 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Efficiency and Coverage in Human-Robot Dialogue Collection
Oct 07, 2018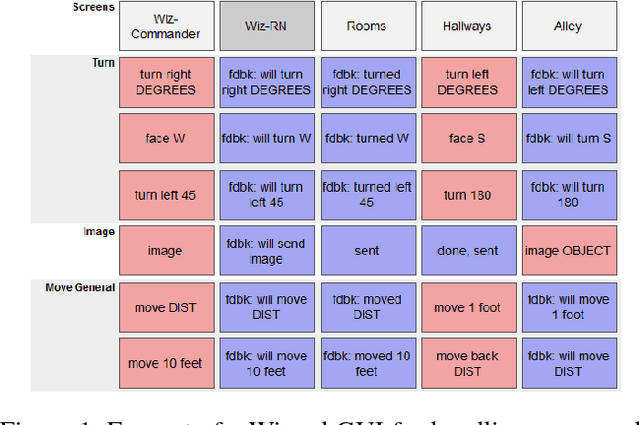
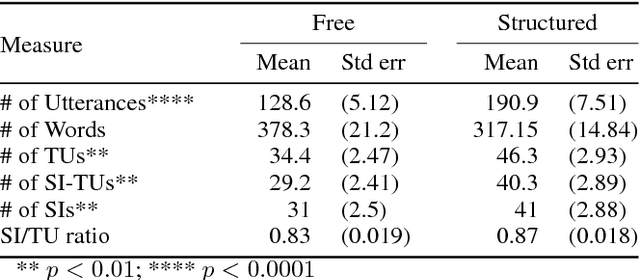
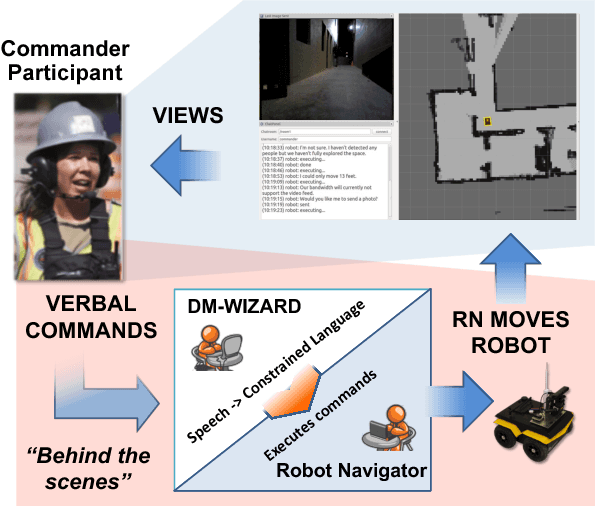
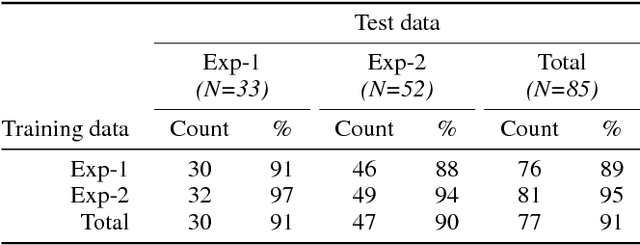
We describe a multi-phased Wizard-of-Oz approach to collecting human-robot dialogue in a collaborative search and navigation task. The data is being used to train an initial automated robot dialogue system to support collaborative exploration tasks. In the first phase, a wizard freely typed robot utterances to human participants. For the second phase, this data was used to design a GUI that includes buttons for the most common communications, and templates for communications with varying parameters. Comparison of the data gathered in these phases show that the GUI enabled a faster pace of dialogue while still maintaining high coverage of suitable responses, enabling more efficient targeted data collection, and improvements in natural language understanding using GUI-collected data. As a promising first step towards interactive learning, this work shows that our approach enables the collection of useful training data for navigation-based HRI tasks.
Controlling Personality-Based Stylistic Variation with Neural Natural Language Generators
May 22, 2018
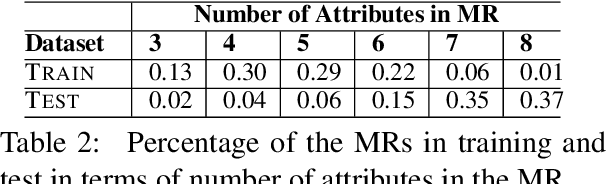
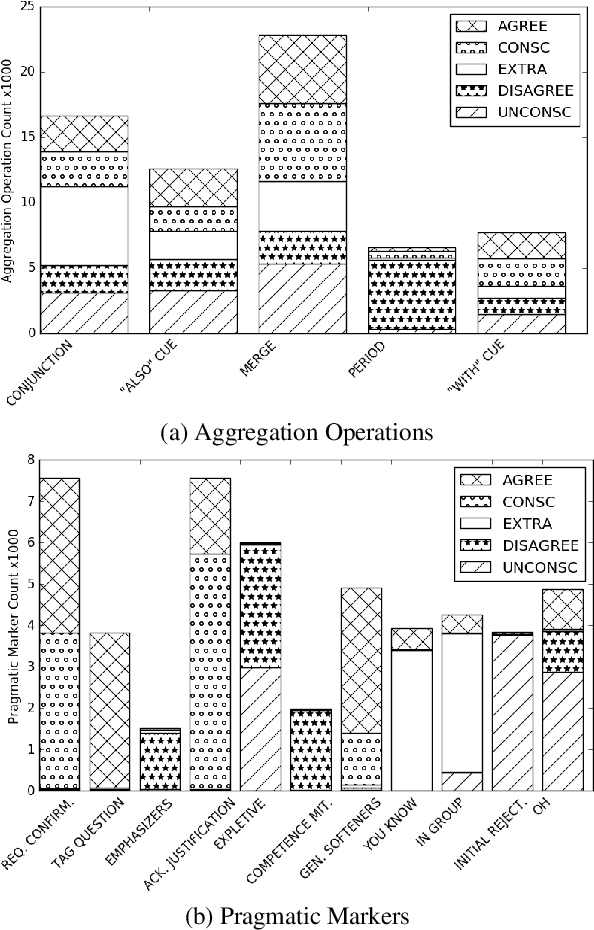

Natural language generators for task-oriented dialogue must effectively realize system dialogue actions and their associated semantics. In many applications, it is also desirable for generators to control the style of an utterance. To date, work on task-oriented neural generation has primarily focused on semantic fidelity rather than achieving stylistic goals, while work on style has been done in contexts where it is difficult to measure content preservation. Here we present three different sequence-to-sequence models and carefully test how well they disentangle content and style. We use a statistical generator, Personage, to synthesize a new corpus of over 88,000 restaurant domain utterances whose style varies according to models of personality, giving us total control over both the semantic content and the stylistic variation in the training data. We then vary the amount of explicit stylistic supervision given to the three models. We show that our most explicit model can simultaneously achieve high fidelity to both semantic and stylistic goals: this model adds a context vector of 36 stylistic parameters as input to the hidden state of the encoder at each time step, showing the benefits of explicit stylistic supervision, even when the amount of training data is large.
Data-Driven Dialogue Systems for Social Agents
Sep 10, 2017In order to build dialogue systems to tackle the ambitious task of holding social conversations, we argue that we need a data driven approach that includes insight into human conversational chit chat, and which incorporates different natural language processing modules. Our strategy is to analyze and index large corpora of social media data, including Twitter conversations, online debates, dialogues between friends, and blog posts, and then to couple this data retrieval with modules that perform tasks such as sentiment and style analysis, topic modeling, and summarization. We aim for personal assistants that can learn more nuanced human language, and to grow from task-oriented agents to more personable social bots.
Getting Reliable Annotations for Sarcasm in Online Dialogues
Sep 04, 2017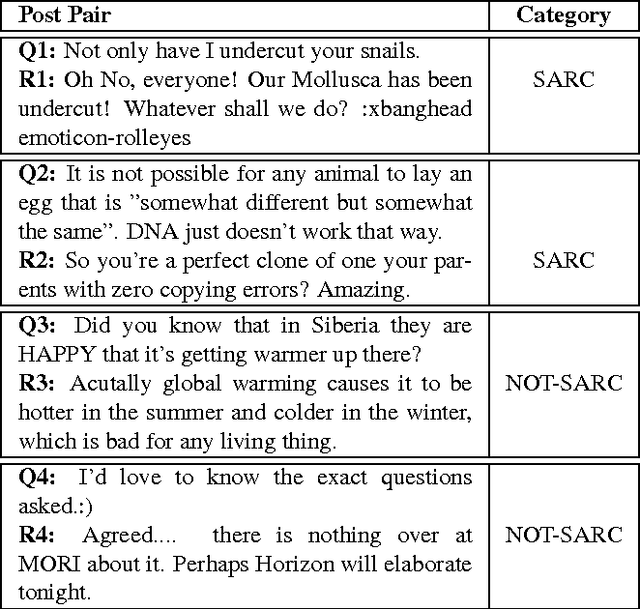
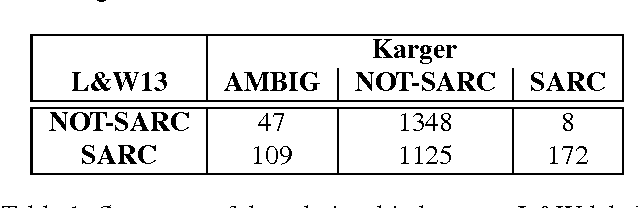
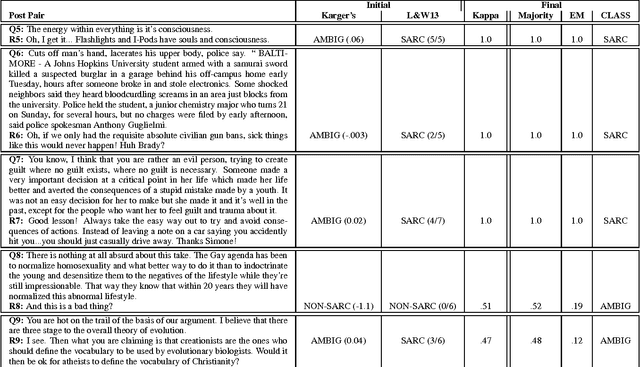
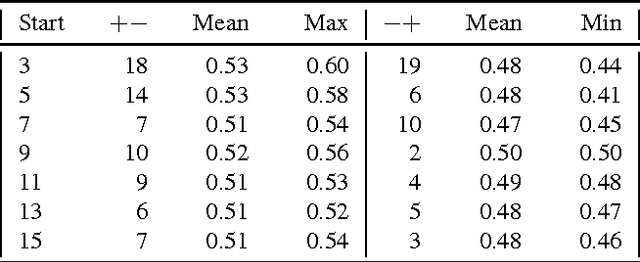
The language used in online forums differs in many ways from that of traditional language resources such as news. One difference is the use and frequency of nonliteral, subjective dialogue acts such as sarcasm. Whether the aim is to develop a theory of sarcasm in dialogue, or engineer automatic methods for reliably detecting sarcasm, a major challenge is simply the difficulty of getting enough reliably labelled examples. In this paper we describe our work on methods for achieving highly reliable sarcasm annotations from untrained annotators on Mechanical Turk. We explore the use of a number of common statistical reliability measures, such as Kappa, Karger's, Majority Class, and EM. We show that more sophisticated measures do not appear to yield better results for our data than simple measures such as assuming that the correct label is the one that a majority of Turkers apply.
Really? Well. Apparently Bootstrapping Improves the Performance of Sarcasm and Nastiness Classifiers for Online Dialogue
Aug 29, 2017
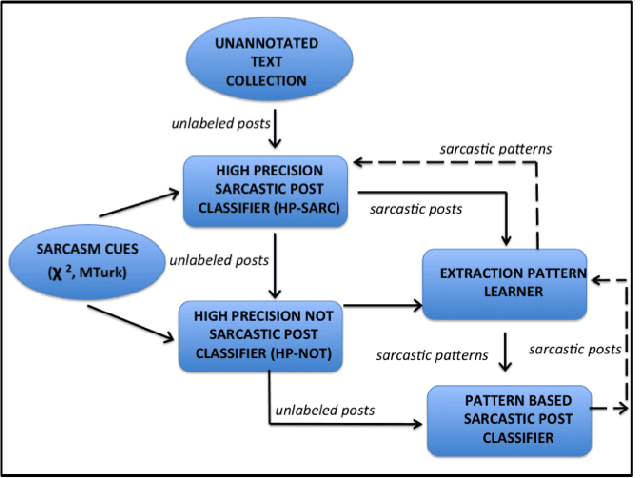
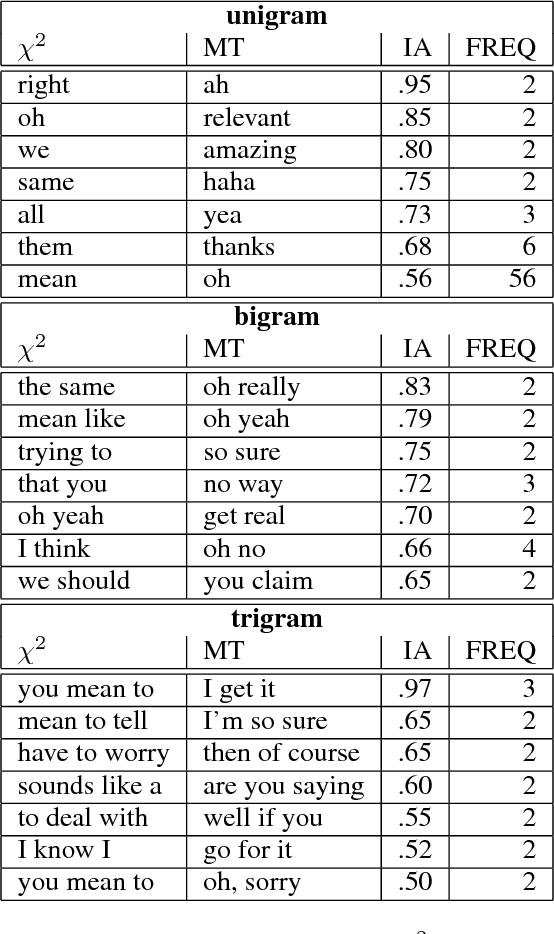

More and more of the information on the web is dialogic, from Facebook newsfeeds, to forum conversations, to comment threads on news articles. In contrast to traditional, monologic Natural Language Processing resources such as news, highly social dialogue is frequent in social media, making it a challenging context for NLP. This paper tests a bootstrapping method, originally proposed in a monologic domain, to train classifiers to identify two different types of subjective language in dialogue: sarcasm and nastiness. We explore two methods of developing linguistic indicators to be used in a first level classifier aimed at maximizing precision at the expense of recall. The best performing classifier for the first phase achieves 54% precision and 38% recall for sarcastic utterances. We then use general syntactic patterns from previous work to create more general sarcasm indicators, improving precision to 62% and recall to 52%. To further test the generality of the method, we then apply it to bootstrapping a classifier for nastiness dialogic acts. Our first phase, using crowdsourced nasty indicators, achieves 58% precision and 49% recall, which increases to 75% precision and 62% recall when we bootstrap over the first level with generalized syntactic patterns.