 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-level Performance Prediction for Long-form Generation Tasks
Sep 09, 2025We motivate and share a new benchmark for instance-level performance prediction of long-form generation tasks having multi-faceted, fine-grained quality metrics. Our task-, model- and metric-agnostic formulation predicts continuous evaluation metric scores given only black-box model inputs and outputs. Beyond predicting point estimates of metric scores, the benchmark also requires inferring prediction intervals to quantify uncertainty around point estimates. Evaluation spans 11 long-form datasets/tasks with multiple LLMs, baselines, and metrics per task. We show that scores can be effectively predicted across long-form generation tasks using as few as 16 training examples. Overall, we introduce a novel and useful task, a valuable benchmark to drive progress, and baselines ready for practical adoption today.
Academic Article Recommendation Using Multiple Perspectives
Jul 08, 2024



We argue that Content-based filtering (CBF) and Graph-based methods (GB) complement one another in Academic Search recommendations. The scientific literature can be viewed as a conversation between authors and the audience. CBF uses abstracts to infer authors' positions, and GB uses citations to infer responses from the audience. In this paper, we describe nine differences between CBF and GB, as well as synergistic opportunities for hybrid combinations. Two embeddings will be used to illustrate these opportunities: (1) Specter, a CBF method based on BERT-like deepnet encodings of abstracts, and (2) ProNE, a GB method based on spectral clustering of more than 200M papers and 2B citations from Semantic Scholar.
A General Model for Aggregating Annotations Across Simple, Complex, and Multi-Object Annotation Tasks
Dec 20, 2023



Human annotations are vital to supervised learning, yet annotators often disagree on the correct label, especially as annotation tasks increase in complexity. A strategy to improve label quality is to ask multiple annotators to label the same item and aggregate their labels. Many aggregation models have been proposed for categorical or numerical annotation tasks, but far less work has considered more complex annotation tasks involving open-ended, multivariate, or structured responses. While a variety of bespoke models have been proposed for specific tasks, our work is the first to introduce aggregation methods that generalize across many diverse complex tasks, including sequence labeling, translation, syntactic parsing, ranking, bounding boxes, and keypoints. This generality is achieved by devising a task-agnostic method to model distances between labels rather than the labels themselves. This article extends our prior work with investigation of three new research questions. First, how do complex annotation properties impact aggregation accuracy? Second, how should a task owner navigate the many modeling choices to maximize aggregation accuracy? Finally, what diagnoses can verify that aggregation models are specified correctly for the given data? To understand how various factors impact accuracy and to inform model selection, we conduct simulation studies and experiments on real, complex datasets. Regarding testing, we introduce unit tests for aggregation models and present a suite of such tests to ensure that a given model is not mis-specified and exhibits expected behavior. Beyond investigating these research questions above, we discuss the foundational concept of annotation complexity, present a new aggregation model as a bridge between traditional models and our own, and contribute a new semi-supervised learning method for complex label aggregation that outperforms prior work.
Measuring Annotator Agreement Generally across Complex Structured, Multi-object, and Free-text Annotation Tasks
Dec 15, 2022When annotators label data, a key metric for quality assurance is inter-annotator agreement (IAA): the extent to which annotators agree on their labels. Though many IAA measures exist for simple categorical and ordinal labeling tasks, relatively little work has considered more complex labeling tasks, such as structured, multi-object, and free-text annotations. Krippendorff's alpha, best known for use with simpler labeling tasks, does have a distance-based formulation with broader applicability, but little work has studied its efficacy and consistency across complex annotation tasks. We investigate the design and evaluation of IAA measures for complex annotation tasks, with evaluation spanning seven diverse tasks: image bounding boxes, image keypoints, text sequence tagging, ranked lists, free text translations, numeric vectors, and syntax trees. We identify the difficulty of interpretability and the complexity of choosing a distance function as key obstacles in applying Krippendorff's alpha generally across these tasks. We propose two novel, more interpretable measures, showing they yield more consistent IAA measures across tasks and annotation distance functions.
How Many Workers to Ask? Adaptive Exploration for Collecting High Quality Labels
May 19, 2016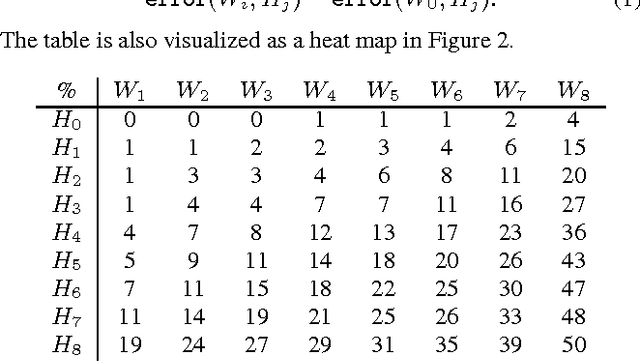
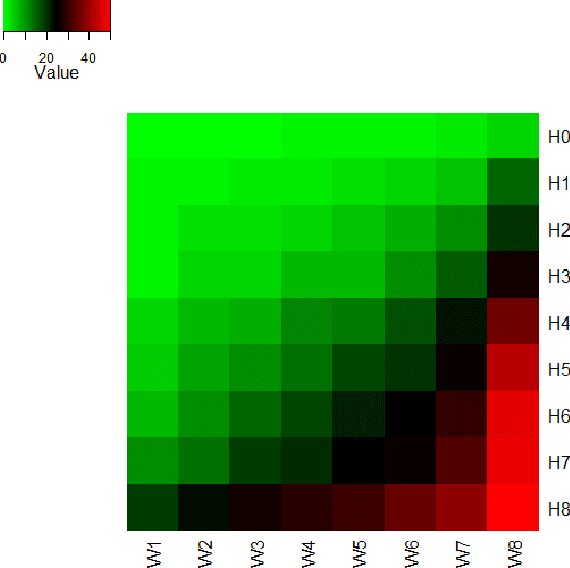
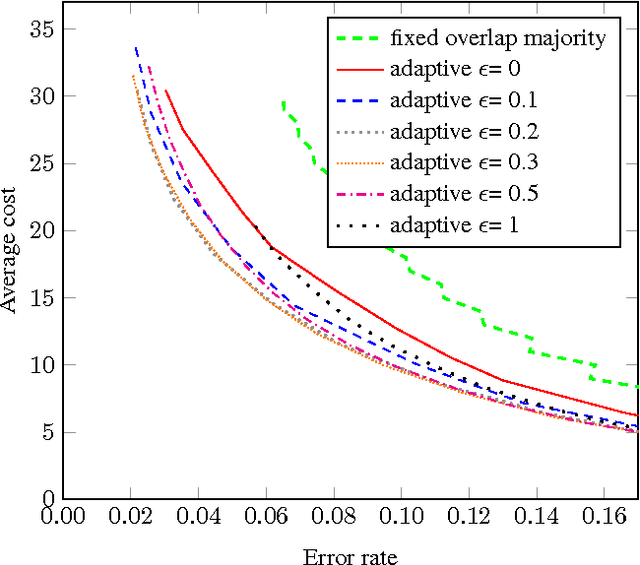
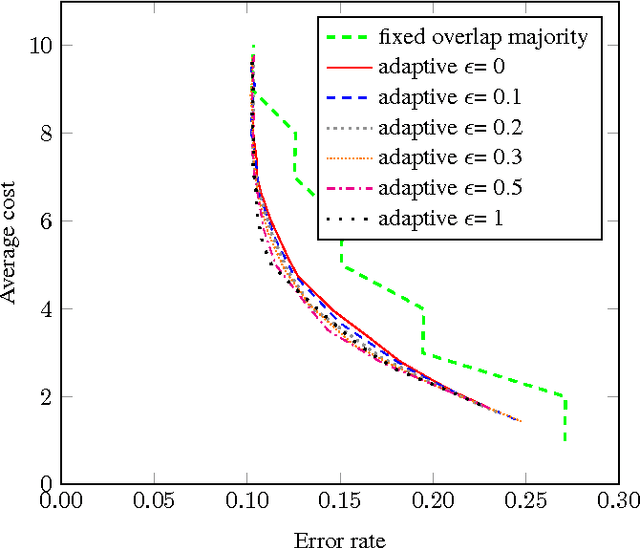
Crowdsourcing has been part of the IR toolbox as a cheap and fast mechanism to obtain labels for system development and evaluation. Successful deployment of crowdsourcing at scale involves adjusting many variables, a very important one being the number of workers needed per human intelligence task (HIT). We consider the crowdsourcing task of learning the answer to simple multiple-choice HITs, which are representative of many relevance experiments. In order to provide statistically significant results, one often needs to ask multiple workers to answer the same HIT. A stopping rule is an algorithm that, given a HIT, decides for any given set of worker answers if the system should stop and output an answer or iterate and ask one more worker. Knowing the historic performance of a worker in the form of a quality score can be beneficial in such a scenario. In this paper we investigate how to devise better stopping rules given such quality scores. We also suggest adaptive exploration as a promising approach for scalable and automatic creation of ground truth. We conduct a data analysis on an industrial crowdsourcing platform, and use the observations from this analysis to design new stopping rules that use the workers' quality scores in a non-trivial manner. We then perform a simulation based on a real-world workload, showing that our algorithm performs better than the more naive approaches.
A Data Management Approach for Dataset Selection Using Human Computation
Jul 13, 2013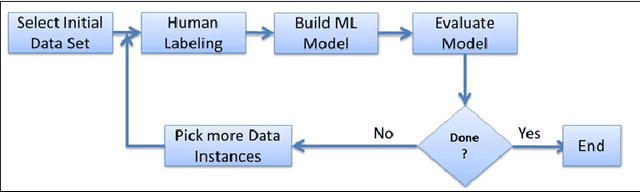
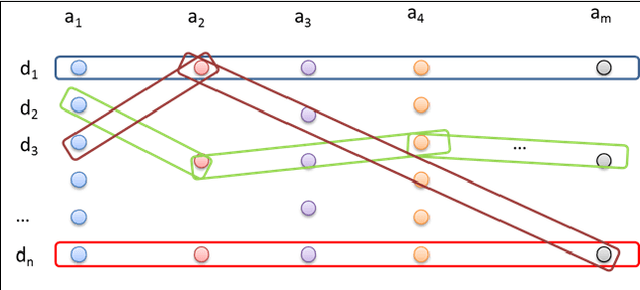
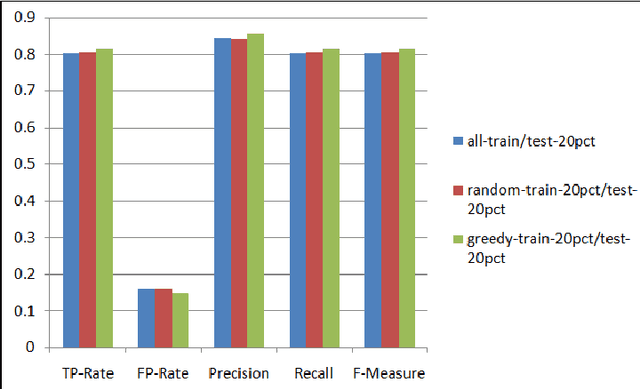
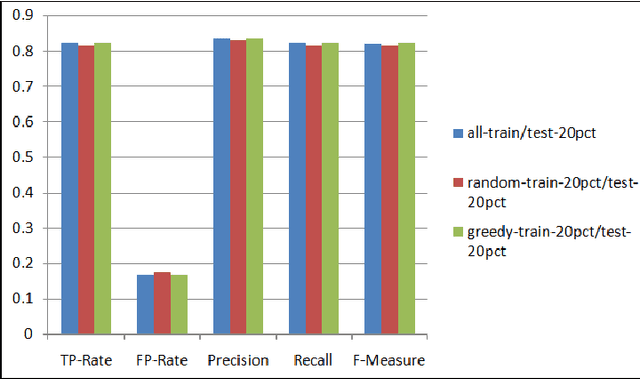
As the number of applications that use machine learning algorithms increases, the need for labeled data useful for training such algorithms intensifies. Getting labels typically involves employing humans to do the annotation, which directly translates to training and working costs. Crowdsourcing platforms have made labeling cheaper and faster, but they still involve significant costs, especially for the cases where the potential set of candidate data to be labeled is large. In this paper we describe a methodology and a prototype system aiming at addressing this challenge for Web-scale problems in an industrial setting. We discuss ideas on how to efficiently select the data to use for training of machine learning algorithms in an attempt to reduce cost. We show results achieving good performance with reduced cost by carefully selecting which instances to label. Our proposed algorithm is presented as part of a framework for managing and generating training datasets, which includes, among other components, a human computation element.
Adaptive Crowdsourcing Algorithms for the Bandit Survey Problem
May 20, 2013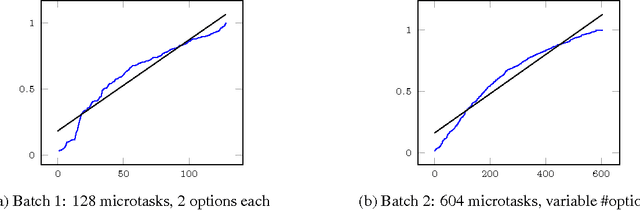
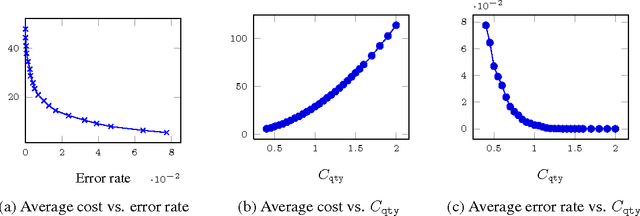
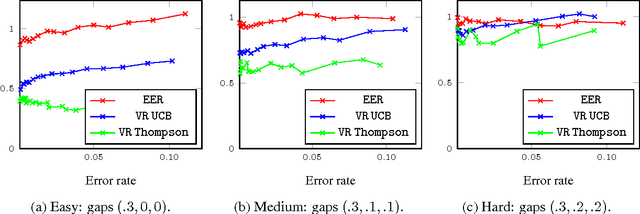
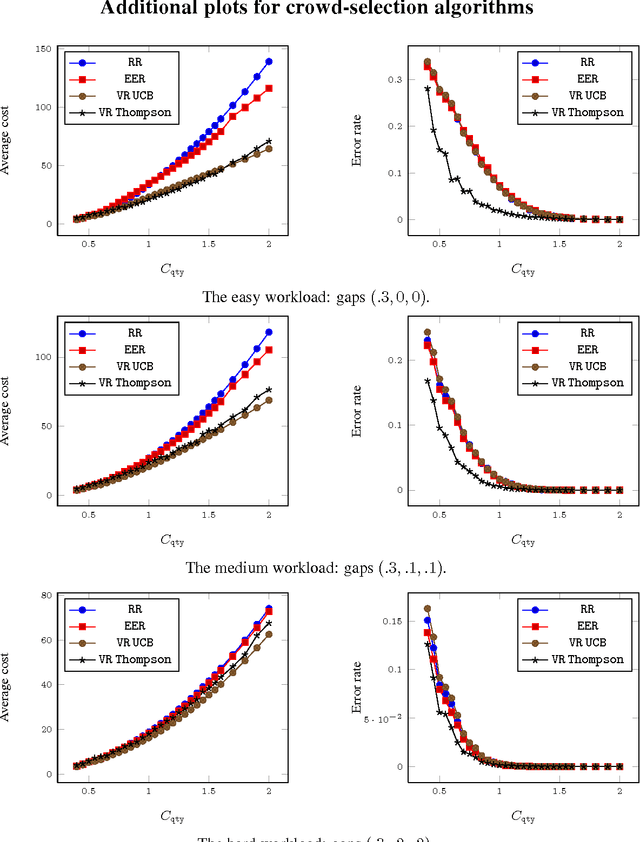
Very recently crowdsourcing has become the de facto platform for distributing and collecting human computation for a wide range of tasks and applications such as information retrieval, natural language processing and machine learning. Current crowdsourcing platforms have some limitations in the area of quality control. Most of the effort to ensure good quality has to be done by the experimenter who has to manage the number of workers needed to reach good results. We propose a simple model for adaptive quality control in crowdsourced multiple-choice tasks which we call the \emph{bandit survey problem}. This model is related to, but technically different from the well-known multi-armed bandit problem. We present several algorithms for this problem, and support them with analysis and simulations. Our approach is based in our experience conducting relevance evaluation for a large commercial search engine.