 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reliable ML Feature Engineering via Planning in Constrained-Topology of LLM Agents
Jan 15, 2026Recent advances in code generation models have unlocked unprecedented opportunities for automating feature engineering, yet their adoption in real-world ML teams remains constrained by critical challenges: (i) the scarcity of datasets capturing the iterative and complex coding processes of production-level feature engineering, (ii) limited integration and personalization of widely used coding agents, such as CoPilot and Devin, with a team's unique tools, codebases, workflows, and practices, and (iii) suboptimal human-AI collaboration due to poorly timed or insufficient feedback. We address these challenges with a planner-guided, constrained-topology multi-agent framework that generates code for repositories in a multi-step fashion. The LLM-powered planner leverages a team's environment, represented as a graph, to orchestrate calls to available agents, generate context-aware prompts, and use downstream failures to retroactively correct upstream artifacts. It can request human intervention at critical steps, ensuring generated code is reliable, maintainable, and aligned with team expectations. On a novel in-house dataset, our approach achieves 38% and 150% improvement in the evaluation metric over manually crafted and unplanned workflows respectively. In practice, when building features for recommendation models serving over 120 million users, our approach has delivered real-world impact by reducing feature engineering cycles from three weeks to a single day.
Credit Card Fraud Detection in e-Commerce: An Outlier Detection Approach
Nov 06, 2018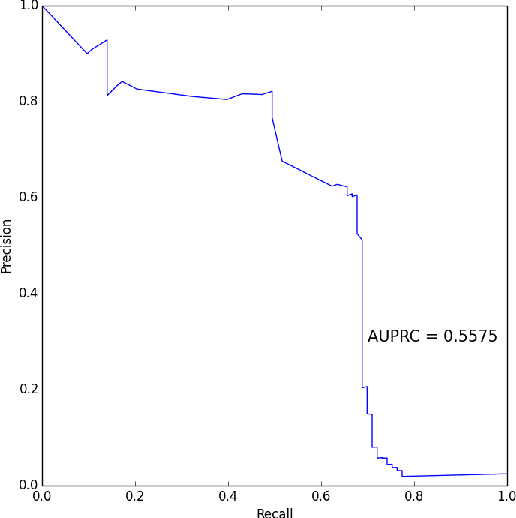

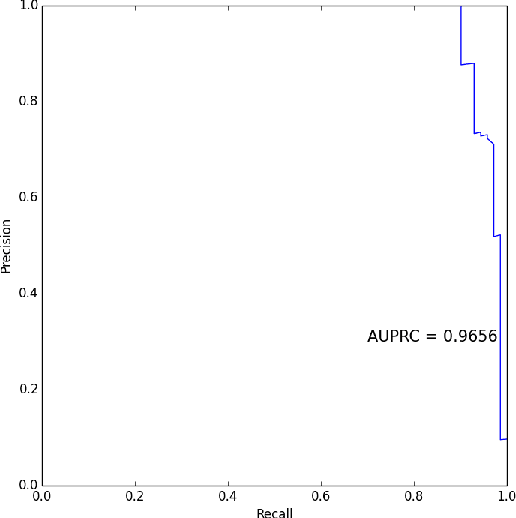

Often the challenge associated with tasks like fraud and spam detection is the lack of all likely patterns needed to train suitable supervised learning models. This problem accentuates when the fraudulent patterns are not only scarce, they also change over time. Change in fraudulent pattern is because fraudsters continue to innovate novel ways to circumvent measures put in place to prevent fraud. Limited data and continuously changing patterns makes learning significantly difficult. We hypothesize that good behavior does not change with time and data points representing good behavior have consistent spatial signature under different groupings. Based on this hypothesis we are proposing an approach that detects outliers in large data sets by assigning a consistency score to each data point using an ensemble of clustering methods. Our main contribution is proposing a novel method that can detect outliers in large datasets and is robust to changing patterns. We also argue that area under the ROC curve, although a commonly used metric to evaluate outlier detection methods is not the right metric. Since outlier detection problems have a skewed distribution of classes, precision-recall curves are better suited because precision compares false positives to true positives (outliers) rather than true negatives (inliers) and therefore is not affected by the problem of class imbalance. We show empirically that area under the precision-recall curve is a better than ROC as an evaluation metric. The proposed approach is tested on the modified version of the Landsat satellite dataset, the modified version of the ann-thyroid dataset and a large real world credit card fraud detection dataset available through Kaggle where we show significant improvement over the baseline methods.
Outlier Detection by Consistent Data Selection Method
Aug 21, 2018



Often the challenge associated with tasks like fraud and spam detection[1] is the lack of all likely patterns needed to train suitable supervised learning models. In order to overcome this limitation, such tasks are attempted as outlier or anomaly detection tasks. We also hypothesize that out- liers have behavioral patterns that change over time. Limited data and continuously changing patterns makes learning significantly difficult. In this work we are proposing an approach that detects outliers in large data sets by relying on data points that are consistent. The primary contribution of this work is that it will quickly help retrieve samples for both consistent and non-outlier data sets and is also mindful of new outlier patterns. No prior knowledge of each set is required to extract the samples. The method consists of two phases, in the first phase, consistent data points (non- outliers) are retrieved by an ensemble method of unsupervised clustering techniques and in the second phase a one class classifier trained on the consistent data point set is ap- plied on the remaining sample set to identify the outliers. The approach is tested on three publicly available data sets and the performance scores are competitive.