 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-level Performance Prediction for Long-form Generation Tasks
Sep 09, 2025We motivate and share a new benchmark for instance-level performance prediction of long-form generation tasks having multi-faceted, fine-grained quality metrics. Our task-, model- and metric-agnostic formulation predicts continuous evaluation metric scores given only black-box model inputs and outputs. Beyond predicting point estimates of metric scores, the benchmark also requires inferring prediction intervals to quantify uncertainty around point estimates. Evaluation spans 11 long-form datasets/tasks with multiple LLMs, baselines, and metrics per task. We show that scores can be effectively predicted across long-form generation tasks using as few as 16 training examples. Overall, we introduce a novel and useful task, a valuable benchmark to drive progress, and baselines ready for practical adoption today.
A General Model for Aggregating Annotations Across Simple, Complex, and Multi-Object Annotation Tasks
Dec 20, 2023



Human annotations are vital to supervised learning, yet annotators often disagree on the correct label, especially as annotation tasks increase in complexity. A strategy to improve label quality is to ask multiple annotators to label the same item and aggregate their labels. Many aggregation models have been proposed for categorical or numerical annotation tasks, but far less work has considered more complex annotation tasks involving open-ended, multivariate, or structured responses. While a variety of bespoke models have been proposed for specific tasks, our work is the first to introduce aggregation methods that generalize across many diverse complex tasks, including sequence labeling, translation, syntactic parsing, ranking, bounding boxes, and keypoints. This generality is achieved by devising a task-agnostic method to model distances between labels rather than the labels themselves. This article extends our prior work with investigation of three new research questions. First, how do complex annotation properties impact aggregation accuracy? Second, how should a task owner navigate the many modeling choices to maximize aggregation accuracy? Finally, what diagnoses can verify that aggregation models are specified correctly for the given data? To understand how various factors impact accuracy and to inform model selection, we conduct simulation studies and experiments on real, complex datasets. Regarding testing, we introduce unit tests for aggregation models and present a suite of such tests to ensure that a given model is not mis-specified and exhibits expected behavior. Beyond investigating these research questions above, we discuss the foundational concept of annotation complexity, present a new aggregation model as a bridge between traditional models and our own, and contribute a new semi-supervised learning method for complex label aggregation that outperforms prior work.
Measuring Annotator Agreement Generally across Complex Structured, Multi-object, and Free-text Annotation Tasks
Dec 15, 2022When annotators label data, a key metric for quality assurance is inter-annotator agreement (IAA): the extent to which annotators agree on their labels. Though many IAA measures exist for simple categorical and ordinal labeling tasks, relatively little work has considered more complex labeling tasks, such as structured, multi-object, and free-text annotations. Krippendorff's alpha, best known for use with simpler labeling tasks, does have a distance-based formulation with broader applicability, but little work has studied its efficacy and consistency across complex annotation tasks. We investigate the design and evaluation of IAA measures for complex annotation tasks, with evaluation spanning seven diverse tasks: image bounding boxes, image keypoints, text sequence tagging, ranked lists, free text translations, numeric vectors, and syntax trees. We identify the difficulty of interpretability and the complexity of choosing a distance function as key obstacles in applying Krippendorff's alpha generally across these tasks. We propose two novel, more interpretable measures, showing they yield more consistent IAA measures across tasks and annotation distance functions.
Reuse of Neural Modules for General Video Game Playing
Dec 04, 2015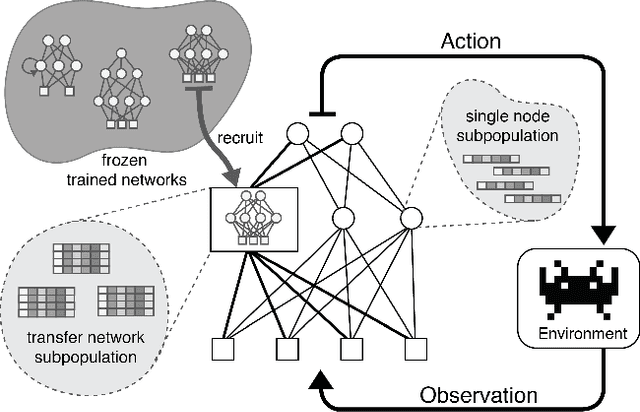
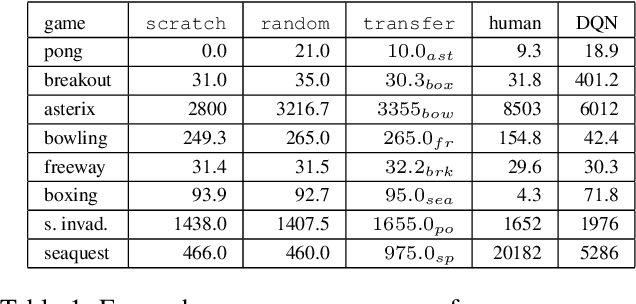
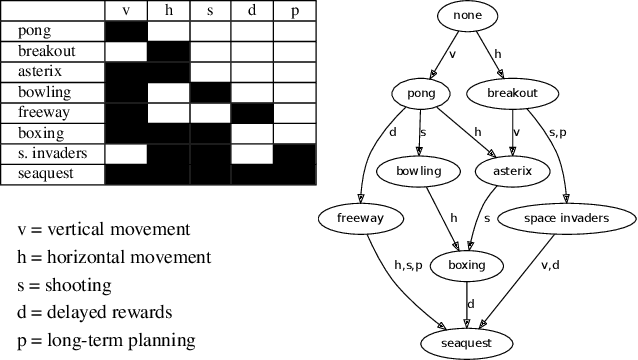
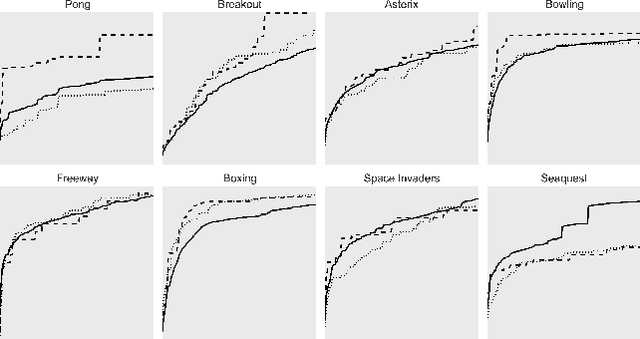
A general approach to knowledge transfer is introduced in which an agent controlled by a neural network adapts how it reuses existing networks as it learns in a new domain. Networks trained for a new domain can improve their performance by routing activation selectively through previously learned neural structure, regardless of how or for what it was learned. A neuroevolution implementation of this approach is presented with application to high-dimensional sequential decision-making domains. This approach is more general than previous approaches to neural transfer for reinforcement learning. It is domain-agnostic and requires no prior assumptions about the nature of task relatedness or mappings. The method is analyzed in a stochastic version of the Arcade Learning Environment, demonstrating that it improves performance in some of the more complex Atari 2600 games, and that the success of transfer can be predicted based on a high-level characterization of game dynamics.