 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Fairness in Personalized Ads Using Impression Variance Aware Reinforcement Learning
Jun 08, 2023



Variances in ad impression outcomes across demographic groups are increasingly considered to be potentially indicative of algorithmic bias in personalized ads systems. While there are many definitions of fairness that could be applicable in the context of personalized systems, we present a framework which we call the Variance Reduction System (VRS) for achieving more equitable outcomes in Meta's ads systems. VRS seeks to achieve a distribution of impressions with respect to selected protected class (PC) attributes that more closely aligns the demographics of an ad's eligible audience (a function of advertiser targeting criteria) with the audience who sees that ad, in a privacy-preserving manner. We first define metrics to quantify fairness gaps in terms of ad impression variances with respect to PC attributes including gender and estimated race. We then present the VRS for re-ranking ads in an impression variance-aware manner. We evaluate VRS via extensive simulations over different parameter choices and study the effect of the VRS on the chosen fairness metric. We finally present online A/B testing results from applying VRS to Meta's ads systems, concluding with a discussion of future work. We have deployed the VRS to all users in the US for housing ads, resulting in significant improvement in our fairness metric. VRS is the first large-scale deployed framework for pursuing fairness for multiple PC attributes in online advertising.
Conditional Sequential Slate Optimization
Aug 13, 2021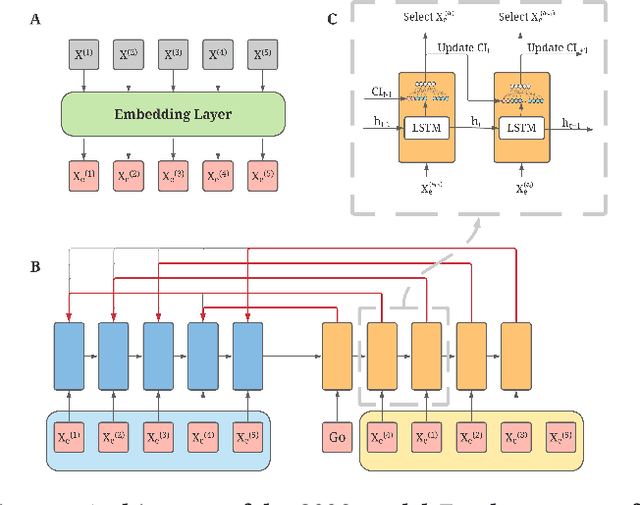
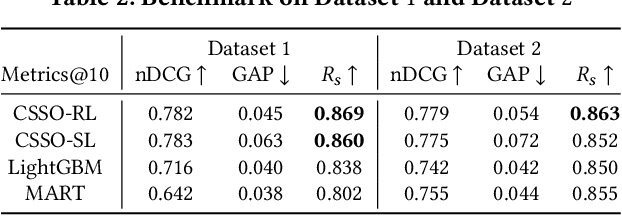
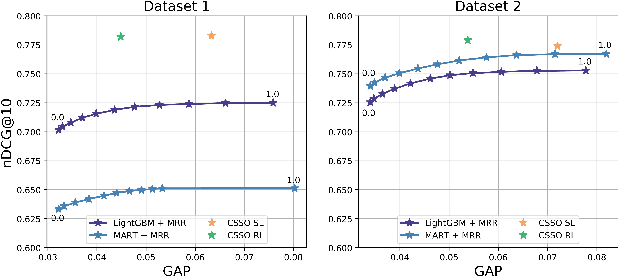
The top search results matching a user query that are displayed on the first page are critical to the effectiveness and perception of a search system. A search ranking system typically orders the results by independent query-document scores to produce a slate of search results. However, such unilateral scoring methods may fail to capture inter-document dependencies that users are sensitive to, thus producing a sub-optimal slate. Further, in practice, many real-world applications such as e-commerce search require enforcing certain distributional criteria at the slate-level, due to business objectives or long term user retention goals. Unilateral scoring of results does not explicitly support optimizing for such objectives with respect to a slate. Hence, solutions to the slate optimization problem must consider the optimal selection and order of the documents, along with adherence to slate-level distributional criteria. To that end, we propose a hybrid framework extended from traditional slate optimization to solve the conditional slate optimization problem. We introduce conditional sequential slate optimization (CSSO), which jointly learns to optimize for traditional ranking metrics as well as prescribed distribution criteria of documents within the slate. The proposed method can be applied to practical real world problems such as enforcing diversity in e-commerce search results, mitigating bias in top results and personalization of results. Experiments on public datasets and real-world data from e-commerce datasets show that CSSO outperforms popular comparable ranking methods in terms of adherence to distributional criteria while producing comparable or better relevance metrics.
Addressing Purchase-Impression Gap through a Sequential Re-ranker
Oct 27, 2020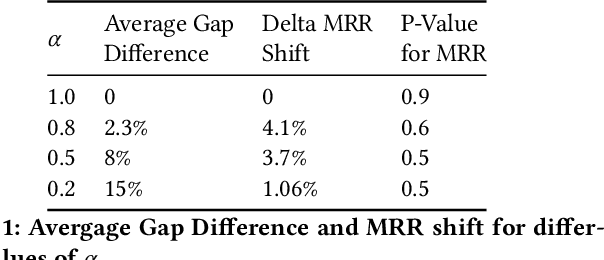
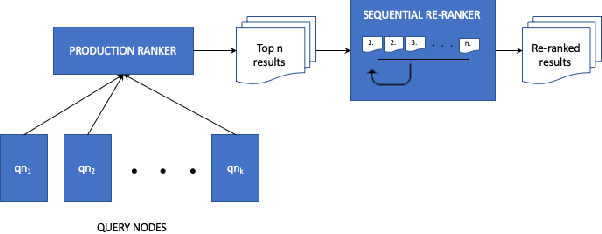
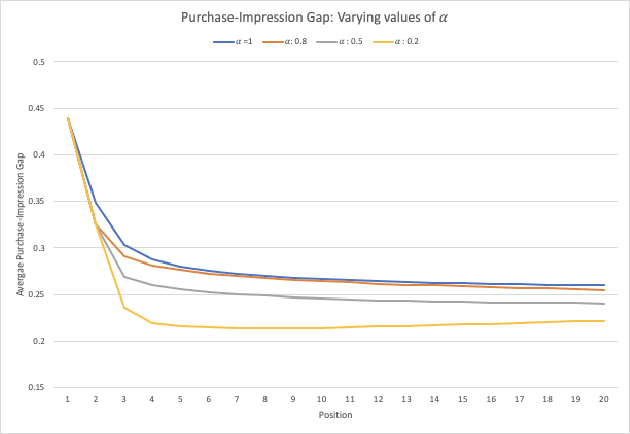
Large scale eCommerce platforms such as eBay carry a wide variety of inventory and provide several buying choices to online shoppers. It is critical for eCommerce search engines to showcase in the top results the variety and selection of inventory available, specifically in the context of the various buying intents that may be associated with a search query. Search rankers are most commonly powered by learning-to-rank models which learn the preference between items during training. However, they score items independent of other items at runtime. Although the items placed at top of the results by such scoring functions may be independently optimal, they can be sub-optimal as a set. This may lead to a mismatch between the ideal distribution of items in the top results vs what is actually impressed. In this paper, we present methods to address the purchase-impression gap observed in top search results on eCommerce sites. We establish the ideal distribution of items based on historic shopping patterns. We then present a sequential reranker that methodically reranks top search results produced by a conventional pointwise scoring ranker. The reranker produces a reordered list by sequentially selecting candidates trading off between their independent relevance and potential to address the purchase-impression gap by utilizing specially constructed features that capture impression distribution of items already added to a reranked list. The sequential reranker enables addressing purchase impression gap with respect to multiple item aspects. Early version of the reranker showed promising lifts in conversion and engagement metrics at eBay. Based on experiments on randomly sampled validation datasets, we observe that the reranking methodology presented produces around 10% reduction in purchase-impression gap at an average for the top 20 results, while making improvements to conversion metrics.
Exploring the Effect of an Item's Neighborhood on its Sellability in eCommerce
Aug 10, 2019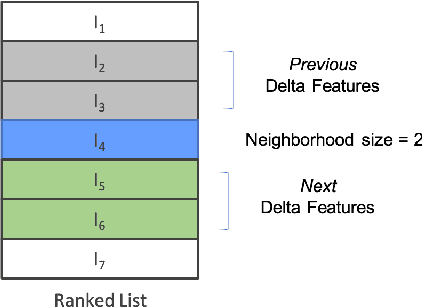
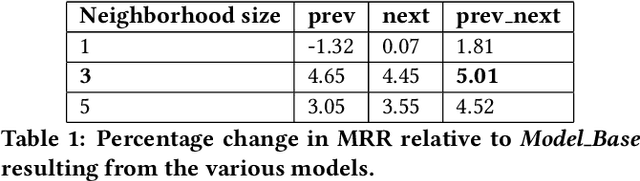
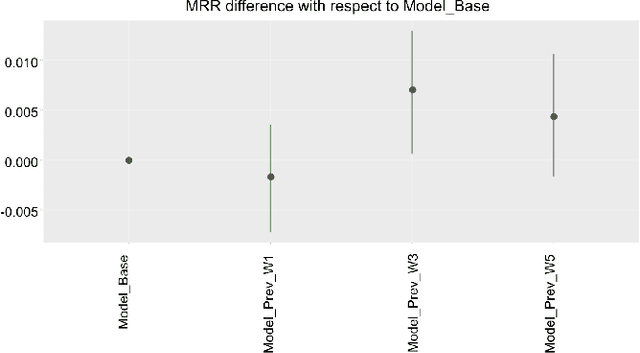
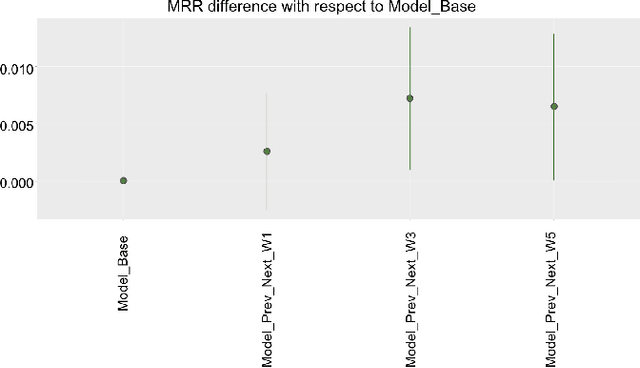
Predicting the sale of an item is a critical problem in eCommerce search. Typically, items are independently predicted with a probability of sale for a given search query. But in a dynamic marketplace like eBay, even for a single product, there are various different factors distinguishing one item from another which can influence the purchase decision for the user. Users have to make a purchase decision by considering all of these options. Majority of the existing learning to rank algorithms model the relative relevance between labeled items only at the loss functions like pairwise or list-wise losses. But they are limited to point-wise scoring functions where items are ranked independently based on the features of the item itself. In this paper, we study the influence of an item's neighborhood to its purchase decision. Here, we consider the neighborhood as the items ranked above and below the current item in search results. By adding delta features comparing items within a neighborhood and learning a ranking model, we are able to experimentally show that the new ranker with delta features outperforms our baseline ranker in terms of Mean Reciprocal Rank (MRR). The ranking model with proposed delta features result in $3-5\%$ improvement in MRR over the baseline model. We also study impact of different sizes for neighborhood. Experimental results show that neighborhood size $3$ perform the best based on MRR with an improvement of $4-5\%$ over the baseline model.
Personalized Query Auto-Completion Through a Lightweight Representation of the User Context
May 03, 2019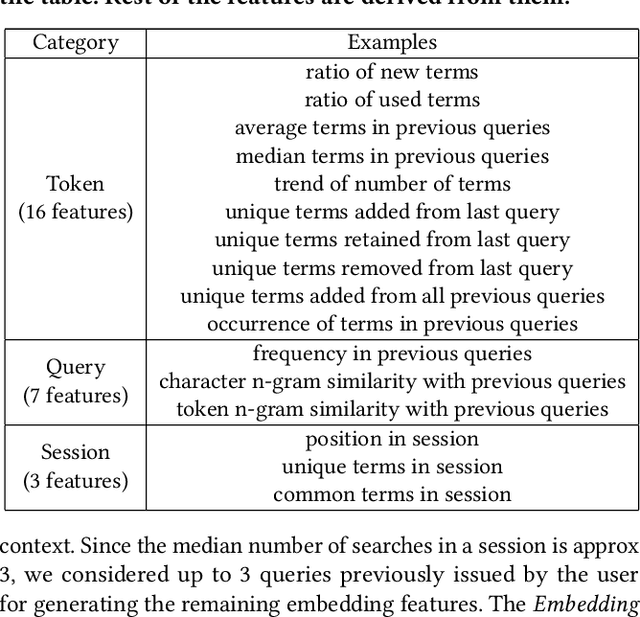
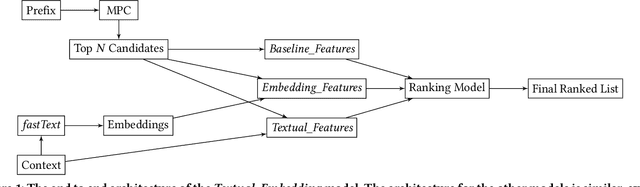
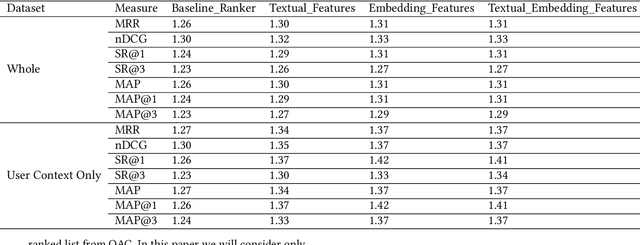
Query Auto-Completion (QAC) is a widely used feature in many domains, including web and eCommerce search, suggesting full queries based on a prefix typed by the user. QAC has been extensively studied in the literature in the recent years, and it has been consistently shown that adding personalization features can significantly improve the performance of QAC. In this work we propose a novel method for personalized QAC that uses lightweight embeddings learnt through fastText. We construct an embedding for the user context queries, which are the last few queries issued by the user. We also use the same model to get the embedding for the candidate queries to be ranked. We introduce ranking features that compute the distance between the candidate queries and the context queries in the embedding space. These features are then combined with other commonly used QAC ranking features to learn a ranking model. We apply our method to a large eCommerce search engine (eBay) and show that the ranker with our proposed feature significantly outperforms the baselines on all of the offline metrics measured, which includes Mean Reciprocal Rank (MRR), Success Rate (SR), Mean Average Precision (MAP), and Normalized Discounted Cumulative Gain (NDCG). Our baselines include the Most Popular Completion (MPC) model as well as a ranking model without our proposed features. The ranking model with the proposed features results in a $20-30\%$ improvement over the MPC model on all metrics. We obtain up to a $5\%$ improvement over the baseline ranking model for all the sessions, which goes up to about $10\%$ when we restrict to sessions that contain the user context. Moreover, our proposed features also significantly outperform text based personalization features studied in the literature before, and adding text based features on top of our proposed embedding based features results only in minor improvements.
Personalized Ranking in eCommerce Search
Apr 30, 2019
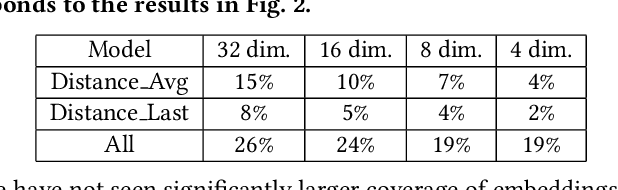
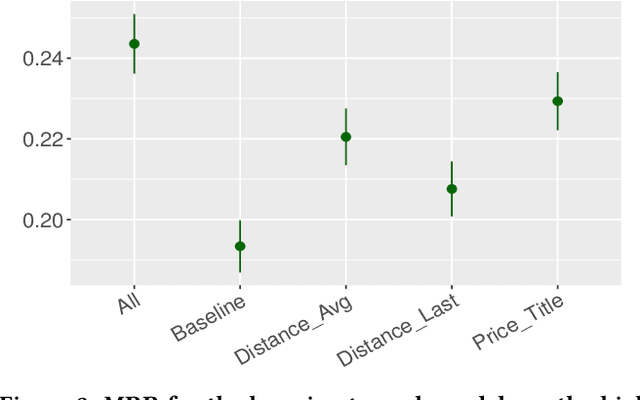
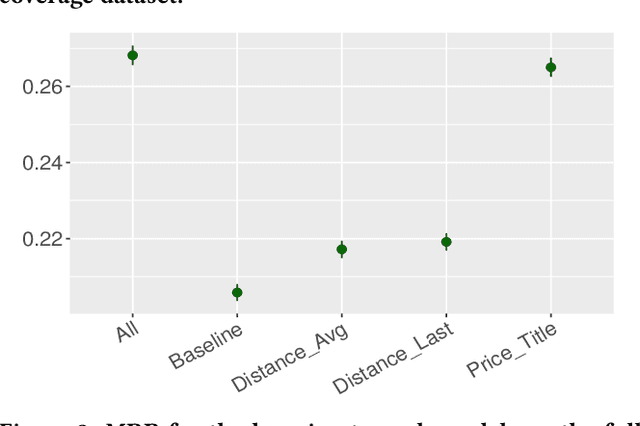
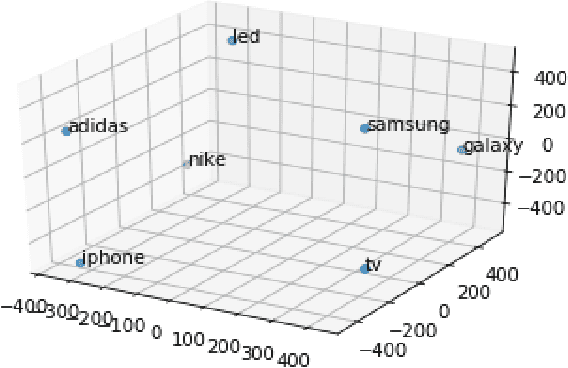
We address the problem of personalization in the context of eCommerce search. Specifically, we develop personalization ranking features that use in-session context to augment a generic ranker optimized for conversion and relevance. We use a combination of latent features learned from item co-clicks in historic sessions and content-based features that use item title and price. Personalization in search has been discussed extensively in the existing literature. The novelty of our work is combining and comparing content-based and content-agnostic features and showing that they complement each other to result in a significant improvement of the ranker. Moreover, our technique does not require an explicit re-ranking step, does not rely on learning user profiles from long term search behavior, and does not involve complex modeling of query-item-user features. Our approach captures item co-click propensity using lightweight item embeddings. We experimentally show that our technique significantly outperforms a generic ranker in terms of Mean Reciprocal Rank (MRR). We also provide anecdotal evidence for the semantic similarity captured by the item embeddings on the eBay search engine.