 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAFERec: Self-Attention and Frequency Enriched Model for Next Basket Recommendation
Dec 18, 2024Transformer-based approaches such as BERT4Rec and SASRec demonstrate strong performance in Next Item Recommendation (NIR) tasks. However, applying these architectures to Next-Basket Recommendation (NBR) tasks, which often involve highly repetitive interactions, is challenging due to the vast number of possible item combinations in a basket. Moreover, frequency-based methods such as TIFU-KNN and UP-CF still demonstrate strong performance in NBR tasks, frequently outperforming deep-learning approaches. This paper introduces SAFERec, a novel algorithm for NBR that enhances transformer-based architectures from NIR by incorporating item frequency information, consequently improving their applicability to NBR tasks. Extensive experiments on multiple datasets show that SAFERec outperforms all other baselines, specifically achieving an 8\% improvement in Recall@10.
Revisiting BPR: A Replicability Study of a Common Recommender System Baseline
Sep 21, 2024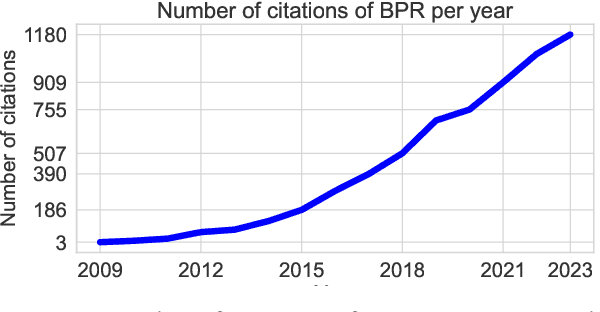
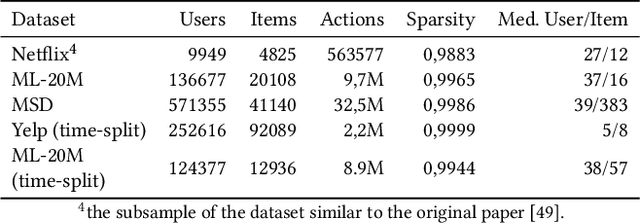
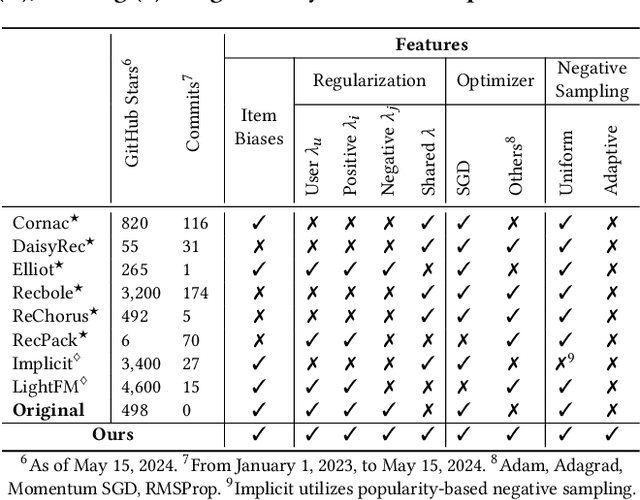
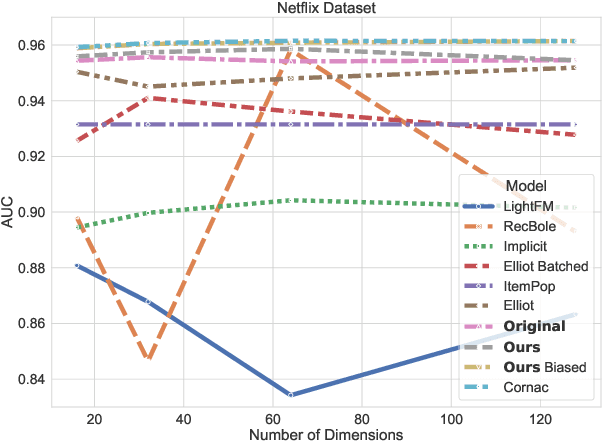
Bayesian Personalized Ranking (BPR), a collaborative filtering approach based on matrix factorization, frequently serves as a benchmark for recommender systems research. However, numerous studies often overlook the nuances of BPR implementation, claiming that it performs worse than newly proposed methods across various tasks. In this paper, we thoroughly examine the features of the BPR model, indicating their impact on its performance, and investigate open-source BPR implementations. Our analysis reveals inconsistencies between these implementations and the original BPR paper, leading to a significant decrease in performance of up to 50% for specific implementations. Furthermore, through extensive experiments on real-world datasets under modern evaluation settings, we demonstrate that with proper tuning of its hyperparameters, the BPR model can achieve performance levels close to state-of-the-art methods on the top-n recommendation tasks and even outperform them on specific datasets. Specifically, on the Million Song Dataset, the BPR model with hyperparameters tuning statistically significantly outperforms Mult-VAE by 10% in NDCG@100 with binary relevance function.
Time-Aware Item Weighting for the Next Basket Recommendations
Jul 30, 2023



In this paper we study the next basket recommendation problem. Recent methods use different approaches to achieve better performance. However, many of them do not use information about the time of prediction and time intervals between baskets. To fill this gap, we propose a novel method, Time-Aware Item-based Weighting (TAIW), which takes timestamps and intervals into account. We provide experiments on three real-world datasets, and TAIW outperforms well-tuned state-of-the-art baselines for next-basket recommendations. In addition, we show the results of an ablation study and a case study of a few items.
RecBaselines2023: a new dataset for choosing baselines for recommender models
Jun 25, 2023
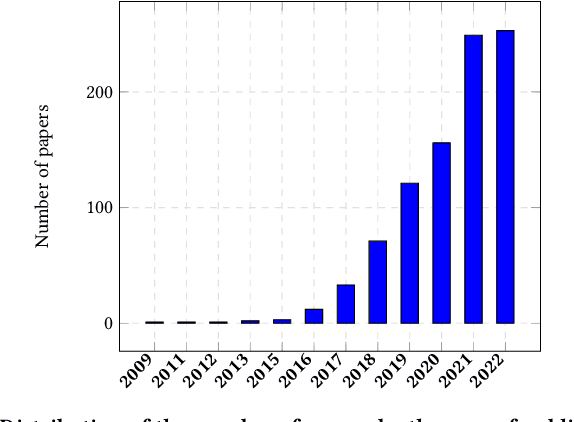
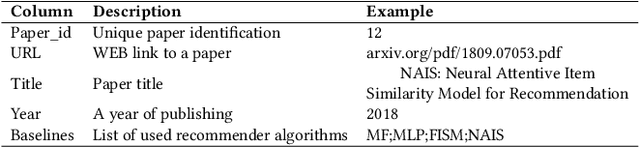
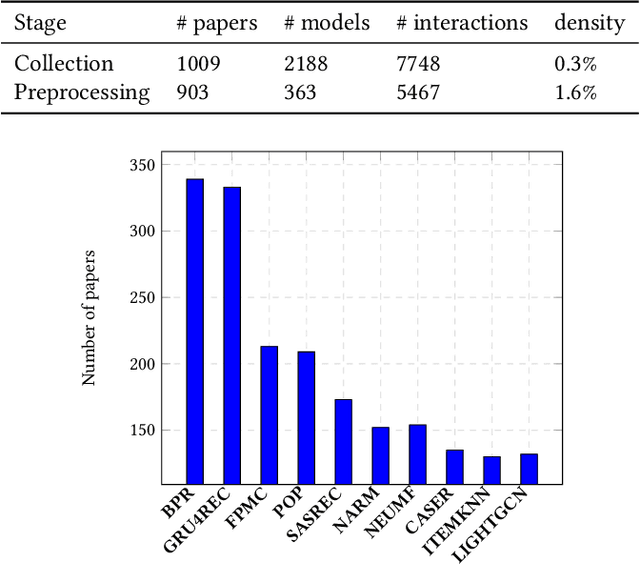
The number of proposed recommender algorithms continues to grow. The authors propose new approaches and compare them with existing models, called baselines. Due to the large number of recommender models, it is difficult to estimate which algorithms to choose in the article. To solve this problem, we have collected and published a dataset containing information about the recommender models used in 903 papers, both as baselines and as proposed approaches. This dataset can be seen as a typical dataset with interactions between papers and previously proposed models. In addition, we provide a descriptive analysis of the dataset and highlight possible challenges to be investigated with the data. Furthermore, we have conducted extensive experiments using a well-established methodology to build a good recommender algorithm under the dataset. Our experiments show that the selection of the best baselines for proposing new recommender approaches can be considered and successfully solved by existing state-of-the-art collaborative filtering models. Finally, we discuss limitations and future work.
TTRS: Tinkoff Transactions Recommender System benchmark
Oct 11, 2021


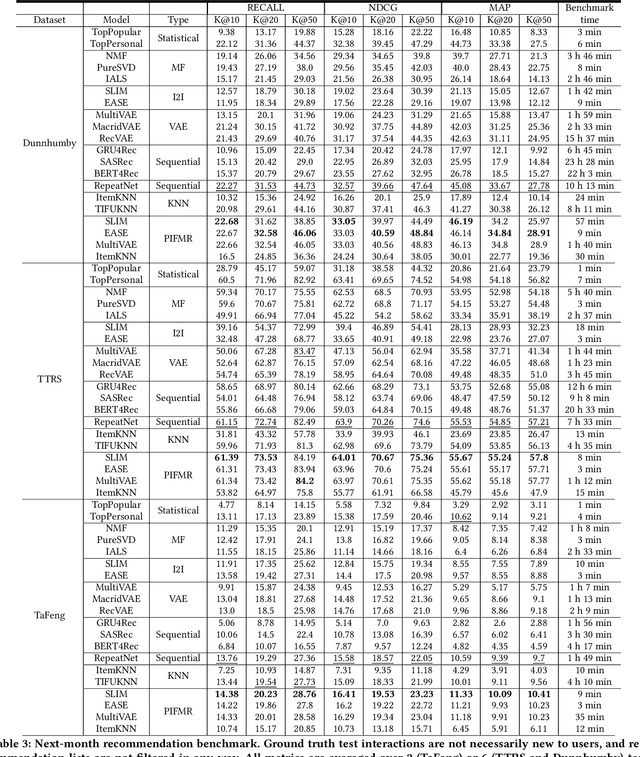
Over the past decade, tremendous progress has been made in inventing new RecSys methods. However, one of the fundamental problems of the RecSys research community remains the lack of applied datasets and benchmarks with well-defined evaluation rules and metrics to test these novel approaches. In this article, we present the TTRS - Tinkoff Transactions Recommender System benchmark. This financial transaction benchmark contains over 2 million interactions between almost 10,000 users and more than 1,000 merchant brands over 14 months. To the best of our knowledge, this is the first publicly available financial transactions dataset. To make it more suitable for possible applications, we provide a complete description of the data collection pipeline, its preprocessing, and the resulting dataset statistics. We also present a comprehensive comparison of the current popular RecSys methods on the next-period recommendation task and conduct a detailed analysis of their performance against various metrics and recommendation goals. Last but not least, we also introduce Personalized Item-Frequencies-based Model (Re)Ranker - PIFMR, a simple yet powerful approach that has proven to be the most effective for the benchmarked tasks.