 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillJect: Automating Stealthy Skill-Based Prompt Injection for Coding Agents with Trace-Driven Closed-Loop Refinement
Feb 15, 2026Agent skills are becoming a core abstraction in coding agents, packaging long-form instructions and auxiliary scripts to extend tool-augmented behaviors. This abstraction introduces an under-measured attack surface: skill-based prompt injection, where poisoned skills can steer agents away from user intent and safety policies. In practice, naive injections often fail because the malicious intent is too explicit or drifts too far from the original skill, leading agents to ignore or refuse them; existing attacks are also largely hand-crafted. We propose the first automated framework for stealthy prompt injection tailored to agent skills. The framework forms a closed loop with three agents: an Attack Agent that synthesizes injection skills under explicit stealth constraints, a Code Agent that executes tasks using the injected skills in a realistic tool environment, and an Evaluate Agent that logs action traces (e.g., tool calls and file operations) and verifies whether targeted malicious behaviors occurred. We also propose a malicious payload hiding strategy that conceals adversarial operations in auxiliary scripts while injecting optimized inducement prompts to trigger tool execution. Extensive experiments across diverse coding-agent settings and real-world software engineering tasks show that our method consistently achieves high attack success rates under realistic settings.
Gated Rotary-Enhanced Linear Attention for Long-term Sequential Recommendation
Jun 16, 2025In Sequential Recommendation Systems (SRSs), Transformer models show remarkable performance but face computation cost challenges when modeling long-term user behavior sequences due to the quadratic complexity of the dot-product attention mechanism. By approximating the dot-product attention, linear attention provides an efficient option with linear complexity. However, existing linear attention methods face two limitations: 1) they often use learnable position encodings, which incur extra computational costs in long-term sequence scenarios, and 2) they may not consider the user's fine-grained local preferences and confuse these with the actual change of long-term interests. To remedy these drawbacks, we propose a long-term sequential Recommendation model with Gated Rotary Enhanced Linear Attention (RecGRELA). Specifically, we first propose a Rotary-Enhanced Linear Attention (RELA) module to model long-range dependency within the user's historical information using rotary position encodings. We then introduce a local short operation to incorporate local preferences and demonstrate the theoretical insight. We further introduce a SiLU-based Gated mechanism for RELA (GRELA) to help the model determine whether a user's behavior indicates local interest or a genuine shift in long-term preferences. Experimental results on four public datasets demonstrate that our RecGRELA achieves state-of-the-art performance compared to existing SRSs while maintaining low memory overhead.
SAILOR: Structural Augmentation Based Tail Node Representation Learning
Aug 15, 2023Graph Neural Networks (GNNs) have achieved state-of-the-art performance in representation learning for graphs recently. However, the effectiveness of GNNs, which capitalize on the key operation of message propagation, highly depends on the quality of the topology structure. Most of the graphs in real-world scenarios follow a long-tailed distribution on their node degrees, that is, a vast majority of the nodes in the graph are tail nodes with only a few connected edges. GNNs produce inferior node representations for tail nodes since they lack structural information. In the pursuit of promoting the expressiveness of GNNs for tail nodes, we explore how the deficiency of structural information deteriorates the performance of tail nodes and propose a general Structural Augmentation based taIL nOde Representation learning framework, dubbed as SAILOR, which can jointly learn to augment the graph structure and extract more informative representations for tail nodes. Extensive experiments on public benchmark datasets demonstrate that SAILOR can significantly improve the tail node representations and outperform the state-of-the-art baselines.
GUARD: Graph Universal Adversarial Defense
Apr 20, 2022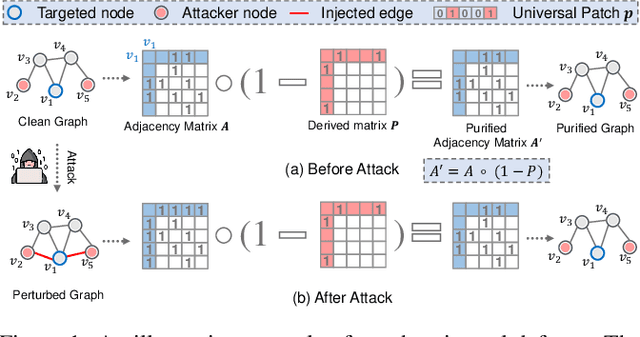

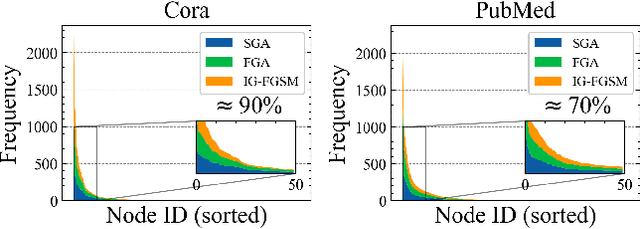
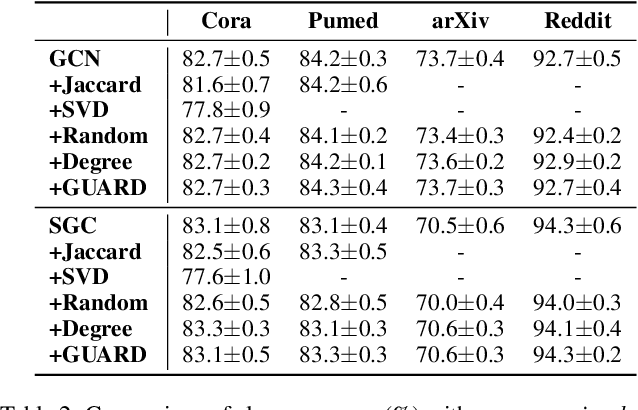
Recently, graph convolutional networks (GCNs) have shown to be vulnerable to small adversarial perturbations, which becomes a severe threat and largely limits their applications in security-critical scenarios. To mitigate such a threat, considerable research efforts have been devoted to increasing the robustness of GCNs against adversarial attacks. However, current approaches for defense are typically designed for the whole graph and consider the global performance, posing challenges in protecting important local nodes from stronger adversarial targeted attacks. In this work, we present a simple yet effective method, named \textbf{\underline{G}}raph \textbf{\underline{U}}niversal \textbf{\underline{A}}dve\textbf{\underline{R}}sarial \textbf{\underline{D}}efense (GUARD). Unlike previous works, GUARD protects each individual node from attacks with a universal defensive patch, which is generated once and can be applied to any node (node-agnostic) in a graph. Extensive experiments on four benchmark datasets demonstrate that our method significantly improves robustness for several established GCNs against multiple adversarial attacks and outperforms existing adversarial defense methods by large margins. Our code is publicly available at https://github.com/EdisonLeeeee/GUARD.
2nd Place Solution for Waymo Open Dataset Challenge -- 2D Object Detection
Jun 28, 2020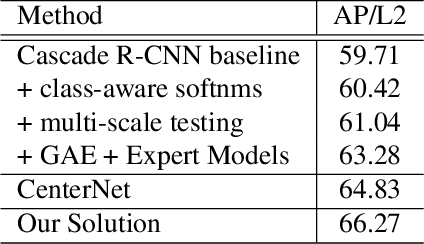
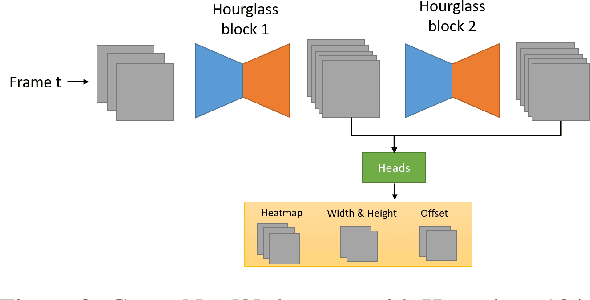
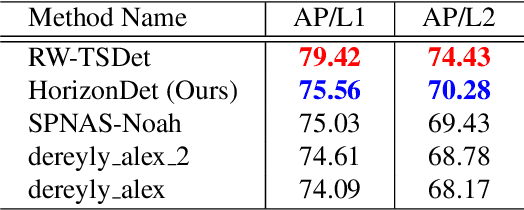
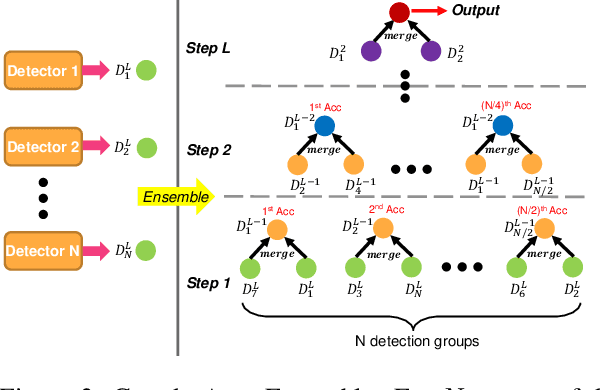
A practical autonomous driving system urges the need to reliably and accurately detect vehicles and persons. In this report, we introduce a state-of-the-art 2D object detection system for autonomous driving scenarios. Specifically, we integrate both popular two-stage detector and one-stage detector with anchor free fashion to yield a robust detection. Furthermore, we train multiple expert models and design a greedy version of the auto ensemble scheme that automatically merges detections from different models. Notably, our overall detection system achieves 70.28 L2 mAP on the Waymo Open Dataset v1.2, ranking the 2nd place in the 2D detection track of the Waymo Open Dataset Challenges.
1st Place Solutions for Waymo Open Dataset Challenges - 2D and 3D Tracking
Jun 28, 2020
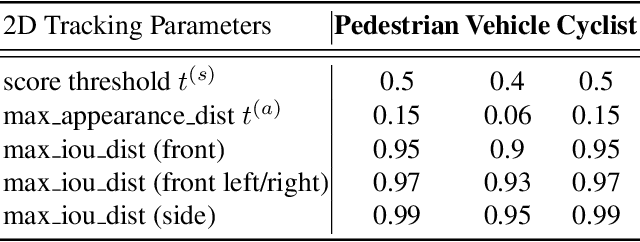
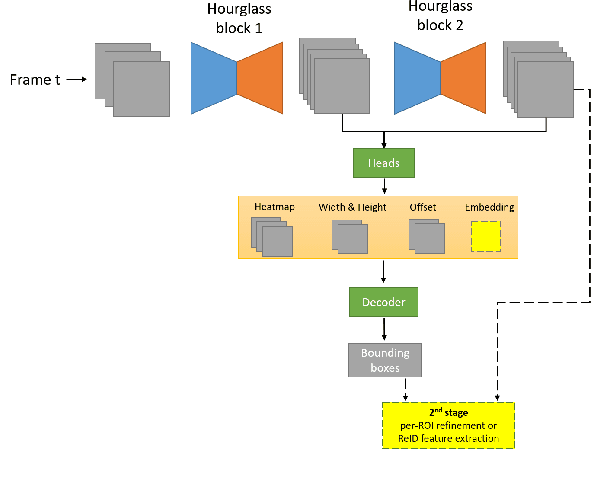
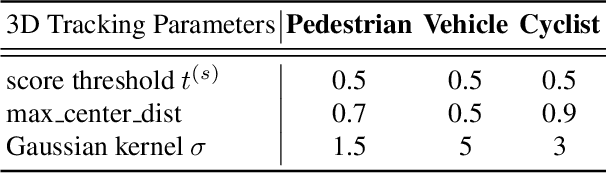
This technical report presents the online and real-time 2D and 3D multi-object tracking (MOT) algorithms that reached the 1st places on both Waymo Open Dataset 2D tracking and 3D tracking challenges. An efficient and pragmatic online tracking-by-detection framework named HorizonMOT is proposed for camera-based 2D tracking in the image space and LiDAR-based 3D tracking in the 3D world space. Within the tracking-by-detection paradigm, our trackers leverage our high-performing detectors used in the 2D/3D detection challenges and achieved 45.13% 2D MOTA/L2 and 63.45% 3D MOTA/L2 in the 2D/3D tracking challenges.
1st Place Solution for Waymo Open Dataset Challenge - 3D Detection and Domain Adaptation
Jun 28, 2020
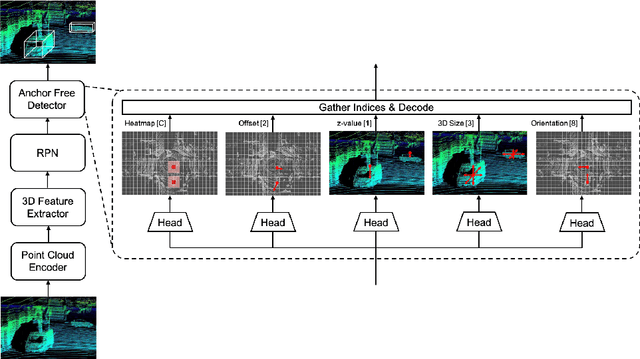
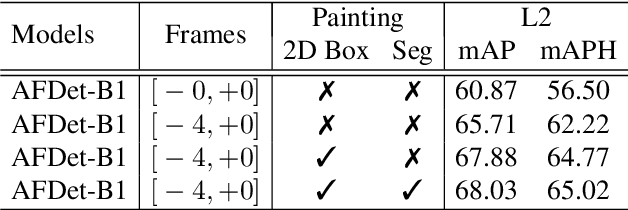
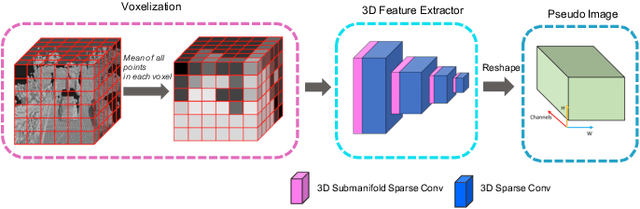
In this technical report, we introduce our winning solution "HorizonLiDAR3D" for the 3D detection track and the domain adaptation track in Waymo Open Dataset Challenge at CVPR 2020. Many existing 3D object detectors include prior-based anchor box design to account for different scales and aspect ratios and classes of objects, which limits its capability of generalization to a different dataset or domain and requires post-processing (e.g. Non-Maximum Suppression (NMS)). We proposed a one-stage, anchor-free and NMS-free 3D point cloud object detector AFDet, using object key-points to encode the 3D attributes, and to learn an end-to-end point cloud object detection without the need of hand-engineering or learning the anchors. AFDet serves as a strong baseline in our winning solution and significant improvements are made over this baseline during the challenges. Specifically, we design stronger networks and enhance the point cloud data using densification and point painting. To leverage camera information, we append/paint additional attributes to each point by projecting them to camera space and gathering image-based perception information. The final detection performance also benefits from model ensemble and Test-Time Augmentation (TTA) in both the 3D detection track and the domain adaptation track. Our solution achieves the 1st place with 77.11% mAPH/L2 and 69.49% mAPH/L2 respectively on the 3D detection track and the domain adaptation track.