 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCredit Card Fraud Detection in e-Commerce: An Outlier Detection Approach
Paper and Code
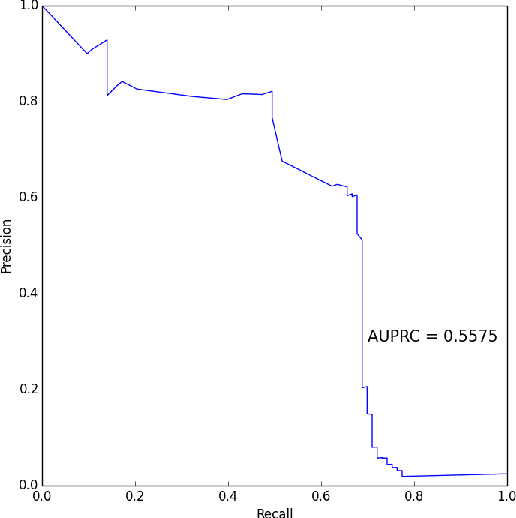

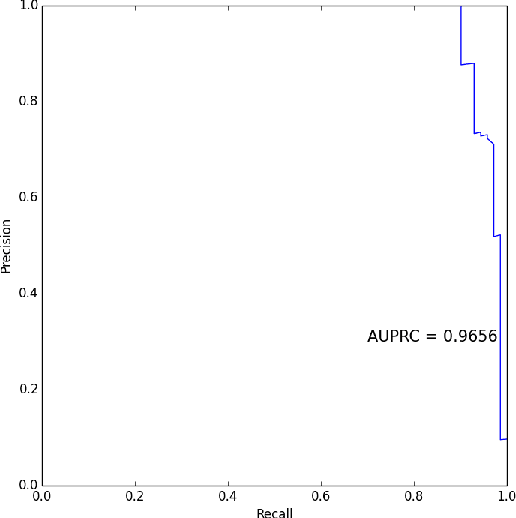

Often the challenge associated with tasks like fraud and spam detection is the lack of all likely patterns needed to train suitable supervised learning models. This problem accentuates when the fraudulent patterns are not only scarce, they also change over time. Change in fraudulent pattern is because fraudsters continue to innovate novel ways to circumvent measures put in place to prevent fraud. Limited data and continuously changing patterns makes learning significantly difficult. We hypothesize that good behavior does not change with time and data points representing good behavior have consistent spatial signature under different groupings. Based on this hypothesis we are proposing an approach that detects outliers in large data sets by assigning a consistency score to each data point using an ensemble of clustering methods. Our main contribution is proposing a novel method that can detect outliers in large datasets and is robust to changing patterns. We also argue that area under the ROC curve, although a commonly used metric to evaluate outlier detection methods is not the right metric. Since outlier detection problems have a skewed distribution of classes, precision-recall curves are better suited because precision compares false positives to true positives (outliers) rather than true negatives (inliers) and therefore is not affected by the problem of class imbalance. We show empirically that area under the precision-recall curve is a better than ROC as an evaluation metric. The proposed approach is tested on the modified version of the Landsat satellite dataset, the modified version of the ann-thyroid dataset and a large real world credit card fraud detection dataset available through Kaggle where we show significant improvement over the baseline methods.