 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-Foresight: A Joint Vision-Action Causal Forecasting Network via Predictive World Modeling
May 24, 2026Physical world knowledge resides mainly in videos. Equipping Vision-Language-Action (VLA) models with such knowledge is fundamental for safe and generalizable planning. Predictive world modeling enables VLA to internalize physical dynamics and long-term causality by predicting future video from past observations. However, naive next-frame prediction faces two challenges: 1) unlike semantically distinct text tokens, video tokens are low-entropy and redundant, causing prediction to degenerate into trivial extrapolation. 2) world modeling poses a temporal dilemma: dense prediction captures instantaneous dynamics, but cannot efficiently model long-horizon causality. To learn world knowledge effectively, we introduce X-Foresight, a predictive world model integrated directly into the VLA architecture to jointly learn world modeling and real-time action control. At its core lies a long-horizon chunk-wise auto-regressive strategy that addresses both challenges: by predicting semantically distant chunks rather than adjacent frames, it escapes trivial extrapolation, while preserving dense intra-chunk frames for instantaneous dynamics and sparse inter-chunk transitions for long-term causality. A curriculum learning schedule progressively extends prediction horizons and stabilizes long-horizon training. To capture long-term causality effectively, we present temporal importance sampling, which concentrates supervision on safety-critical chunks identified by ego-motion and behavioral signals. We further delegate photorealistic synthesis to a diffusion-based multi-view renderer, improving photorealistic appearance. Comprehensive experiments demonstrate that X-Foresight significantly outperforms VLA baselines in planning performance while maintaining strong generative fidelity, establishing a robust paradigm for world-knowledge-driven autonomous systems.
Imitation with Spatial-Temporal Heatmap: 2nd Place Solution for NuPlan Challenge
Jun 26, 2023This paper presents our 2nd place solution for the NuPlan Challenge 2023. Autonomous driving in real-world scenarios is highly complex and uncertain. Achieving safe planning in the complex multimodal scenarios is a highly challenging task. Our approach, Imitation with Spatial-Temporal Heatmap, adopts the learning form of behavior cloning, innovatively predicts the future multimodal states with a heatmap representation, and uses trajectory refinement techniques to ensure final safety. The experiment shows that our method effectively balances the vehicle's progress and safety, generating safe and comfortable trajectories. In the NuPlan competition, we achieved the second highest overall score, while obtained the best scores in the ego progress and comfort metrics.
AFDetV2: Rethinking the Necessity of the Second Stage for Object Detection from Point Clouds
Dec 16, 2021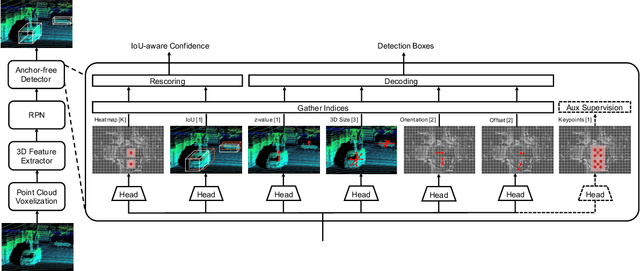

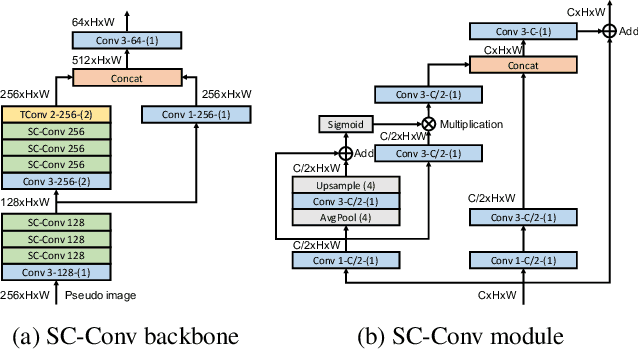
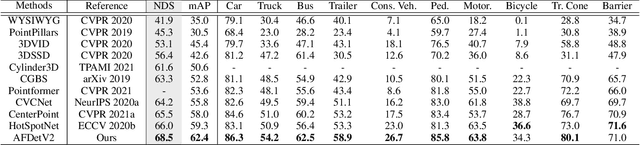
There have been two streams in the 3D detection from point clouds: single-stage methods and two-stage methods. While the former is more computationally efficient, the latter usually provides better detection accuracy. By carefully examining the two-stage approaches, we have found that if appropriately designed, the first stage can produce accurate box regression. In this scenario, the second stage mainly rescores the boxes such that the boxes with better localization get selected. From this observation, we have devised a single-stage anchor-free network that can fulfill these requirements. This network, named AFDetV2, extends the previous work by incorporating a self-calibrated convolution block in the backbone, a keypoint auxiliary supervision, and an IoU prediction branch in the multi-task head. As a result, the detection accuracy is drastically boosted in the single-stage. To evaluate our approach, we have conducted extensive experiments on the Waymo Open Dataset and the nuScenes Dataset. We have observed that our AFDetV2 achieves the state-of-the-art results on these two datasets, superior to all the prior arts, including both the single-stage and the two-stage se3D detectors. AFDetV2 won the 1st place in the Real-Time 3D Detection of the Waymo Open Dataset Challenge 2021. In addition, a variant of our model AFDetV2-Base was entitled the "Most Efficient Model" by the Challenge Sponsor, showing a superior computational efficiency. To demonstrate the generality of this single-stage method, we have also applied it to the first stage of the two-stage networks. Without exception, the results show that with the strengthened backbone and the rescoring approach, the second stage refinement is no longer needed.
Real-Time Anchor-Free Single-Stage 3D Detection with IoU-Awareness
Aug 03, 2021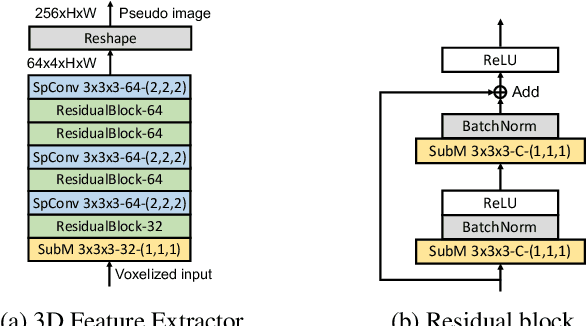
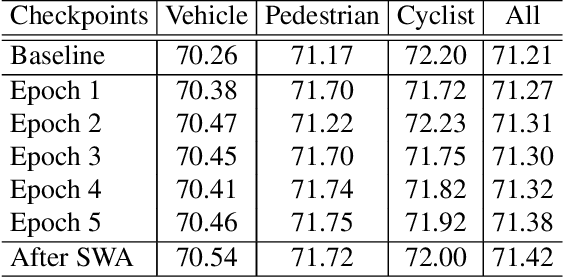
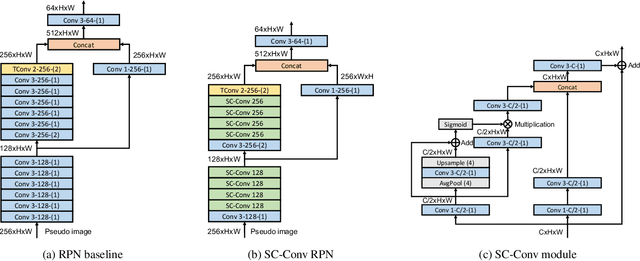
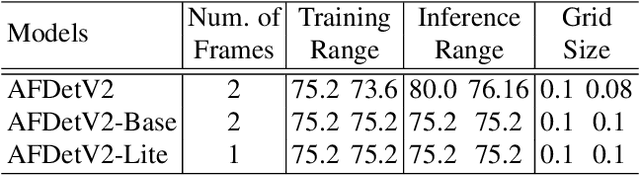
In this report, we introduce our winning solution to the Real-time 3D Detection and also the "Most Efficient Model" in the Waymo Open Dataset Challenges at CVPR 2021. Extended from our last year's award-winning model AFDet, we have made a handful of modifications to the base model, to improve the accuracy and at the same time to greatly reduce the latency. The modified model, named as AFDetV2, is featured with a lite 3D Feature Extractor, an improved RPN with extended receptive field and an added sub-head that produces an IoU-aware confidence score. These model enhancements, together with enriched data augmentation, stochastic weights averaging, and a GPU-based implementation of voxelization, lead to a winning accuracy of 73.12 mAPH/L2 for our AFDetV2 with a latency of 60.06 ms, and an accuracy of 72.57 mAPH/L2 for our AFDetV2-base, entitled as the "Most Efficient Model" by the challenge sponsor, with a winning latency of 55.86 ms.
AFDet: Anchor Free One Stage 3D Object Detection
Jun 30, 2020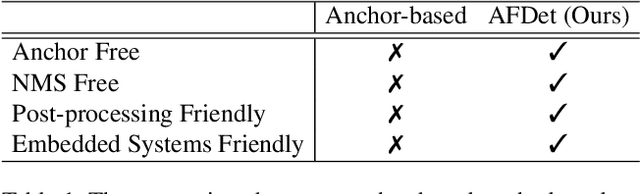
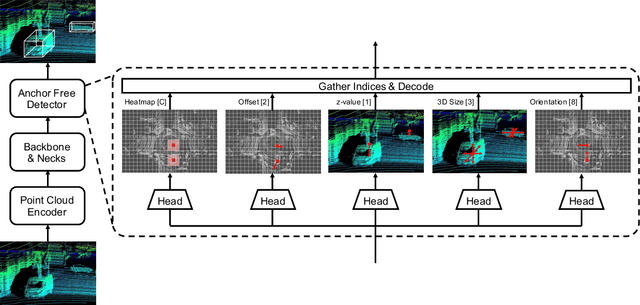
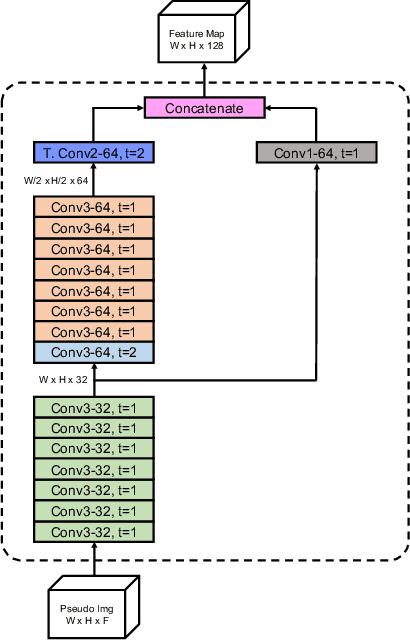
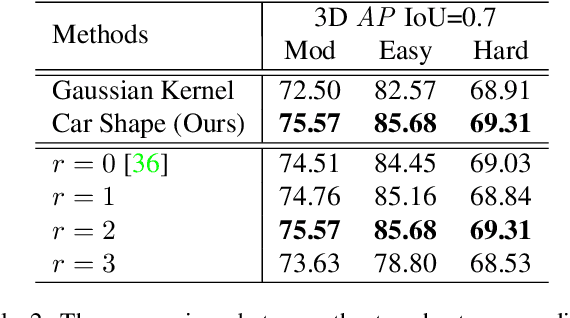
High-efficiency point cloud 3D object detection operated on embedded systems is important for many robotics applications including autonomous driving. Most previous works try to solve it using anchor-based detection methods which come with two drawbacks: post-processing is relatively complex and computationally expensive; tuning anchor parameters is tricky. We are the first to address these drawbacks with an anchor free and Non-Maximum Suppression free one stage detector called AFDet. The entire AFDet can be processed efficiently on a CNN accelerator or a GPU with the simplified post-processing. Without bells and whistles, our proposed AFDet performs competitively with other one stage anchor-based methods on KITTI validation set and Waymo Open Dataset validation set.
2nd Place Solution for Waymo Open Dataset Challenge -- 2D Object Detection
Jun 28, 2020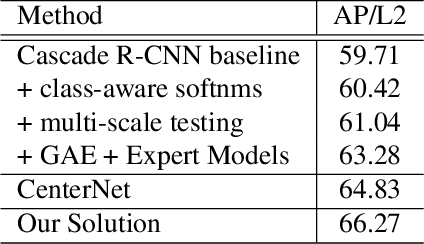
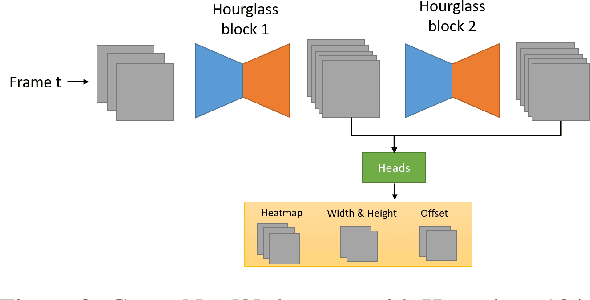
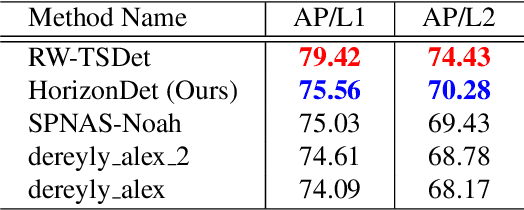
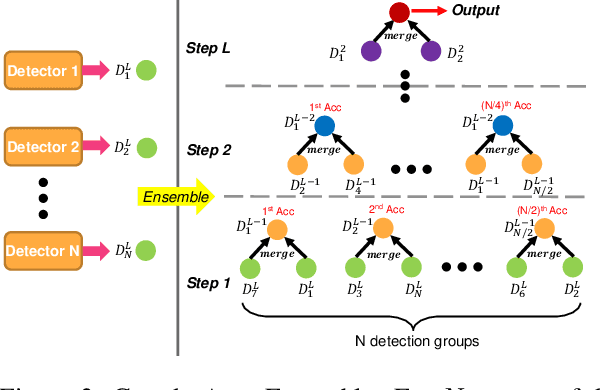
A practical autonomous driving system urges the need to reliably and accurately detect vehicles and persons. In this report, we introduce a state-of-the-art 2D object detection system for autonomous driving scenarios. Specifically, we integrate both popular two-stage detector and one-stage detector with anchor free fashion to yield a robust detection. Furthermore, we train multiple expert models and design a greedy version of the auto ensemble scheme that automatically merges detections from different models. Notably, our overall detection system achieves 70.28 L2 mAP on the Waymo Open Dataset v1.2, ranking the 2nd place in the 2D detection track of the Waymo Open Dataset Challenges.
1st Place Solutions for Waymo Open Dataset Challenges - 2D and 3D Tracking
Jun 28, 2020
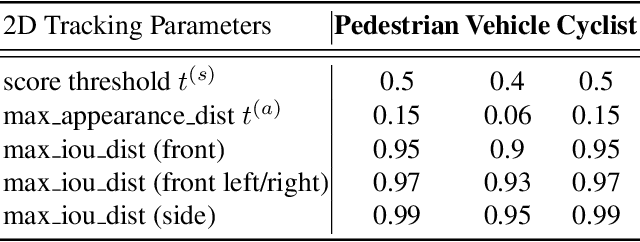
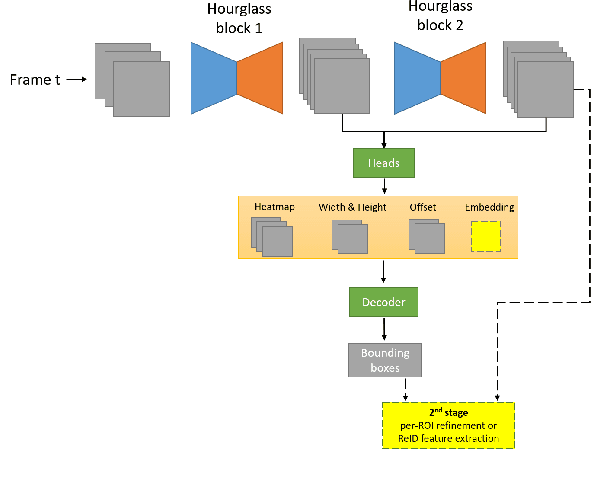
This technical report presents the online and real-time 2D and 3D multi-object tracking (MOT) algorithms that reached the 1st places on both Waymo Open Dataset 2D tracking and 3D tracking challenges. An efficient and pragmatic online tracking-by-detection framework named HorizonMOT is proposed for camera-based 2D tracking in the image space and LiDAR-based 3D tracking in the 3D world space. Within the tracking-by-detection paradigm, our trackers leverage our high-performing detectors used in the 2D/3D detection challenges and achieved 45.13% 2D MOTA/L2 and 63.45% 3D MOTA/L2 in the 2D/3D tracking challenges.
1st Place Solution for Waymo Open Dataset Challenge - 3D Detection and Domain Adaptation
Jun 28, 2020
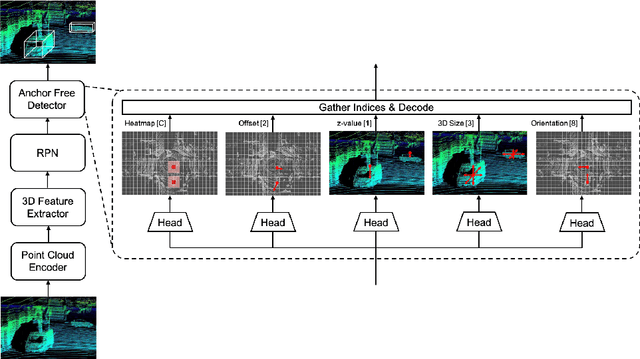
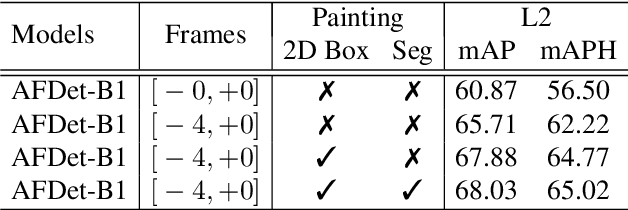
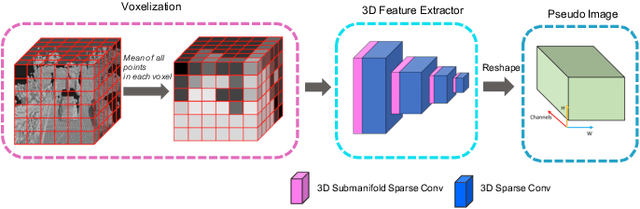
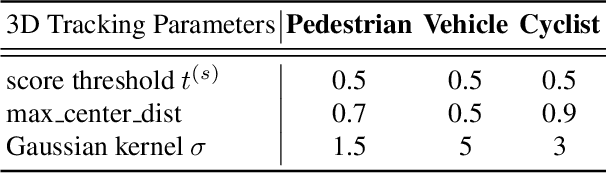
In this technical report, we introduce our winning solution "HorizonLiDAR3D" for the 3D detection track and the domain adaptation track in Waymo Open Dataset Challenge at CVPR 2020. Many existing 3D object detectors include prior-based anchor box design to account for different scales and aspect ratios and classes of objects, which limits its capability of generalization to a different dataset or domain and requires post-processing (e.g. Non-Maximum Suppression (NMS)). We proposed a one-stage, anchor-free and NMS-free 3D point cloud object detector AFDet, using object key-points to encode the 3D attributes, and to learn an end-to-end point cloud object detection without the need of hand-engineering or learning the anchors. AFDet serves as a strong baseline in our winning solution and significant improvements are made over this baseline during the challenges. Specifically, we design stronger networks and enhance the point cloud data using densification and point painting. To leverage camera information, we append/paint additional attributes to each point by projecting them to camera space and gathering image-based perception information. The final detection performance also benefits from model ensemble and Test-Time Augmentation (TTA) in both the 3D detection track and the domain adaptation track. Our solution achieves the 1st place with 77.11% mAPH/L2 and 69.49% mAPH/L2 respectively on the 3D detection track and the domain adaptation track.