 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"BNN - BN = ?": Training Binary Neural Networks without Batch Normalization
Paper and Code
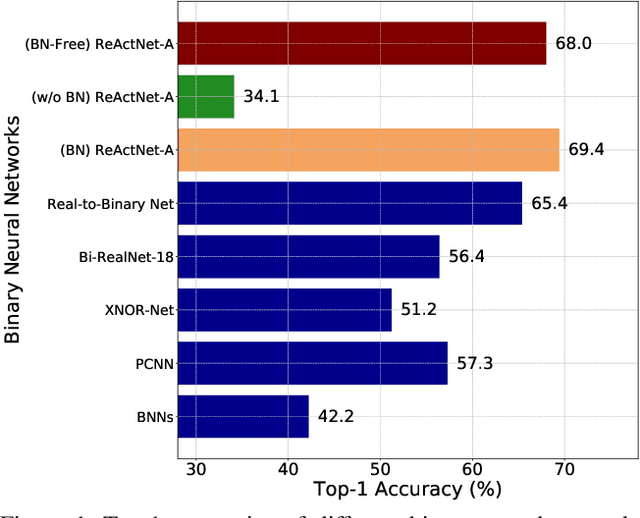

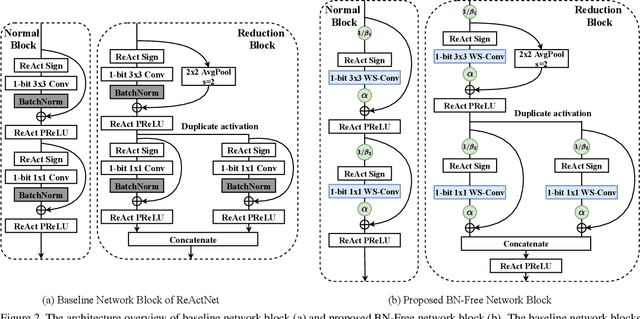

Batch normalization (BN) is a key facilitator and considered essential for state-of-the-art binary neural networks (BNN). However, the BN layer is costly to calculate and is typically implemented with non-binary parameters, leaving a hurdle for the efficient implementation of BNN training. It also introduces undesirable dependence between samples within each batch. Inspired by the latest advance on Batch Normalization Free (BN-Free) training, we extend their framework to training BNNs, and for the first time demonstrate that BNs can be completed removed from BNN training and inference regimes. By plugging in and customizing techniques including adaptive gradient clipping, scale weight standardization, and specialized bottleneck block, a BN-free BNN is capable of maintaining competitive accuracy compared to its BN-based counterpart. Extensive experiments validate the effectiveness of our proposal across diverse BNN backbones and datasets. For example, after removing BNs from the state-of-the-art ReActNets, it can still be trained with our proposed methodology to achieve 92.08%, 68.34%, and 68.0% accuracy on CIFAR-10, CIFAR-100, and ImageNet respectively, with marginal performance drop (0.23%~0.44% on CIFAR and 1.40% on ImageNet). Codes and pre-trained models are available at: https://github.com/VITA-Group/BNN_NoBN.