 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Supervision for Walmart's Sponsored Search Retrieval via Joint Semantic Relevance and Behavioral Engagement Modeling
Apr 10, 2026Modern search systems rely on a fast first stage retriever to fetch relevant items from a massive catalog of items. Deployed search systems often use user engagement signals to supervise bi-encoder retriever training at scale, because these signals are continuously logged from real traffic and require no additional annotation effort. However, engagement is an imperfect proxy for semantic relevance. Items may receive interactions due to popularity, promotion, attractive visuals, titles, or price, despite weak query-item relevance. These limitations are further accentuated in Walmart's e-commerce sponsored search. User engagement on ad items is often structurally sparse because the frequency with which an ad is shown depends on factors beyond relevance such as whether the advertiser is currently running that ad, the outcome of the auction for available ad slots, bid competitiveness, and advertiser budget. Thus, even highly relevant query ad pairs can have limited engagement signals simply due to limited impressions. We propose a bi-encoder training framework for Walmart's sponsored search retrieval in e-commerce that uses semantic relevance as the primary supervision signal, with engagement used only as a preference signal among relevant items. Concretely, we construct a context-rich training target by combining 1. graded relevance labels from a cascade of cross-encoder teacher models, 2. a multichannel retrieval prior score derived from the rank positions and cross-channel agreement of retrieval systems running in production, and 3. user engagement applied only to semantically relevant items to refine preferences. Our approach outperforms the current production system in both offline evaluation and online AB tests, yielding consistent gains in average relevance and NDCG.
Unified Supervision for Walmarts Sponsored Search Retrieval via Joint Semantic Relevance and Behavioral Engagement Modeling
Apr 09, 2026Modern search systems rely on a fast first stage retriever to fetch relevant items from a massive catalog of items. Deployed search systems often use user engagement signals to supervise bi-encoder retriever training at scale, because these signals are continuously logged from real traffic and require no additional annotation effort. However, engagement is an imperfect proxy for semantic relevance. Items may receive interactions due to popularity, promotion, attractive visuals, titles, or price, despite weak query-item relevance. These limitations are further accentuated in Walmart's e-commerce sponsored search. User engagement on ad items is often structurally sparse because the frequency with which an ad is shown depends on factors beyond relevance such as whether the advertiser is currently running that ad, the outcome of the auction for available ad slots, bid competitiveness, and advertiser budget. Thus, even highly relevant query ad pairs can have limited engagement signals simply due to limited impressions. We propose a bi-encoder training framework for Walmart's sponsored search retrieval in e-commerce that uses semantic relevance as the primary supervision signal, with engagement used only as a preference signal among relevant items. Concretely, we construct a context-rich training target by combining 1. graded relevance labels from a cascade of cross-encoder teacher models, 2. a multichannel retrieval prior score derived from the rank positions and cross-channel agreement of retrieval systems running in production, and 3. user engagement applied only to semantically relevant items to refine preferences. Our approach outperforms the current production system in both offline evaluation and online AB tests, yielding consistent gains in average relevance and NDCG.
Learning Image Information for eCommerce Queries
Apr 29, 2019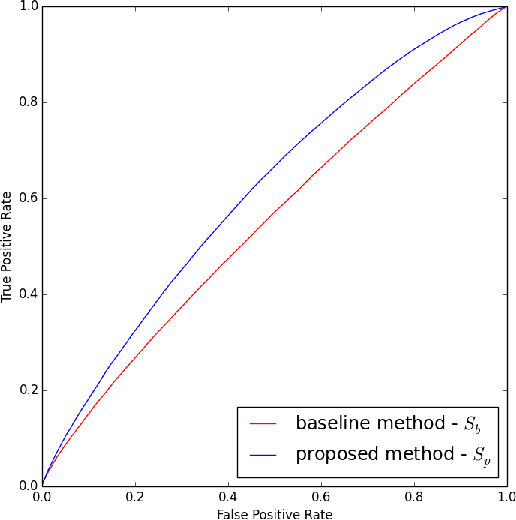

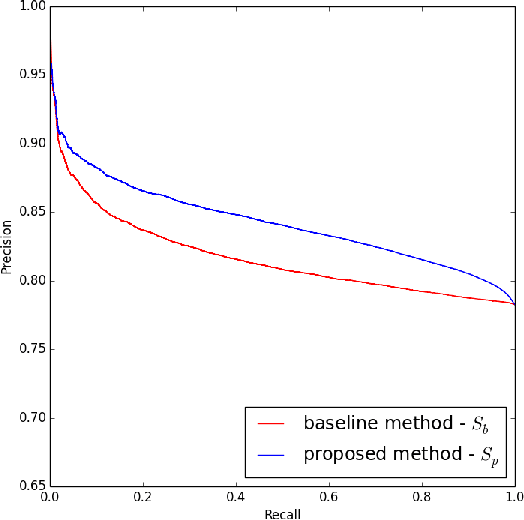
Computing similarity between a query and a document is fundamental in any information retrieval system. In search engines, computing query-document similarity is an essential step in both retrieval and ranking stages. In eBay search, document is an item and the query-item similarity can be computed by comparing different facets of the query-item pair. Query text can be compared with the text of the item title. Likewise, a category constraint applied on the query can be compared with the listing category of the item. However, images are one signal that are usually present in the items but are not present in the query. Images are one of the most intuitive signals used by users to determine the relevance of the item given a query. Including this signal in estimating similarity between the query-item pair is likely to improve the relevance of the search engine. We propose a novel way of deriving image information for queries. We attempt to learn image information for queries from item images instead of generating explicit image features or an image for queries. We use canonical correlation analysis (CCA) to learn a new subspace where projecting the original data will give us a new query and item representation. We hypothesize that this new query representation will also have image information about the query. We estimate the query-item similarity using a vector space model and report the performance of the proposed method on eBay's search data. We show 11.89\% relevance improvement over the baseline using area under the receiver operating characteristic curve (AUROC) as the evaluation metric. We also show 3.1\% relevance improvement over the baseline with area under the precision recall curve (AUPRC) .
Direct Estimation of Position Bias for Unbiased Learning-to-Rank without Intervention
Dec 21, 2018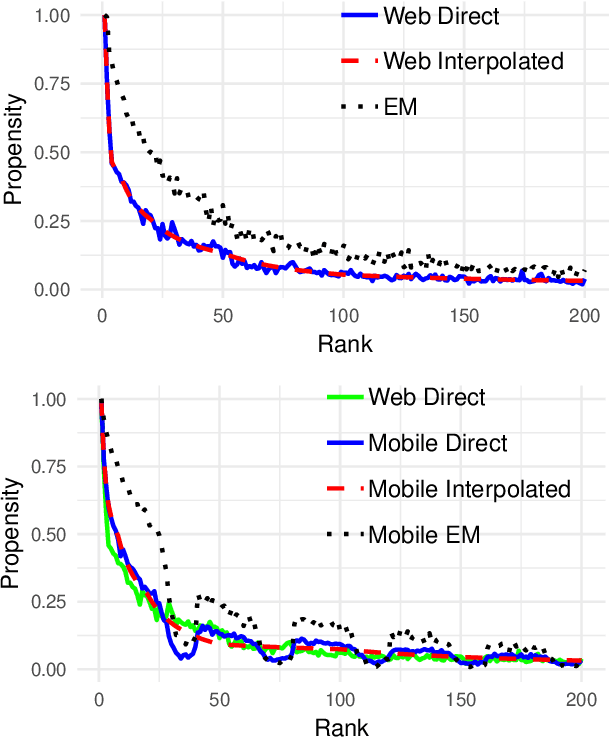
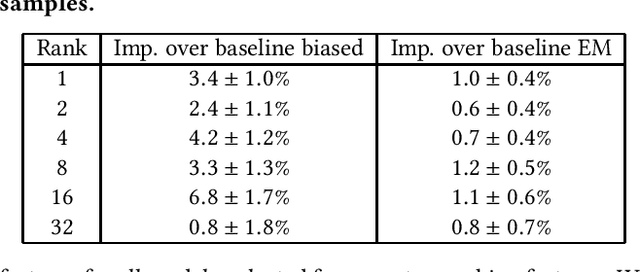
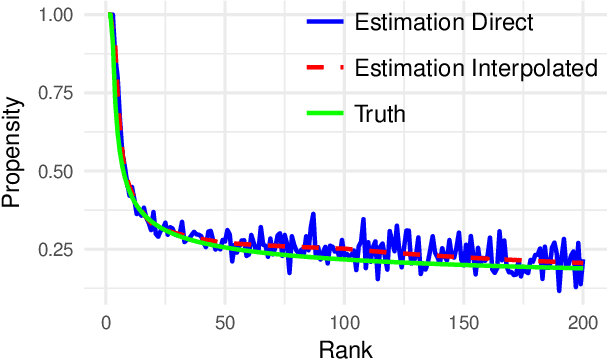
The Unbiased Learning-to-Rank framework has been recently introduced as a general approach to systematically remove biases, such as position bias, from learning-to-rank models. The method takes two steps - estimating click propensities and using them to train unbiased models. Most common methods proposed in the literature for estimating propensities involve some degree of intervention in the live search engine. An alternative approach proposed recently uses an Expectation Maximization (EM) algorithm to estimate propensities by using ranking features for estimating relevances. In this work we propose a novel method to estimate propensities which does not use any intervention in live search or rely on any ranking features. Rather, we take advantage of the fact that the same query-document pair may naturally change ranks over time. This typically occurs for eCommerce search because of change of popularity of items over time, existence of time dependent ranking features, or addition or removal of items to the index (an item getting sold or a new item being listed). However, our method is general and can be applied to any search engine for which the rank of the same document may naturally change over time for the same query. We derive a simple likelihood function that depends on propensities only, and by maximizing the likelihood we are able to get estimates of the propensities. We apply this method to eBay search data to estimate click propensities for web and mobile search. We also use simulated data to show that the method gives reliable estimates of the "true" simulated propensities. Finally, we train a simple unbiased learning-to-rank model for eBay search using the estimated propensities and show that it outperforms the baseline model (which does not correct for position bias) on our offline evaluation metrics.
Credit Card Fraud Detection in e-Commerce: An Outlier Detection Approach
Nov 06, 2018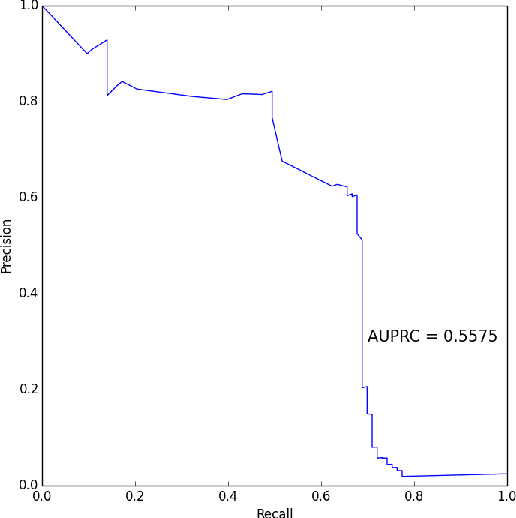

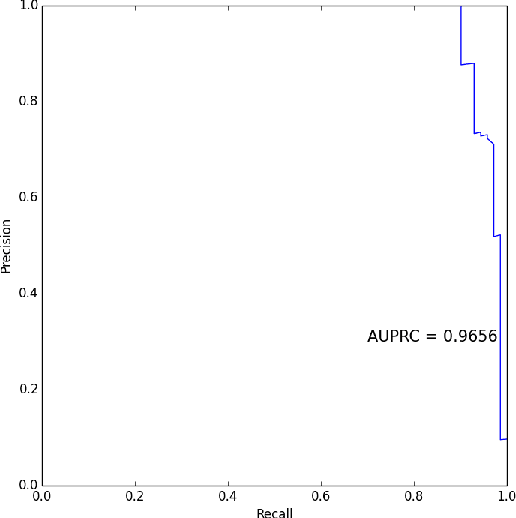

Often the challenge associated with tasks like fraud and spam detection is the lack of all likely patterns needed to train suitable supervised learning models. This problem accentuates when the fraudulent patterns are not only scarce, they also change over time. Change in fraudulent pattern is because fraudsters continue to innovate novel ways to circumvent measures put in place to prevent fraud. Limited data and continuously changing patterns makes learning significantly difficult. We hypothesize that good behavior does not change with time and data points representing good behavior have consistent spatial signature under different groupings. Based on this hypothesis we are proposing an approach that detects outliers in large data sets by assigning a consistency score to each data point using an ensemble of clustering methods. Our main contribution is proposing a novel method that can detect outliers in large datasets and is robust to changing patterns. We also argue that area under the ROC curve, although a commonly used metric to evaluate outlier detection methods is not the right metric. Since outlier detection problems have a skewed distribution of classes, precision-recall curves are better suited because precision compares false positives to true positives (outliers) rather than true negatives (inliers) and therefore is not affected by the problem of class imbalance. We show empirically that area under the precision-recall curve is a better than ROC as an evaluation metric. The proposed approach is tested on the modified version of the Landsat satellite dataset, the modified version of the ann-thyroid dataset and a large real world credit card fraud detection dataset available through Kaggle where we show significant improvement over the baseline methods.
Outlier Detection by Consistent Data Selection Method
Aug 21, 2018



Often the challenge associated with tasks like fraud and spam detection[1] is the lack of all likely patterns needed to train suitable supervised learning models. In order to overcome this limitation, such tasks are attempted as outlier or anomaly detection tasks. We also hypothesize that out- liers have behavioral patterns that change over time. Limited data and continuously changing patterns makes learning significantly difficult. In this work we are proposing an approach that detects outliers in large data sets by relying on data points that are consistent. The primary contribution of this work is that it will quickly help retrieve samples for both consistent and non-outlier data sets and is also mindful of new outlier patterns. No prior knowledge of each set is required to extract the samples. The method consists of two phases, in the first phase, consistent data points (non- outliers) are retrieved by an ensemble method of unsupervised clustering techniques and in the second phase a one class classifier trained on the consistent data point set is ap- plied on the remaining sample set to identify the outliers. The approach is tested on three publicly available data sets and the performance scores are competitive.
Spelling Correction as a Foreign Language
May 21, 2017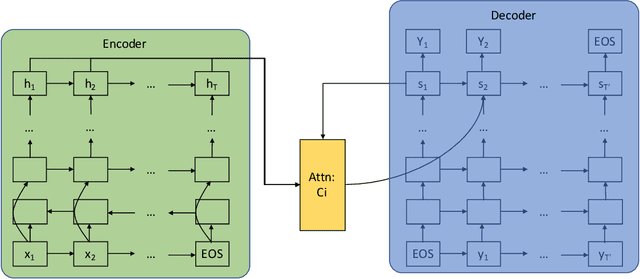

In this paper, we reformulated the spell correction problem as a machine translation task under the encoder-decoder framework. This reformulation enabled us to use a single model for solving the problem that is traditionally formulated as learning a language model and an error model. This model employs multi-layer recurrent neural networks as an encoder and a decoder. We demonstrate the effectiveness of this model using an internal dataset, where the training data is automatically obtained from user logs. The model offers competitive performance as compared to the state of the art methods but does not require any feature engineering nor hand tuning between models.