 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFluid Representations in Reasoning Models
Feb 04, 2026Reasoning language models, which generate long chains of thought, dramatically outperform non-reasoning language models on abstract problems. However, the internal model mechanisms that allow this superior performance remain poorly understood. We present a mechanistic analysis of how QwQ-32B - a model specifically trained to produce extensive reasoning traces - process abstract structural information. On Mystery Blocksworld - a semantically obfuscated planning domain - we find that QwQ-32B gradually improves its internal representation of actions and concepts during reasoning. The model develops abstract encodings that focus on structure rather than specific action names. Through steering experiments, we establish causal evidence that these adaptations improve problem solving: injecting refined representations from successful traces boosts accuracy, while symbolic representations can replace many obfuscated encodings with minimal performance loss. We find that one of the factors driving reasoning model performance is in-context refinement of token representations, which we dub Fluid Reasoning Representations.
Interpreting Large Text-to-Image Diffusion Models with Dictionary Learning
May 30, 2025Sparse autoencoders are a promising new approach for decomposing language model activations for interpretation and control. They have been applied successfully to vision transformer image encoders and to small-scale diffusion models. Inference-Time Decomposition of Activations (ITDA) is a recently proposed variant of dictionary learning that takes the dictionary to be a set of data points from the activation distribution and reconstructs them with gradient pursuit. We apply Sparse Autoencoders (SAEs) and ITDA to a large text-to-image diffusion model, Flux 1, and consider the interpretability of embeddings of both by introducing a visual automated interpretation pipeline. We find that SAEs accurately reconstruct residual stream embeddings and beat MLP neurons on interpretability. We are able to use SAE features to steer image generation through activation addition. We find that ITDA has comparable interpretability to SAEs.
Scaling sparse feature circuit finding for in-context learning
Apr 18, 2025Sparse autoencoders (SAEs) are a popular tool for interpreting large language model activations, but their utility in addressing open questions in interpretability remains unclear. In this work, we demonstrate their effectiveness by using SAEs to deepen our understanding of the mechanism behind in-context learning (ICL). We identify abstract SAE features that (i) encode the model's knowledge of which task to execute and (ii) whose latent vectors causally induce the task zero-shot. This aligns with prior work showing that ICL is mediated by task vectors. We further demonstrate that these task vectors are well approximated by a sparse sum of SAE latents, including these task-execution features. To explore the ICL mechanism, we adapt the sparse feature circuits methodology of Marks et al. (2024) to work for the much larger Gemma-1 2B model, with 30 times as many parameters, and to the more complex task of ICL. Through circuit finding, we discover task-detecting features with corresponding SAE latents that activate earlier in the prompt, that detect when tasks have been performed. They are causally linked with task-execution features through the attention and MLP sublayers.
Is Value Functions Estimation with Classification Plug-and-play for Offline Reinforcement Learning?
Jun 10, 2024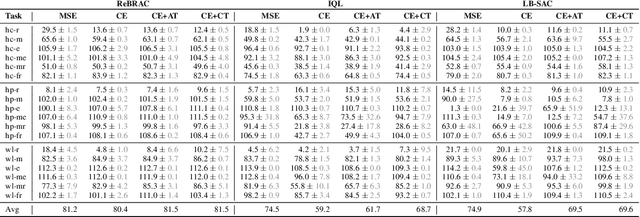



In deep Reinforcement Learning (RL), value functions are typically approximated using deep neural networks and trained via mean squared error regression objectives to fit the true value functions. Recent research has proposed an alternative approach, utilizing the cross-entropy classification objective, which has demonstrated improved performance and scalability of RL algorithms. However, existing study have not extensively benchmarked the effects of this replacement across various domains, as the primary objective was to demonstrate the efficacy of the concept across a broad spectrum of tasks, without delving into in-depth analysis. Our work seeks to empirically investigate the impact of such a replacement in an offline RL setup and analyze the effects of different aspects on performance. Through large-scale experiments conducted across a diverse range of tasks using different algorithms, we aim to gain deeper insights into the implications of this approach. Our results reveal that incorporating this change can lead to superior performance over state-of-the-art solutions for some algorithms in certain tasks, while maintaining comparable performance levels in other tasks, however for other algorithms this modification might lead to the dramatic performance drop. This findings are crucial for further application of classification approach in research and practical tasks.
CausalQuest: Collecting Natural Causal Questions for AI Agents
May 30, 2024



Humans have an innate drive to seek out causality. Whether fuelled by curiosity or specific goals, we constantly question why things happen, how they are interconnected, and many other related phenomena. To develop AI agents capable of addressing this natural human quest for causality, we urgently need a comprehensive dataset of natural causal questions. Unfortunately, existing datasets either contain only artificially-crafted questions that do not reflect real AI usage scenarios or have limited coverage of questions from specific sources. To address this gap, we present CausalQuest, a dataset of 13,500 naturally occurring questions sourced from social networks, search engines, and AI assistants. We formalize the definition of causal questions and establish a taxonomy for finer-grained classification. Through a combined effort of human annotators and large language models (LLMs), we carefully label the dataset. We find that 42% of the questions humans ask are indeed causal, with the majority seeking to understand the causes behind given effects. Using this dataset, we train efficient classifiers (up to 2.85B parameters) for the binary task of identifying causal questions, achieving high performance with F1 scores of up to 0.877. We conclude with a rich set of future research directions that can build upon our data and models.