 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiC: A Phrase-in-Context Dataset for Phrase Understanding and Semantic Search
Paper and Code
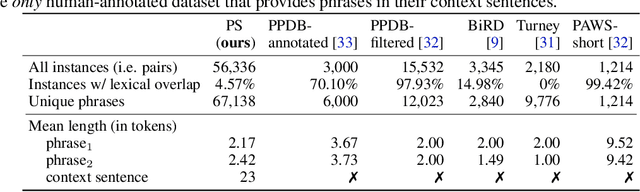

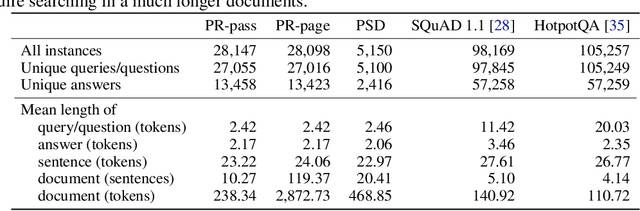

Since BERT (Devlin et al., 2018), learning contextualized word embeddings has been a de-facto standard in NLP. However, the progress of learning contextualized phrase embeddings is hindered by the lack of a human-annotated, phrase-in-context benchmark. To fill this gap, we propose PiC - a dataset of ~28K of noun phrases accompanied by their contextual Wikipedia pages and a suite of three tasks of increasing difficulty for evaluating the quality of phrase embeddings. We find that training on our dataset improves ranking models' accuracy and remarkably pushes Question Answering (QA) models to near-human accuracy which is 95% Exact Match (EM) on semantic search given a query phrase and a passage. Interestingly, we find evidence that such impressive performance is because the QA models learn to better capture the common meaning of a phrase regardless of its actual context. That is, on our Phrase Sense Disambiguation (PSD) task, SotA model accuracy drops substantially (60% EM), failing to differentiate between two different senses of the same phrase under two different contexts. Further results on our 3-task PiC benchmark reveal that learning contextualized phrase embeddings remains an interesting, open challenge.