 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforced Self-Attention Masks for Abstractive Summarization (DR.SAS)
Paper and Code
Dec 30, 2019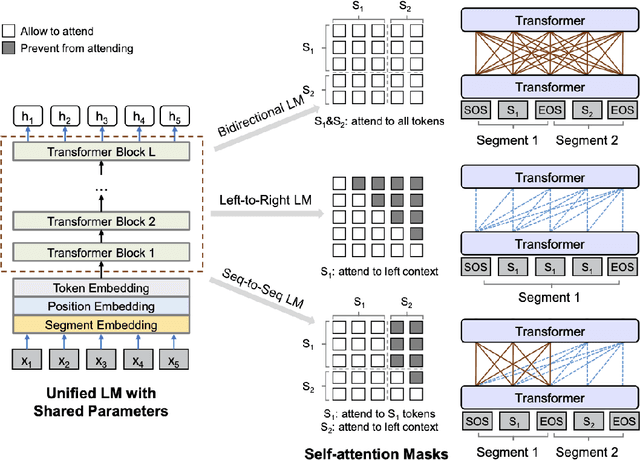
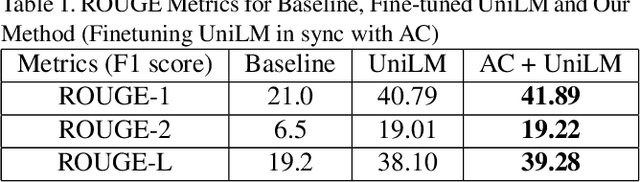

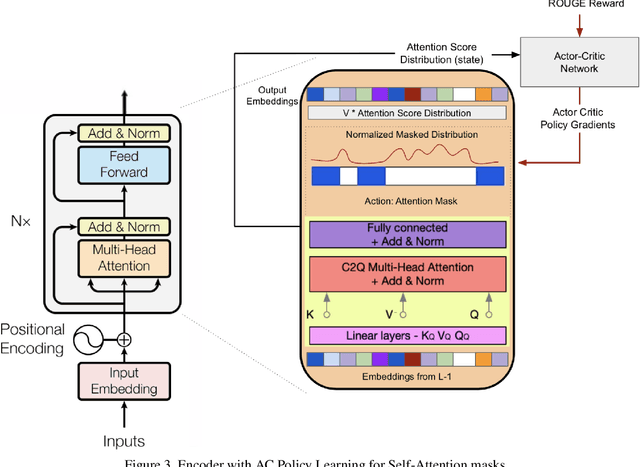
We present a novel architectural scheme to tackle the abstractive summarization problem based on the CNN/DMdataset which fuses Reinforcement Learning (RL) withUniLM, which is a pre-trained Deep Learning Model, to solve various natural language tasks. We have tested the limits of learning fine-grained attention in Transformers to improve the summarization quality. UniLM applies attention to the entire token space in a global fashion. We propose DR.SAS which applies the Actor-Critic (AC) algorithm to learn a dynamic self-attention distribution over the tokens to reduce redundancy and generate factual and coherent summaries to improve the quality of summarization. After performing hyperparameter tuning, we achievedbetter ROUGE results compared to the baseline. Our model tends to be more extractive/factual yet coherent in detail because of optimization over ROUGE rewards. We present detailed error analysis with examples of the strengths and limitations of our model. Our codebase will be publicly available on our GitHub.