Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble Trouble: How to not explain a text classifier's decisions using counterfactuals synthesized by masked language models?
Paper and Code
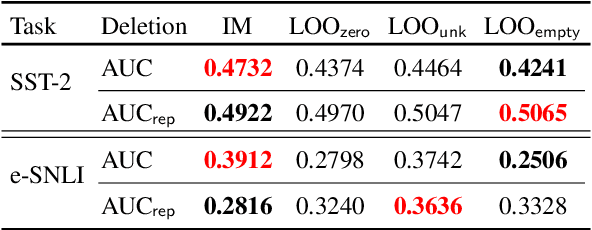
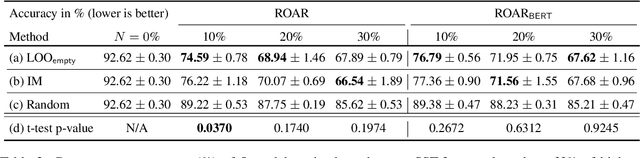

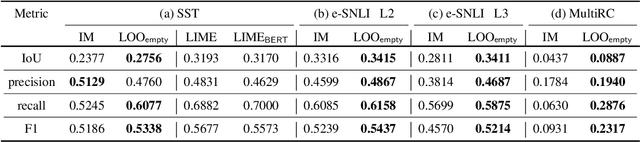
Explaining how important each input feature is to a classifier's decision is critical in high-stake applications. An underlying principle behind dozens of explanation methods is to take the prediction difference between before-and-after an input feature (here, a token) is removed as its attribution - the individual treatment effect in causal inference. A recent method called Input Marginalization (IM) (Kim et al., 2020) uses BERT to replace a token - i.e. simulating the do(.) operator - yielding more plausible counterfactuals. However, our rigorous evaluation using five metrics and on three datasets found IM explanations to be consistently more biased, less accurate, and less plausible than those derived from simply deleting a word.
* 9+8 pages, 4+12 figures
View paper on