 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut of Order: How important is the sequential order of words in a sentence in Natural Language Understanding tasks?
Paper and Code
Dec 30, 2020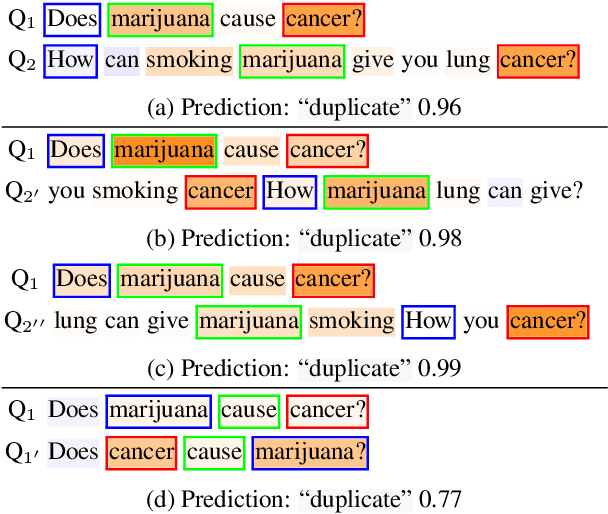

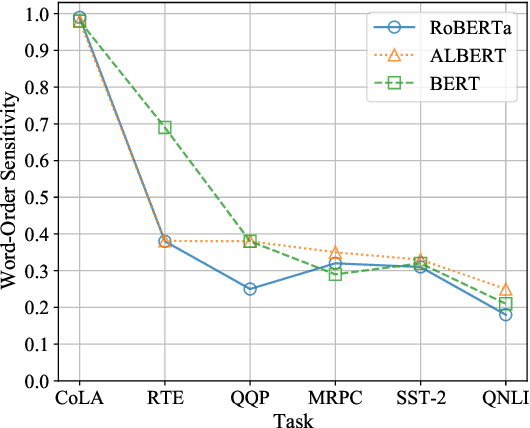
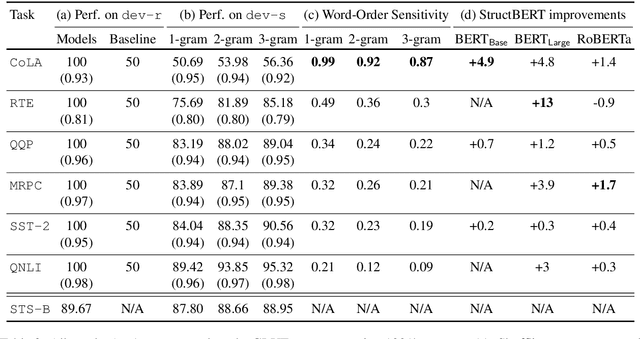
Do state-of-the-art natural language understanding models care about word order - one of the most important characteristics of a sequence? Not always! We found 75% to 90% of the correct predictions of BERT-based classifiers, trained on many GLUE tasks, remain constant after input words are randomly shuffled. Despite BERT embeddings are famously contextual, the contribution of each individual word to downstream tasks is almost unchanged even after the word's context is shuffled. BERT-based models are able to exploit superficial cues (e.g. the sentiment of keywords in sentiment analysis; or the word-wise similarity between sequence-pair inputs in natural language inference) to make correct decisions when tokens are arranged in random orders. Encouraging classifiers to capture word order information improves the performance on most GLUE tasks, SQuAD 2.0 and out-of-samples. Our work suggests that many GLUE tasks are not challenging machines to understand the meaning of a sentence.