 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGated Rotary-Enhanced Linear Attention for Long-term Sequential Recommendation
Jun 16, 2025In Sequential Recommendation Systems (SRSs), Transformer models show remarkable performance but face computation cost challenges when modeling long-term user behavior sequences due to the quadratic complexity of the dot-product attention mechanism. By approximating the dot-product attention, linear attention provides an efficient option with linear complexity. However, existing linear attention methods face two limitations: 1) they often use learnable position encodings, which incur extra computational costs in long-term sequence scenarios, and 2) they may not consider the user's fine-grained local preferences and confuse these with the actual change of long-term interests. To remedy these drawbacks, we propose a long-term sequential Recommendation model with Gated Rotary Enhanced Linear Attention (RecGRELA). Specifically, we first propose a Rotary-Enhanced Linear Attention (RELA) module to model long-range dependency within the user's historical information using rotary position encodings. We then introduce a local short operation to incorporate local preferences and demonstrate the theoretical insight. We further introduce a SiLU-based Gated mechanism for RELA (GRELA) to help the model determine whether a user's behavior indicates local interest or a genuine shift in long-term preferences. Experimental results on four public datasets demonstrate that our RecGRELA achieves state-of-the-art performance compared to existing SRSs while maintaining low memory overhead.
EMMA: Your Text-to-Image Diffusion Model Can Secretly Accept Multi-Modal Prompts
Jun 13, 2024Recent advancements in image generation have enabled the creation of high-quality images from text conditions. However, when facing multi-modal conditions, such as text combined with reference appearances, existing methods struggle to balance multiple conditions effectively, typically showing a preference for one modality over others. To address this challenge, we introduce EMMA, a novel image generation model accepting multi-modal prompts built upon the state-of-the-art text-to-image (T2I) diffusion model, ELLA. EMMA seamlessly incorporates additional modalities alongside text to guide image generation through an innovative Multi-modal Feature Connector design, which effectively integrates textual and supplementary modal information using a special attention mechanism. By freezing all parameters in the original T2I diffusion model and only adjusting some additional layers, we reveal an interesting finding that the pre-trained T2I diffusion model can secretly accept multi-modal prompts. This interesting property facilitates easy adaptation to different existing frameworks, making EMMA a flexible and effective tool for producing personalized and context-aware images and even videos. Additionally, we introduce a strategy to assemble learned EMMA modules to produce images conditioned on multiple modalities simultaneously, eliminating the need for additional training with mixed multi-modal prompts. Extensive experiments demonstrate the effectiveness of EMMA in maintaining high fidelity and detail in generated images, showcasing its potential as a robust solution for advanced multi-modal conditional image generation tasks.
You Only Need Half: Boosting Data Augmentation by Using Partial Content
May 05, 2024



We propose a novel data augmentation method termed You Only Need hAlf (YONA), which simplifies the augmentation process. YONA bisects an image, substitutes one half with noise, and applies data augmentation techniques to the remaining half. This method reduces the redundant information in the original image, encourages neural networks to recognize objects from incomplete views, and significantly enhances neural networks' robustness. YONA is distinguished by its properties of parameter-free, straightforward application, enhancing various existing data augmentation strategies, and thereby bolstering neural networks' robustness without additional computational cost. To demonstrate YONA's efficacy, extensive experiments were carried out. These experiments confirm YONA's compatibility with diverse data augmentation methods and neural network architectures, yielding substantial improvements in CIFAR classification tasks, sometimes outperforming conventional image-level data augmentation methods. Furthermore, YONA markedly increases the resilience of neural networks to adversarial attacks. Additional experiments exploring YONA's variants conclusively show that masking half of an image optimizes performance. The code is available at https://github.com/HansMoe/YONA.
Regularized Conditional Alignment for Multi-Domain Text Classification
Dec 18, 2023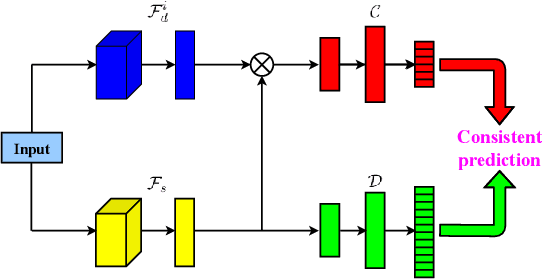
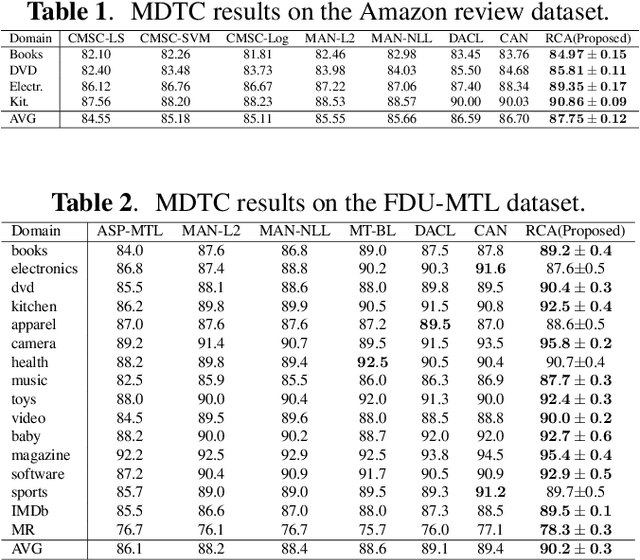
The most successful multi-domain text classification (MDTC) approaches employ the shared-private paradigm to facilitate the enhancement of domain-invariant features through domain-specific attributes. Additionally, they employ adversarial training to align marginal feature distributions. Nevertheless, these methodologies encounter two primary challenges: (1) Neglecting class-aware information during adversarial alignment poses a risk of misalignment; (2) The limited availability of labeled data across multiple domains fails to ensure adequate discriminative capacity for the model. To tackle these issues, we propose a method called Regularized Conditional Alignment (RCA) to align the joint distributions of domains and classes, thus matching features within the same category and amplifying the discriminative qualities of acquired features. Moreover, we employ entropy minimization and virtual adversarial training to constrain the uncertainty of predictions pertaining to unlabeled data and enhance the model's robustness. Empirical results on two benchmark datasets demonstrate that our RCA approach outperforms state-of-the-art MDTC techniques.