 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrainchop: Next Generation Web-Based Neuroimaging Application
Oct 24, 2023



Performing volumetric image processing directly within the browser, particularly with medical data, presents unprecedented challenges compared to conventional backend tools. These challenges arise from limitations inherent in browser environments, such as constrained computational resources and the availability of frontend machine learning libraries. Consequently, there is a shortage of neuroimaging frontend tools capable of providing comprehensive end-to-end solutions for whole brain preprocessing and segmentation while preserving end-user data privacy and residency. In light of this context, we introduce Brainchop (http://www.brainchop.org) as a groundbreaking in-browser neuroimaging tool that enables volumetric analysis of structural MRI using pre-trained full-brain deep learning models, all without requiring technical expertise or intricate setup procedures. Beyond its commitment to data privacy, this frontend tool offers multiple features, including scalability, low latency, user-friendly operation, cross-platform compatibility, and enhanced accessibility. This paper outlines the processing pipeline of Brainchop and evaluates the performance of models across various software and hardware configurations. The results demonstrate the practicality of client-side processing for volumetric data, owing to the robust MeshNet architecture, even within the resource-constrained environment of web browsers.
Deep Reinforced Self-Attention Masks for Abstractive Summarization (DR.SAS)
Dec 30, 2019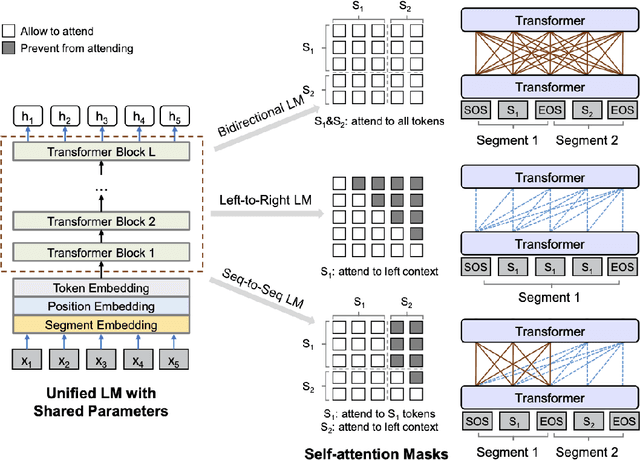
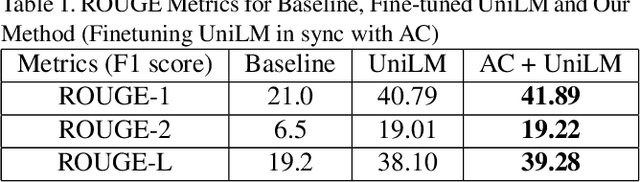

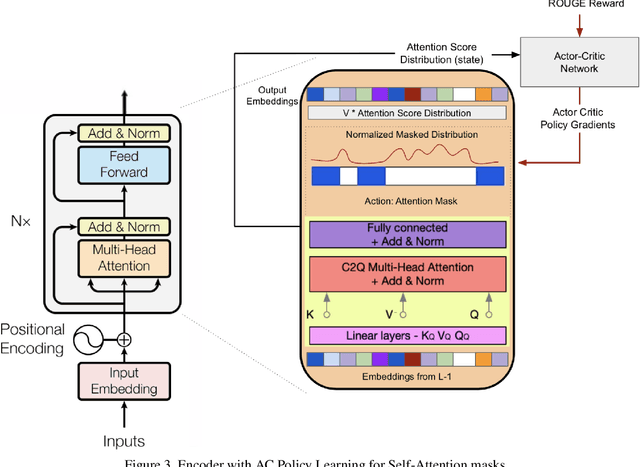
We present a novel architectural scheme to tackle the abstractive summarization problem based on the CNN/DMdataset which fuses Reinforcement Learning (RL) withUniLM, which is a pre-trained Deep Learning Model, to solve various natural language tasks. We have tested the limits of learning fine-grained attention in Transformers to improve the summarization quality. UniLM applies attention to the entire token space in a global fashion. We propose DR.SAS which applies the Actor-Critic (AC) algorithm to learn a dynamic self-attention distribution over the tokens to reduce redundancy and generate factual and coherent summaries to improve the quality of summarization. After performing hyperparameter tuning, we achievedbetter ROUGE results compared to the baseline. Our model tends to be more extractive/factual yet coherent in detail because of optimization over ROUGE rewards. We present detailed error analysis with examples of the strengths and limitations of our model. Our codebase will be publicly available on our GitHub.
Towards Robust Human Activity Recognition from RGB Video Stream with Limited Labeled Data
Dec 16, 2018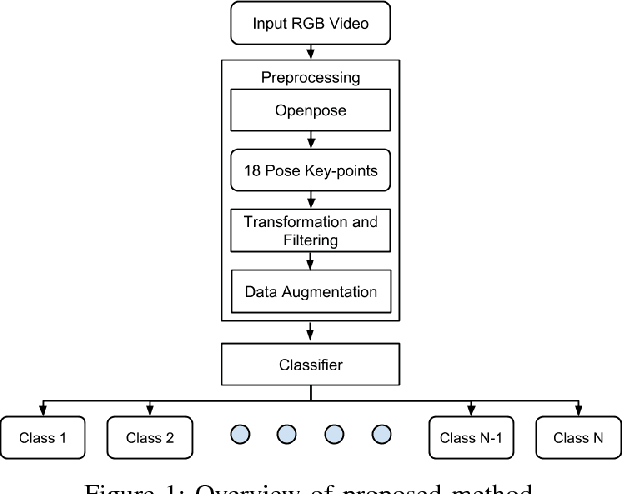
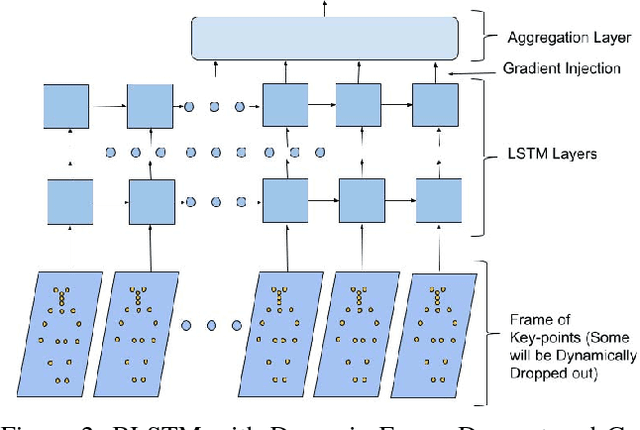
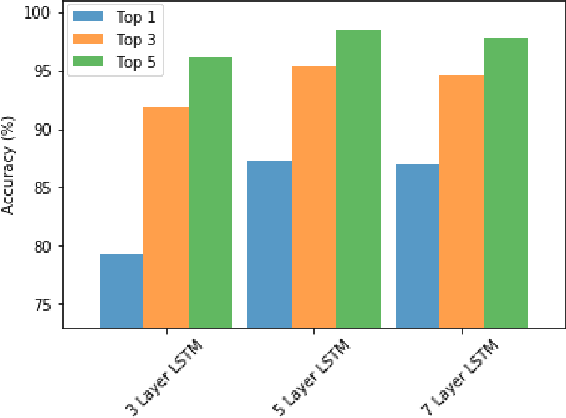
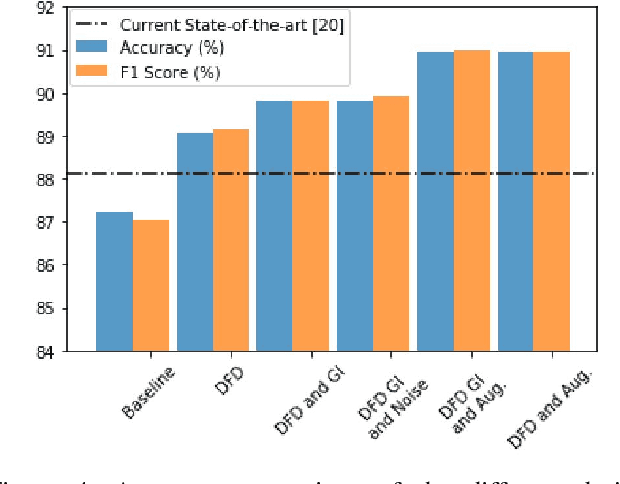
Human activity recognition based on video streams has received numerous attentions in recent years. Due to lack of depth information, RGB video based activity recognition performs poorly compared to RGB-D video based solutions. On the other hand, acquiring depth information, inertia etc. is costly and requires special equipment, whereas RGB video streams are available in ordinary cameras. Hence, our goal is to investigate whether similar or even higher accuracy can be achieved with RGB-only modality. In this regard, we propose a novel framework that couples skeleton data extracted from RGB video and deep Bidirectional Long Short Term Memory (BLSTM) model for activity recognition. A big challenge of training such a deep network is the limited training data, and exploring RGB-only stream significantly exaggerates the difficulty. We therefore propose a set of algorithmic techniques to train this model effectively, e.g., data augmentation, dynamic frame dropout and gradient injection. The experiments demonstrate that our RGB-only solution surpasses the state-of-the-art approaches that all exploit RGB-D video streams by a notable margin. This makes our solution widely deployable with ordinary cameras.