 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe CAP Principle for LLM Serving
May 18, 2024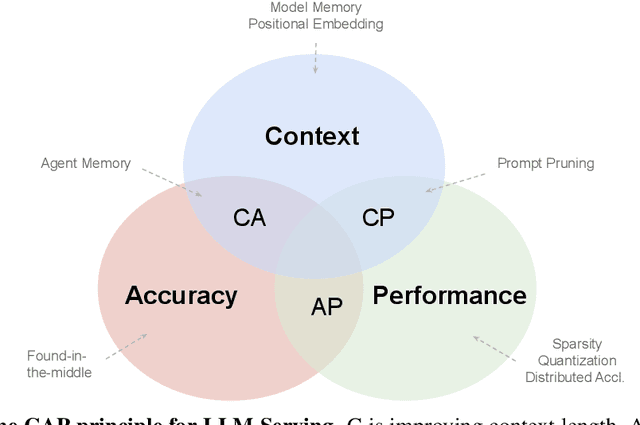

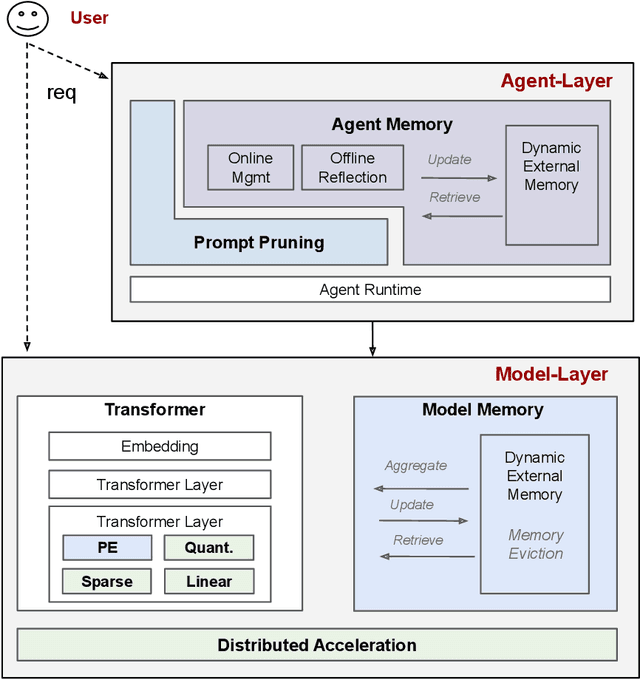
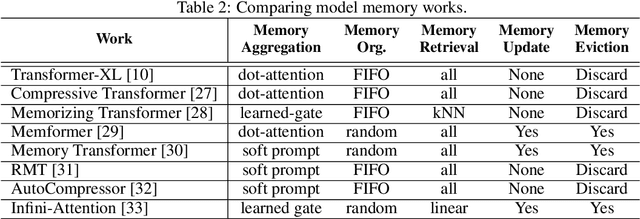
We survey the large language model (LLM) serving area to understand the intricate dynamics between cost-efficiency and accuracy, which is magnified by the growing need for longer contextual understanding when deploying models at a massive scale. Our findings reveal that works in this space optimize along three distinct but conflicting goals: improving serving context length (C), improving serving accuracy (A), and improving serving performance (P). Drawing inspiration from the CAP theorem in databases, we propose a CAP principle for LLM serving, which suggests that any optimization can improve at most two of these three goals simultaneously. Our survey categorizes existing works within this framework. We find the definition and continuity of user-perceived measurement metrics are crucial in determining whether a goal has been met, akin to prior CAP databases in the wild. We recognize the CAP principle for LLM serving as a guiding principle, rather than a formal theorem, to inform designers of the inherent and dynamic trade-offs in serving models. As serving accuracy and performance have been extensively studied, this survey focuses on works that extend serving context length and address the resulting challenges.