 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMCad: Fast and Scalable On-device Large Language Model Inference
Sep 08, 2023Generative tasks, such as text generation and question answering, hold a crucial position in the realm of mobile applications. Due to their sensitivity to privacy concerns, there is a growing demand for their execution directly on mobile devices. Currently, the execution of these generative tasks heavily depends on Large Language Models (LLMs). Nevertheless, the limited memory capacity of these devices presents a formidable challenge to the scalability of such models. In our research, we introduce LLMCad, an innovative on-device inference engine specifically designed for efficient generative Natural Language Processing (NLP) tasks. The core idea behind LLMCad revolves around model collaboration: a compact LLM, residing in memory, takes charge of generating the most straightforward tokens, while a high-precision LLM steps in to validate these tokens and rectify any identified errors. LLMCad incorporates three novel techniques: (1) Instead of generating candidate tokens in a sequential manner, LLMCad employs the smaller LLM to construct a token tree, encompassing a wider range of plausible token pathways. Subsequently, the larger LLM can efficiently validate all of these pathways simultaneously. (2) It employs a self-adjusting fallback strategy, swiftly initiating the verification process whenever the smaller LLM generates an erroneous token. (3) To ensure a continuous flow of token generation, LLMCad speculatively generates tokens during the verification process by implementing a compute-IO pipeline. Through an extensive series of experiments, LLMCad showcases an impressive token generation speed, achieving rates up to 9.3x faster than existing inference engines.
EdgeMoE: Fast On-Device Inference of MoE-based Large Language Models
Aug 28, 2023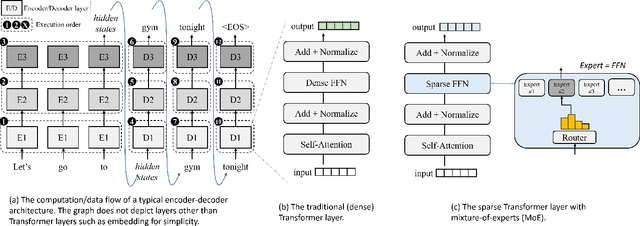
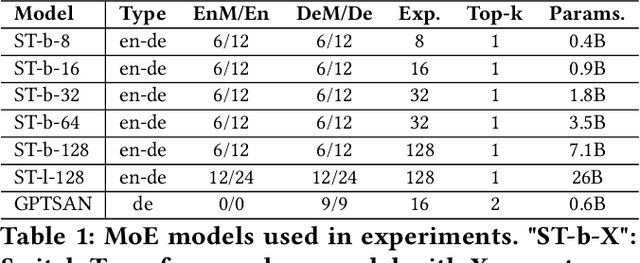
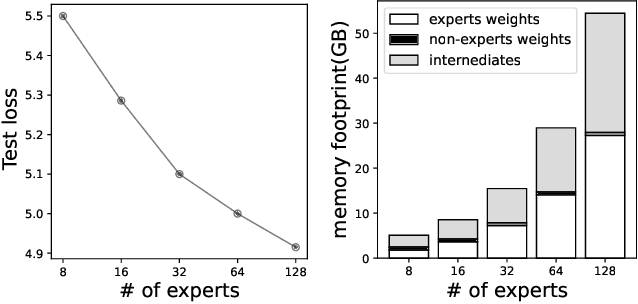

Large Language Models (LLMs) such as GPTs and LLaMa have ushered in a revolution in machine intelligence, owing to their exceptional capabilities in a wide range of machine learning tasks. However, the transition of LLMs from data centers to edge devices presents a set of challenges and opportunities. While this shift can enhance privacy and availability, it is hampered by the enormous parameter sizes of these models, leading to impractical runtime costs. In light of these considerations, we introduce EdgeMoE, the first on-device inference engine tailored for mixture-of-expert (MoE) LLMs, a popular variant of sparse LLMs that exhibit nearly constant computational complexity as their parameter size scales. EdgeMoE achieves both memory and computational efficiency by strategically partitioning the model across the storage hierarchy. Specifically, non-expert weights are stored in the device's memory, while expert weights are kept in external storage and are fetched into memory only when they are activated. This design is underpinned by a crucial insight that expert weights, though voluminous, are infrequently accessed due to sparse activation patterns. To further mitigate the overhead associated with expert I/O swapping, EdgeMoE incorporates two innovative techniques: (1) Expert-wise bitwidth adaptation: This method reduces the size of expert weights with an acceptable level of accuracy loss. (2) Expert management: It predicts the experts that will be activated in advance and preloads them into the compute-I/O pipeline, thus further optimizing the process. In empirical evaluations conducted on well-established MoE LLMs and various edge devices, EdgeMoE demonstrates substantial memory savings and performance improvements when compared to competitive baseline solutions.