 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling LLMs' Decomposition Abilities into Compact Language Models
Paper and Code

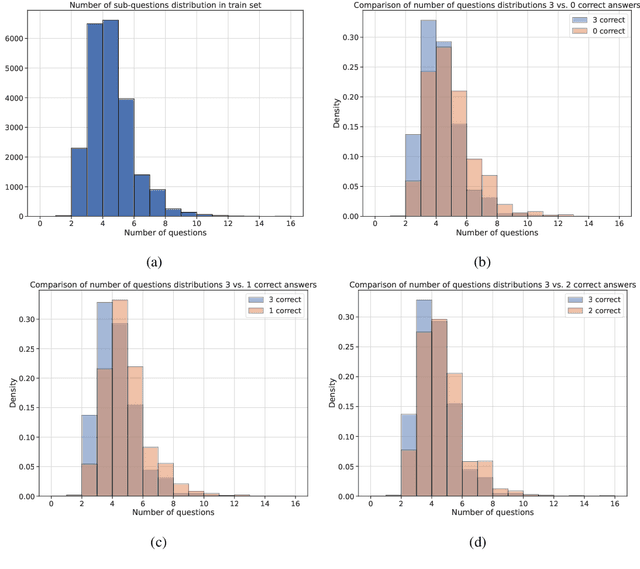
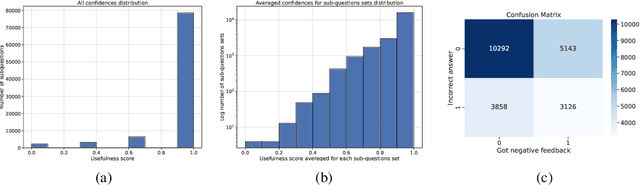
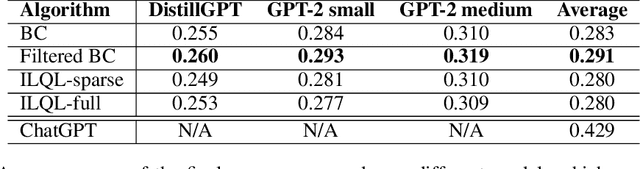
Large Language Models (LLMs) have demonstrated proficiency in their reasoning abilities, yet their large size presents scalability challenges and limits any further customization. In contrast, compact models offer customized training but often fall short in solving complex reasoning tasks. This study focuses on distilling the LLMs' decomposition skills into compact models using offline reinforcement learning. We leverage the advancements in the LLM`s capabilities to provide feedback and generate a specialized task-specific dataset for training compact models. The development of an AI-generated dataset and the establishment of baselines constitute the primary contributions of our work, underscoring the potential of compact models in replicating complex problem-solving skills.