 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatents Phrase to Phrase Semantic Matching Dataset
Aug 01, 2022

There are many general purpose benchmark datasets for Semantic Textual Similarity but none of them are focused on technical concepts found in patents and scientific publications. This work aims to fill this gap by presenting a new human rated contextual phrase to phrase matching dataset. The entire dataset contains close to $50,000$ rated phrase pairs, each with a CPC (Cooperative Patent Classification) class as a context. This paper describes the dataset and some baseline models.
Robust posterior inference when statistically emulating forward simulations
Apr 24, 2020

Scientific analyses often rely on slow, but accurate forward models for observable data conditioned on known model parameters. While various emulation schemes exist to approximate these slow calculations, these approaches are only safe if the approximations are well understood and controlled. This workshop submission reviews and updates a previously published method, which has been used in cosmological simulations, to (1) train an emulator while simultaneously estimating posterior probabilities with MCMC and (2) explicitly propagate the emulation error into errors on the posterior probabilities for model parameters. We demonstrate how these techniques can be applied to quickly estimate posterior distributions for parameters of the $\Lambda$CDM cosmology model, while also gauging the robustness of the emulator approximation.
Personalized Query Auto-Completion Through a Lightweight Representation of the User Context
May 03, 2019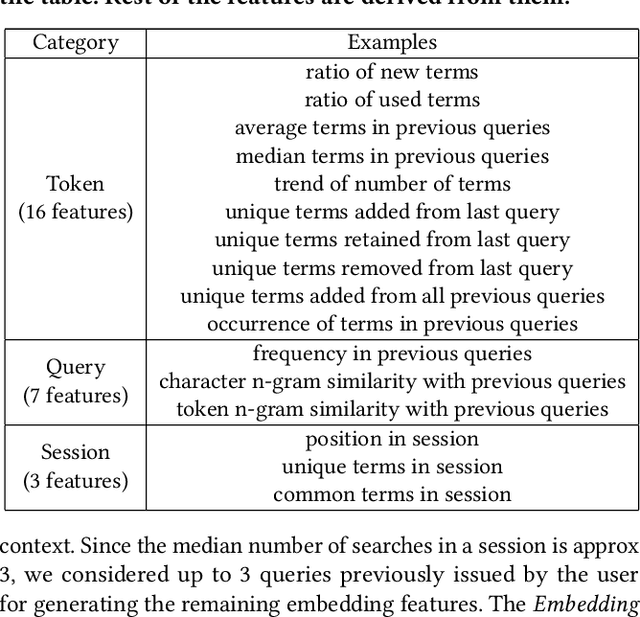
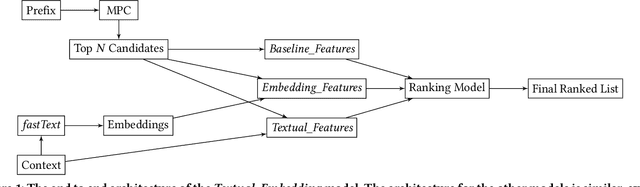
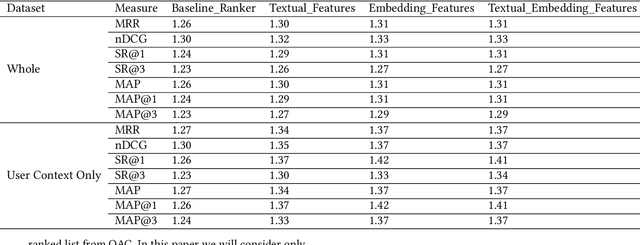
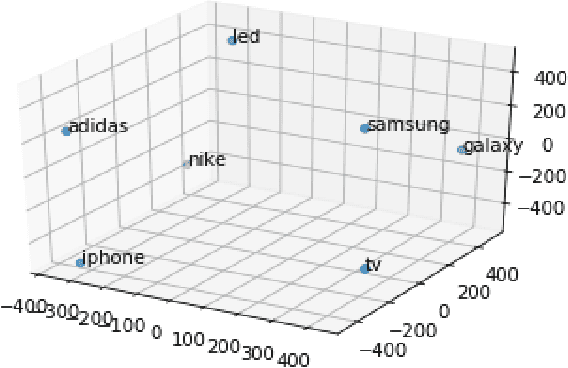
Query Auto-Completion (QAC) is a widely used feature in many domains, including web and eCommerce search, suggesting full queries based on a prefix typed by the user. QAC has been extensively studied in the literature in the recent years, and it has been consistently shown that adding personalization features can significantly improve the performance of QAC. In this work we propose a novel method for personalized QAC that uses lightweight embeddings learnt through fastText. We construct an embedding for the user context queries, which are the last few queries issued by the user. We also use the same model to get the embedding for the candidate queries to be ranked. We introduce ranking features that compute the distance between the candidate queries and the context queries in the embedding space. These features are then combined with other commonly used QAC ranking features to learn a ranking model. We apply our method to a large eCommerce search engine (eBay) and show that the ranker with our proposed feature significantly outperforms the baselines on all of the offline metrics measured, which includes Mean Reciprocal Rank (MRR), Success Rate (SR), Mean Average Precision (MAP), and Normalized Discounted Cumulative Gain (NDCG). Our baselines include the Most Popular Completion (MPC) model as well as a ranking model without our proposed features. The ranking model with the proposed features results in a $20-30\%$ improvement over the MPC model on all metrics. We obtain up to a $5\%$ improvement over the baseline ranking model for all the sessions, which goes up to about $10\%$ when we restrict to sessions that contain the user context. Moreover, our proposed features also significantly outperform text based personalization features studied in the literature before, and adding text based features on top of our proposed embedding based features results only in minor improvements.
Personalized Ranking in eCommerce Search
Apr 30, 2019
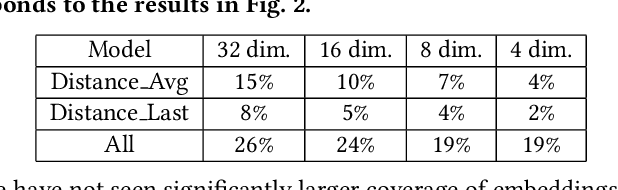
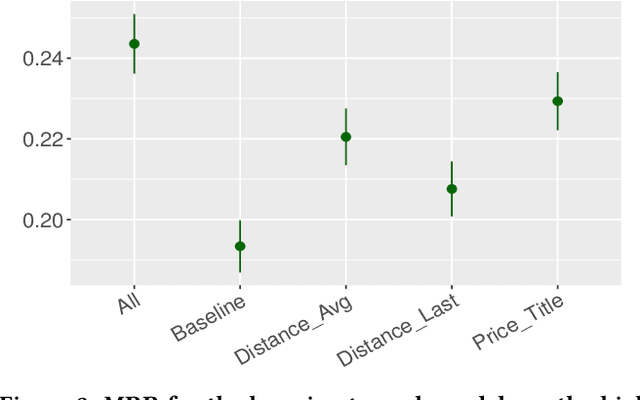
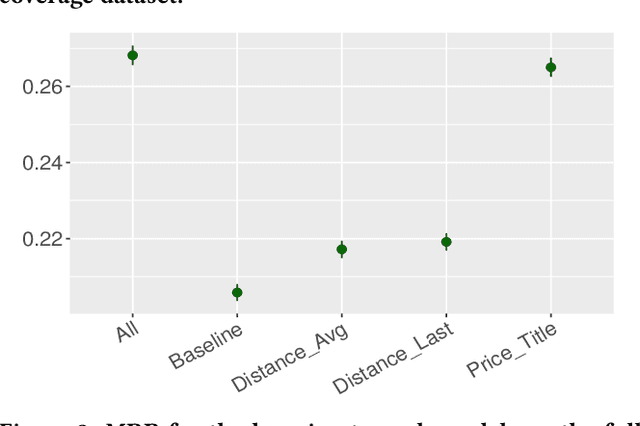
We address the problem of personalization in the context of eCommerce search. Specifically, we develop personalization ranking features that use in-session context to augment a generic ranker optimized for conversion and relevance. We use a combination of latent features learned from item co-clicks in historic sessions and content-based features that use item title and price. Personalization in search has been discussed extensively in the existing literature. The novelty of our work is combining and comparing content-based and content-agnostic features and showing that they complement each other to result in a significant improvement of the ranker. Moreover, our technique does not require an explicit re-ranking step, does not rely on learning user profiles from long term search behavior, and does not involve complex modeling of query-item-user features. Our approach captures item co-click propensity using lightweight item embeddings. We experimentally show that our technique significantly outperforms a generic ranker in terms of Mean Reciprocal Rank (MRR). We also provide anecdotal evidence for the semantic similarity captured by the item embeddings on the eBay search engine.
Direct Estimation of Position Bias for Unbiased Learning-to-Rank without Intervention
Dec 21, 2018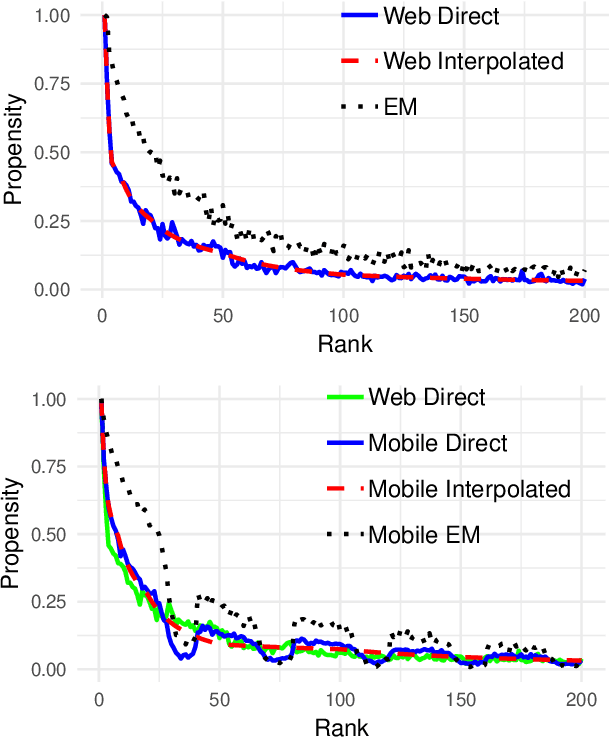
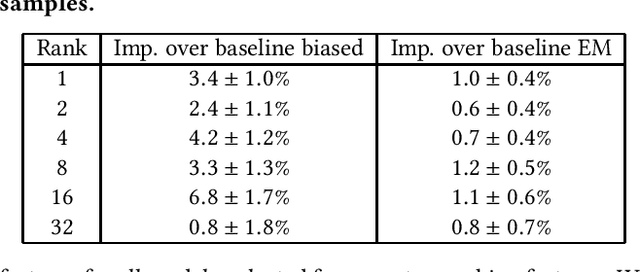
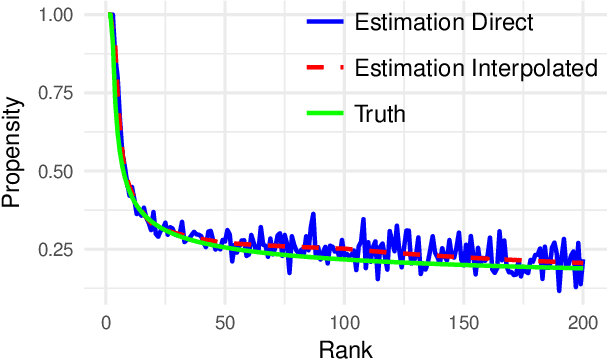
The Unbiased Learning-to-Rank framework has been recently introduced as a general approach to systematically remove biases, such as position bias, from learning-to-rank models. The method takes two steps - estimating click propensities and using them to train unbiased models. Most common methods proposed in the literature for estimating propensities involve some degree of intervention in the live search engine. An alternative approach proposed recently uses an Expectation Maximization (EM) algorithm to estimate propensities by using ranking features for estimating relevances. In this work we propose a novel method to estimate propensities which does not use any intervention in live search or rely on any ranking features. Rather, we take advantage of the fact that the same query-document pair may naturally change ranks over time. This typically occurs for eCommerce search because of change of popularity of items over time, existence of time dependent ranking features, or addition or removal of items to the index (an item getting sold or a new item being listed). However, our method is general and can be applied to any search engine for which the rank of the same document may naturally change over time for the same query. We derive a simple likelihood function that depends on propensities only, and by maximizing the likelihood we are able to get estimates of the propensities. We apply this method to eBay search data to estimate click propensities for web and mobile search. We also use simulated data to show that the method gives reliable estimates of the "true" simulated propensities. Finally, we train a simple unbiased learning-to-rank model for eBay search using the estimated propensities and show that it outperforms the baseline model (which does not correct for position bias) on our offline evaluation metrics.