 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Generation of Dialogue Acts for Dialogue Systems via Few-Shot Response Generation and Ranking
Jul 26, 2023Dialogue systems need to produce responses that realize multiple types of dialogue acts (DAs) with high semantic fidelity. In the past, natural language generators (NLGs) for dialogue were trained on large parallel corpora that map from a domain-specific DA and its semantic attributes to an output utterance. Recent work shows that pretrained language models (LLMs) offer new possibilities for controllable NLG using prompt-based learning. Here we develop a novel few-shot overgenerate-and-rank approach that achieves the controlled generation of DAs. We compare eight few-shot prompt styles that include a novel method of generating from textual pseudo-references using a textual style transfer approach. We develop six automatic ranking functions that identify outputs with both the correct DA and high semantic accuracy at generation time. We test our approach on three domains and four LLMs. To our knowledge, this is the first work on NLG for dialogue that automatically ranks outputs using both DA and attribute accuracy. For completeness, we compare our results to fine-tuned few-shot models trained with 5 to 100 instances per DA. Our results show that several prompt settings achieve perfect DA accuracy, and near perfect semantic accuracy (99.81%) and perform better than few-shot fine-tuning.
A Deep Ensemble Model with Slot Alignment for Sequence-to-Sequence Natural Language Generation
May 16, 2018


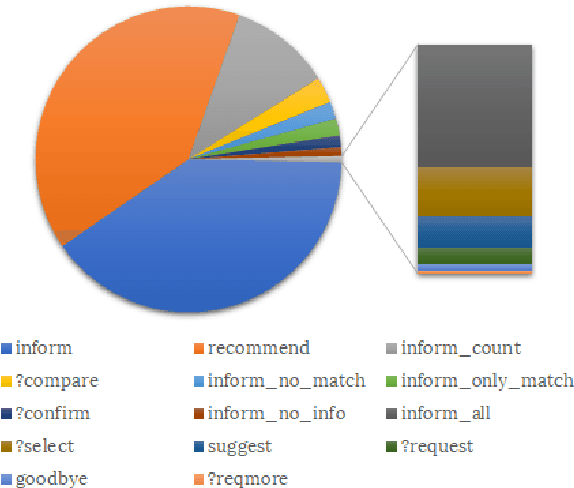
Natural language generation lies at the core of generative dialogue systems and conversational agents. We describe an ensemble neural language generator, and present several novel methods for data representation and augmentation that yield improved results in our model. We test the model on three datasets in the restaurant, TV and laptop domains, and report both objective and subjective evaluations of our best model. Using a range of automatic metrics, as well as human evaluators, we show that our approach achieves better results than state-of-the-art models on the same datasets.
Exploring Conversational Language Generation for Rich Content about Hotels
May 01, 2018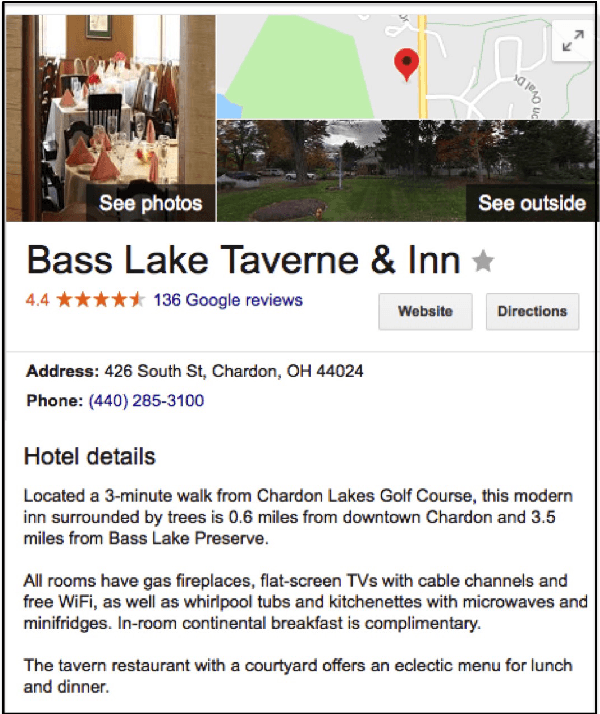
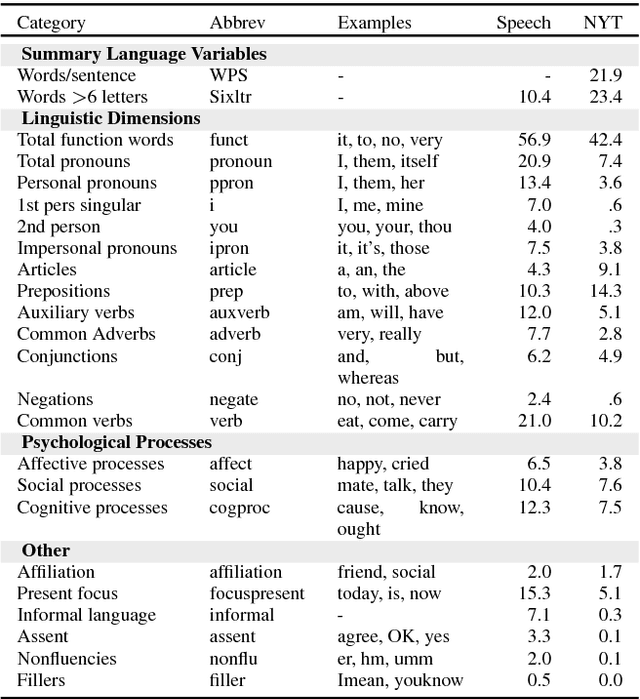

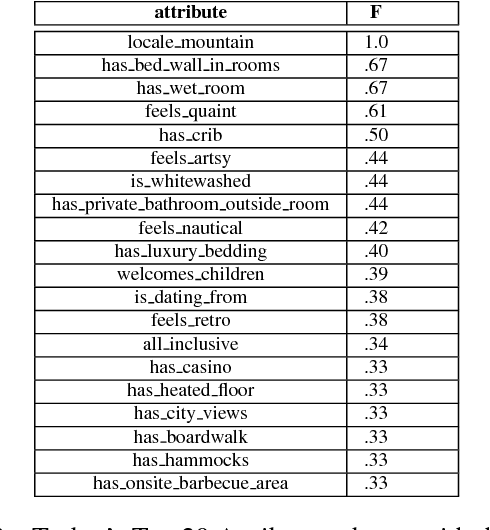
Dialogue systems for hotel and tourist information have typically simplified the richness of the domain, focusing system utterances on only a few selected attributes such as price, location and type of rooms. However, much more content is typically available for hotels, often as many as 50 distinct instantiated attributes for an individual entity. New methods are needed to use this content to generate natural dialogues for hotel information, and in general for any domain with such rich complex content. We describe three experiments aimed at collecting data that can inform an NLG for hotels dialogues, and show, not surprisingly, that the sentences in the original written hotel descriptions provided on webpages for each hotel are stylistically not a very good match for conversational interaction. We quantify the stylistic features that characterize the differences between the original textual data and the collected dialogic data. We plan to use these in stylistic models for generation, and for scoring retrieved utterances for use in hotel dialogues
Measuring the Similarity of Sentential Arguments in Dialog
Sep 06, 2017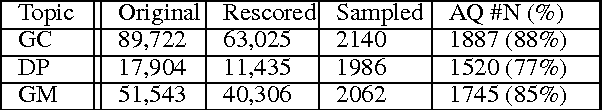
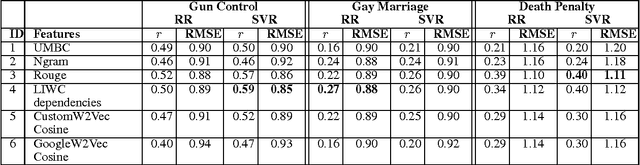

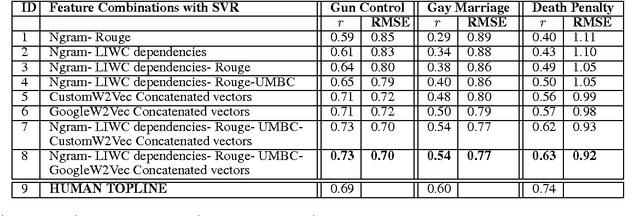
When people converse about social or political topics, similar arguments are often paraphrased by different speakers, across many different conversations. Debate websites produce curated summaries of arguments on such topics; these summaries typically consist of lists of sentences that represent frequently paraphrased propositions, or labels capturing the essence of one particular aspect of an argument, e.g. Morality or Second Amendment. We call these frequently paraphrased propositions ARGUMENT FACETS. Like these curated sites, our goal is to induce and identify argument facets across multiple conversations, and produce summaries. However, we aim to do this automatically. We frame the problem as consisting of two steps: we first extract sentences that express an argument from raw social media dialogs, and then rank the extracted arguments in terms of their similarity to one another. Sets of similar arguments are used to represent argument facets. We show here that we can predict ARGUMENT FACET SIMILARITY with a correlation averaging 0.63 compared to a human topline averaging 0.68 over three debate topics, easily beating several reasonable baselines.
Storytelling Agents with Personality and Adaptivity
Sep 04, 2017
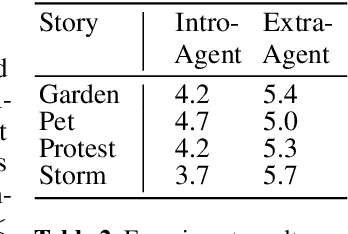

We explore the expression of personality and adaptivity through the gestures of virtual agents in a storytelling task. We conduct two experiments using four different dialogic stories. We manipulate agent personality on the extraversion scale, whether the agents adapt to one another in their gestural performance and agent gender. Our results show that subjects are able to perceive the intended variation in extraversion between different virtual agents, independently of the story they are telling and the gender of the agent. A second study shows that subjects also prefer adaptive to nonadaptive virtual agents.
* Related dataset: https://nlds.soe.ucsc.edu/sdg
Getting Reliable Annotations for Sarcasm in Online Dialogues
Sep 04, 2017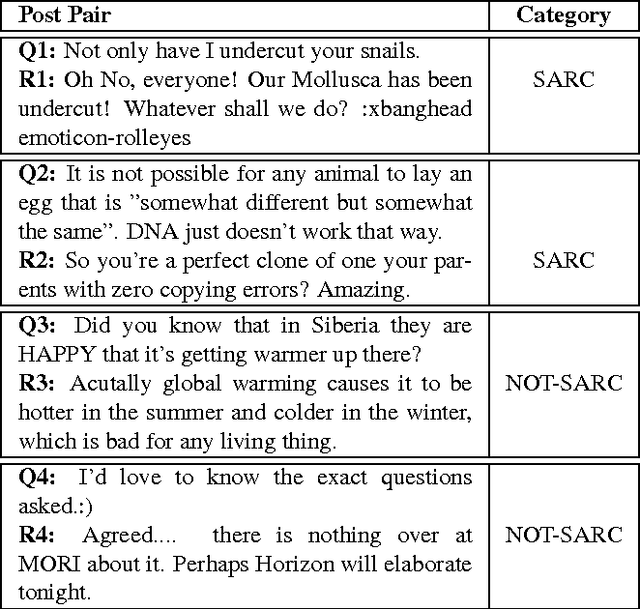
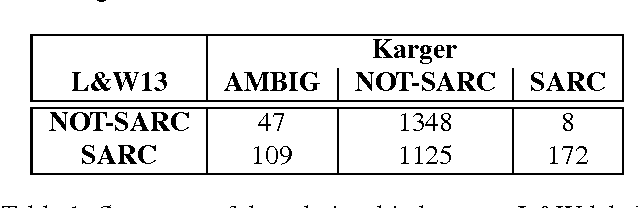
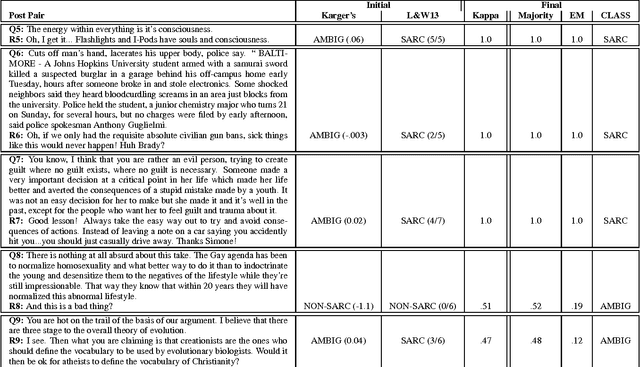
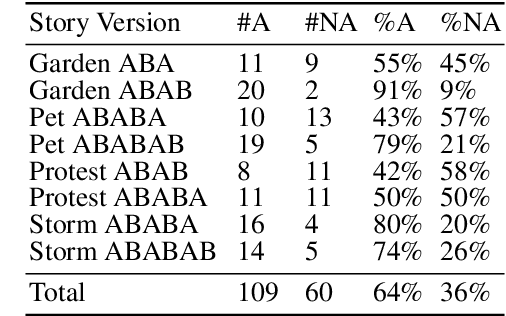
The language used in online forums differs in many ways from that of traditional language resources such as news. One difference is the use and frequency of nonliteral, subjective dialogue acts such as sarcasm. Whether the aim is to develop a theory of sarcasm in dialogue, or engineer automatic methods for reliably detecting sarcasm, a major challenge is simply the difficulty of getting enough reliably labelled examples. In this paper we describe our work on methods for achieving highly reliable sarcasm annotations from untrained annotators on Mechanical Turk. We explore the use of a number of common statistical reliability measures, such as Kappa, Karger's, Majority Class, and EM. We show that more sophisticated measures do not appear to yield better results for our data than simple measures such as assuming that the correct label is the one that a majority of Turkers apply.
Unsupervised Induction of Contingent Event Pairs from Film Scenes
Aug 30, 2017


Human engagement in narrative is partially driven by reasoning about discourse relations between narrative events, and the expectations about what is likely to happen next that results from such reasoning. Researchers in NLP have tackled modeling such expectations from a range of perspectives, including treating it as the inference of the contingent discourse relation, or as a type of common-sense causal reasoning. Our approach is to model likelihood between events by drawing on several of these lines of previous work. We implement and evaluate different unsupervised methods for learning event pairs that are likely to be contingent on one another. We refine event pairs that we learn from a corpus of film scene descriptions utilizing web search counts, and evaluate our results by collecting human judgments of contingency. Our results indicate that the use of web search counts increases the average accuracy of our best method to 85.64% over a baseline of 50%, as compared to an average accuracy of 75.15% without web search.
Inferring Narrative Causality between Event Pairs in Films
Aug 30, 2017
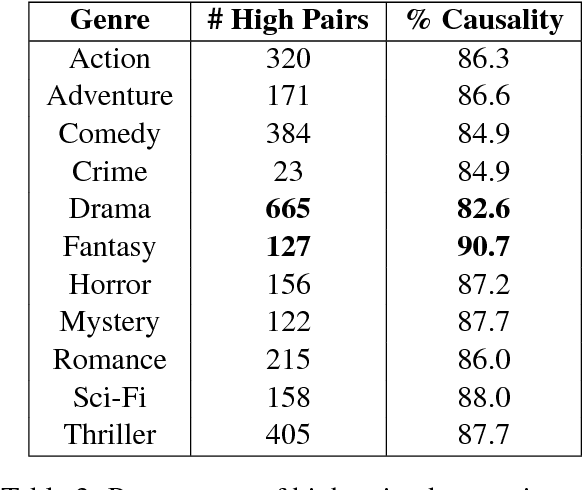
To understand narrative, humans draw inferences about the underlying relations between narrative events. Cognitive theories of narrative understanding define these inferences as four different types of causality, that include pairs of events A, B where A physically causes B (X drop, X break), to pairs of events where A causes emotional state B (Y saw X, Y felt fear). Previous work on learning narrative relations from text has either focused on "strict" physical causality, or has been vague about what relation is being learned. This paper learns pairs of causal events from a corpus of film scene descriptions which are action rich and tend to be told in chronological order. We show that event pairs induced using our methods are of high quality and are judged to have a stronger causal relation than event pairs from Rel-grams.
Automating Direct Speech Variations in Stories and Games
Aug 30, 2017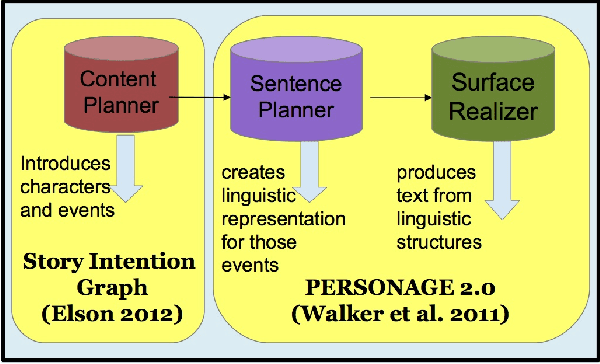

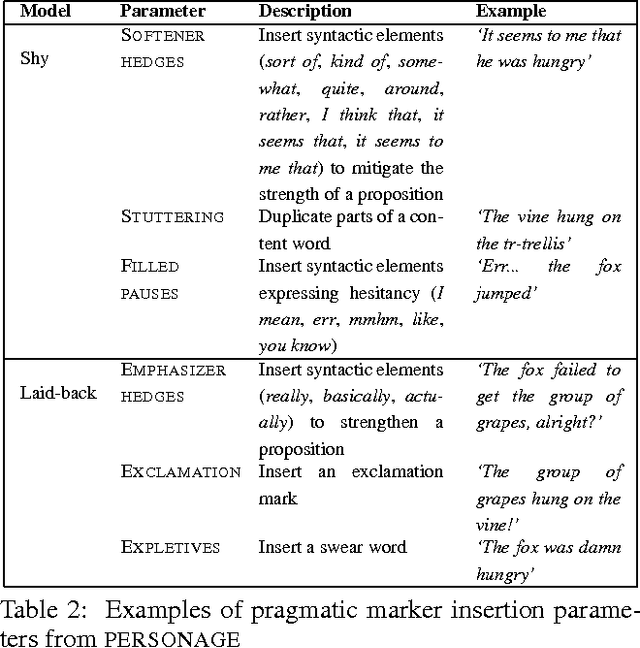

Dialogue authoring in large games requires not only content creation but the subtlety of its delivery, which can vary from character to character. Manually authoring this dialogue can be tedious, time-consuming, or even altogether infeasible. This paper utilizes a rich narrative representation for modeling dialogue and an expressive natural language generation engine for realizing it, and expands upon a translation tool that bridges the two. We add functionality to the translator to allow direct speech to be modeled by the narrative representation, whereas the original translator supports only narratives told by a third person narrator. We show that we can perform character substitution in dialogues. We implement and evaluate a potential application to dialogue implementation: generating dialogue for games with big, dynamic, or procedurally-generated open worlds. We present a pilot study on human perceptions of the personalities of characters using direct speech, assuming unknown personality types at the time of authoring.
PersonaBank: A Corpus of Personal Narratives and Their Story Intention Graphs
Aug 30, 2017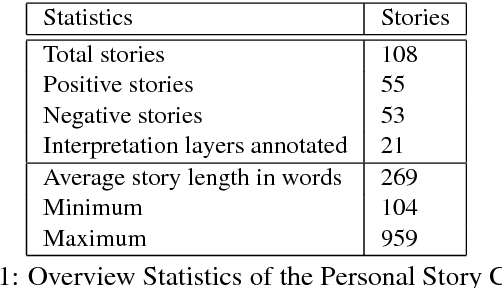
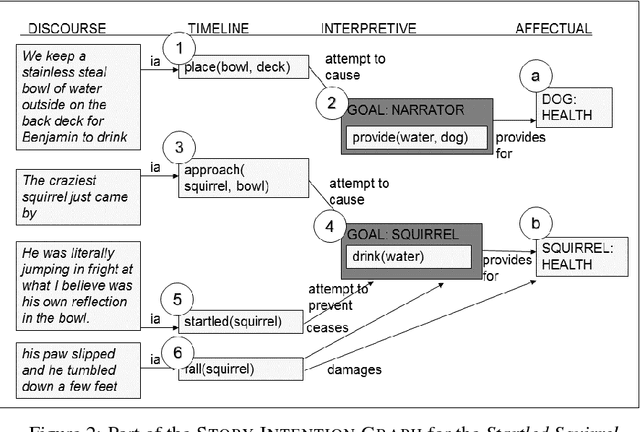


We present a new corpus, PersonaBank, consisting of 108 personal stories from weblogs that have been annotated with their Story Intention Graphs, a deep representation of the fabula of a story. We describe the topics of the stories and the basis of the Story Intention Graph representation, as well as the process of annotating the stories to produce the Story Intention Graphs and the challenges of adapting the tool to this new personal narrative domain We also discuss how the corpus can be used in applications that retell the story using different styles of tellings, co-tellings, or as a content planner.