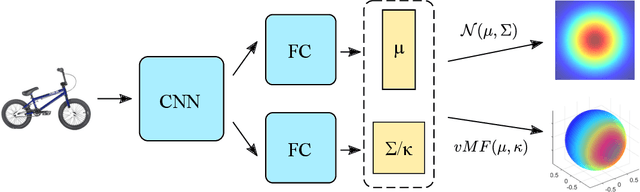
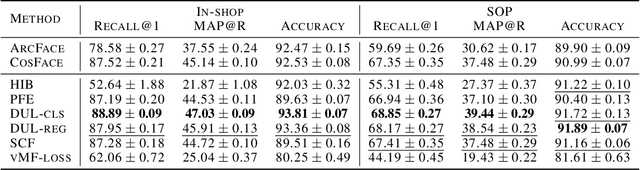
In recent years, deep metric learning and its probabilistic extensions achieved state-of-the-art results in a face verification task. However, despite improvements in face verification, probabilistic methods received little attention in the community. It is still unclear whether they can improve image retrieval quality. In this paper, we present an extensive comparison of probabilistic methods in verification and retrieval tasks. Following the suggested methodology, we outperform metric learning baselines using probabilistic methods and propose several directions for future work and improvements.