 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERTQA -- Attention on Steroids
Paper and Code
Dec 14, 2019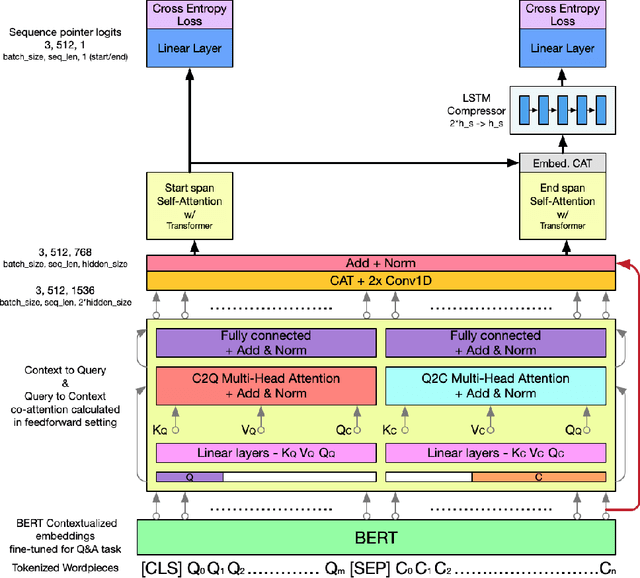
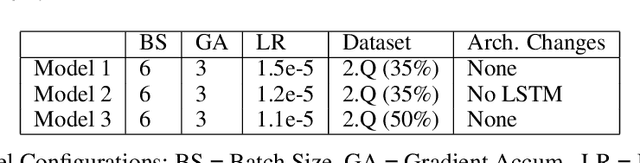
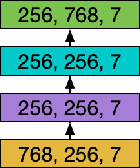
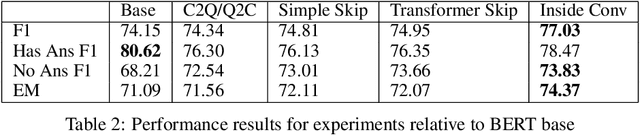
In this work, we extend the Bidirectional Encoder Representations from Transformers (BERT) with an emphasis on directed coattention to obtain an improved F1 performance on the SQUAD2.0 dataset. The Transformer architecture on which BERT is based places hierarchical global attention on the concatenation of the context and query. Our additions to the BERT architecture augment this attention with a more focused context to query (C2Q) and query to context (Q2C) attention via a set of modified Transformer encoder units. In addition, we explore adding convolution-based feature extraction within the coattention architecture to add localized information to self-attention. We found that coattention significantly improves the no answer F1 by 4 points in the base and 1 point in the large architecture. After adding skip connections the no answer F1 improved further without causing an additional loss in has answer F1. The addition of localized feature extraction added to attention produced an overall dev F1 of 77.03 in the base architecture. We applied our findings to the large BERT model which contains twice as many layers and further used our own augmented version of the SQUAD 2.0 dataset created by back translation, which we have named SQUAD 2.Q. Finally, we performed hyperparameter tuning and ensembled our best models for a final F1/EM of 82.317/79.442 (Attention on Steroids, PCE Test Leaderboard).