 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReuse of Neural Modules for General Video Game Playing
Paper and Code
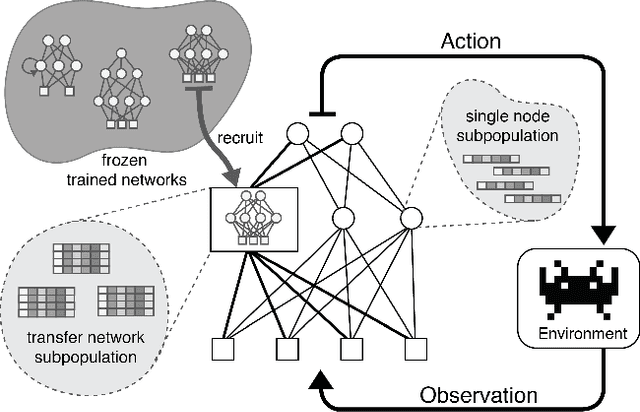
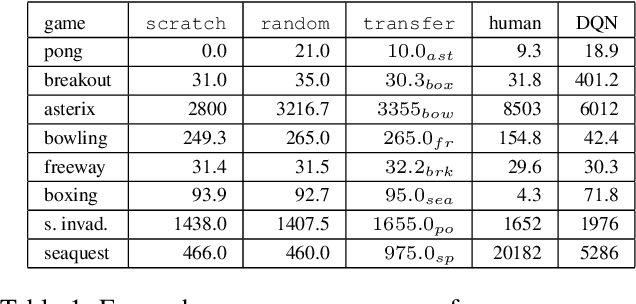
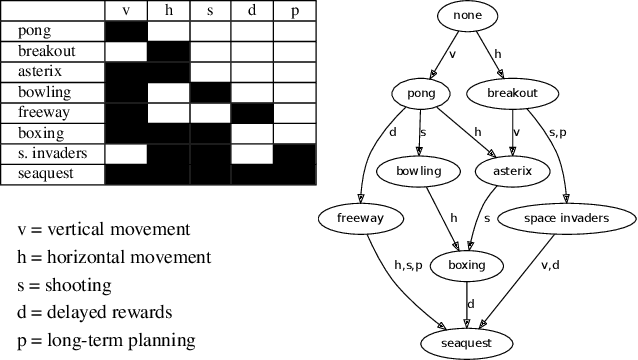
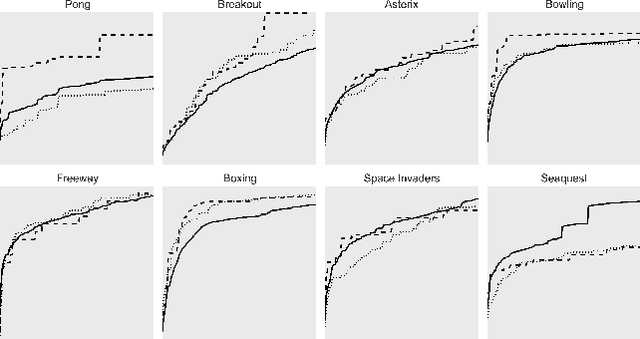
A general approach to knowledge transfer is introduced in which an agent controlled by a neural network adapts how it reuses existing networks as it learns in a new domain. Networks trained for a new domain can improve their performance by routing activation selectively through previously learned neural structure, regardless of how or for what it was learned. A neuroevolution implementation of this approach is presented with application to high-dimensional sequential decision-making domains. This approach is more general than previous approaches to neural transfer for reinforcement learning. It is domain-agnostic and requires no prior assumptions about the nature of task relatedness or mappings. The method is analyzed in a stochastic version of the Arcade Learning Environment, demonstrating that it improves performance in some of the more complex Atari 2600 games, and that the success of transfer can be predicted based on a high-level characterization of game dynamics.