 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuper Resolution On Global Weather Forecasts
Sep 19, 2024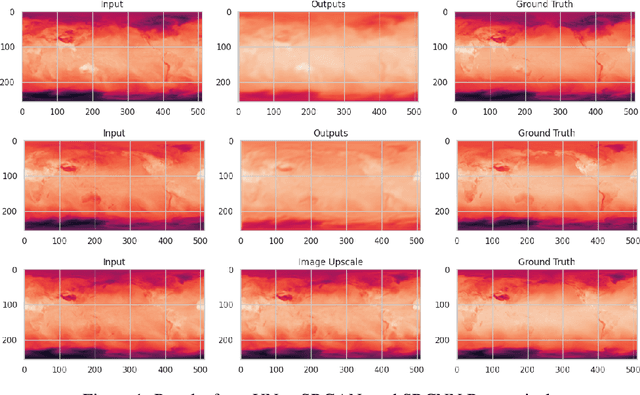
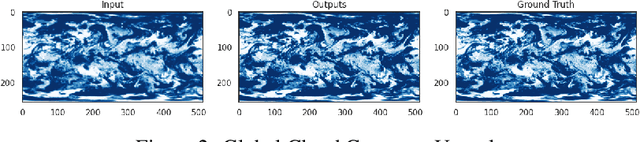
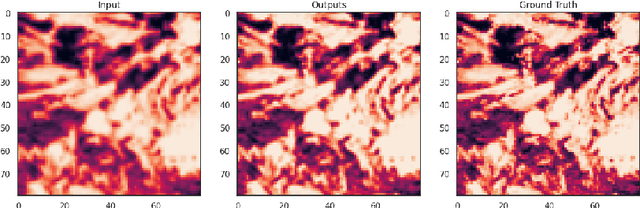
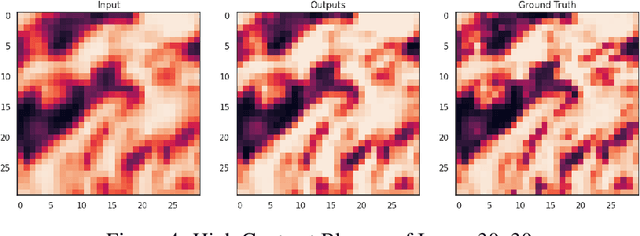
Weather forecasting is a vitally important tool for tasks ranging from planning day to day activities to disaster response planning. However, modeling weather has proven to be challenging task due to its chaotic and unpredictable nature. Each variable, from temperature to precipitation to wind, all influence the path the environment will take. As a result, all models tend to rapidly lose accuracy as the temporal range of their forecasts increase. Classical forecasting methods use a myriad of physics-based, numerical, and stochastic techniques to predict the change in weather variables over time. However, such forecasts often require a very large amount of data and are extremely computationally expensive. Furthermore, as climate and global weather patterns change, classical models are substantially more difficult and time-consuming to update for changing environments. Fortunately, with recent advances in deep learning and publicly available high quality weather datasets, deploying learning methods for estimating these complex systems has become feasible. The current state-of-the-art deep learning models have comparable accuracy to the industry standard numerical models and are becoming more ubiquitous in practice due to their adaptability. Our group seeks to improve upon existing deep learning based forecasting methods by increasing spatial resolutions of global weather predictions. Specifically, we are interested in performing super resolution (SR) on GraphCast temperature predictions by increasing the global precision from 1 degree of accuracy to 0.5 degrees, which is approximately 111km and 55km respectively.
Machine Translation Impact in E-commerce Multilingual Search
Jan 31, 2023



Previous work suggests that performance of cross-lingual information retrieval correlates highly with the quality of Machine Translation. However, there may be a threshold beyond which improving query translation quality yields little or no benefit to further improve the retrieval performance. This threshold may depend upon multiple factors including the source and target languages, the existing MT system quality and the search pipeline. In order to identify the benefit of improving an MT system for a given search pipeline, we investigate the sensitivity of retrieval quality to the presence of different levels of MT quality using experimental datasets collected from actual traffic. We systematically improve the performance of our MT systems quality on language pairs as measured by MT evaluation metrics including Bleu and Chrf to determine their impact on search precision metrics and extract signals that help to guide the improvement strategies. Using this information we develop techniques to compare query translations for multiple language pairs and identify the most promising language pairs to invest and improve.