 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Data Management Approach for Dataset Selection Using Human Computation
Paper and Code
Jul 13, 2013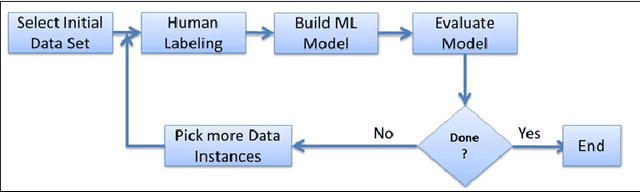
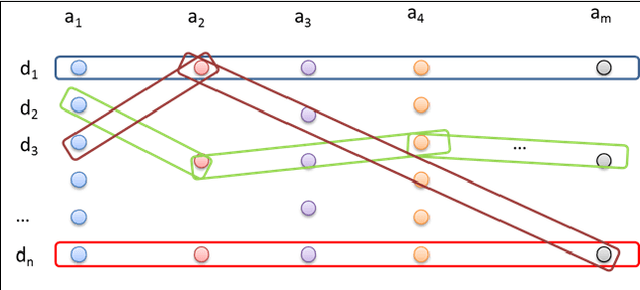
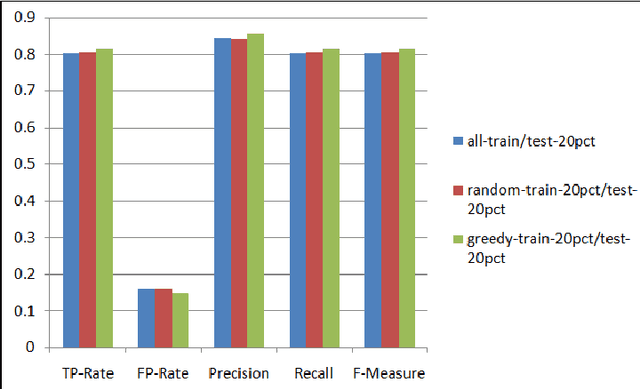
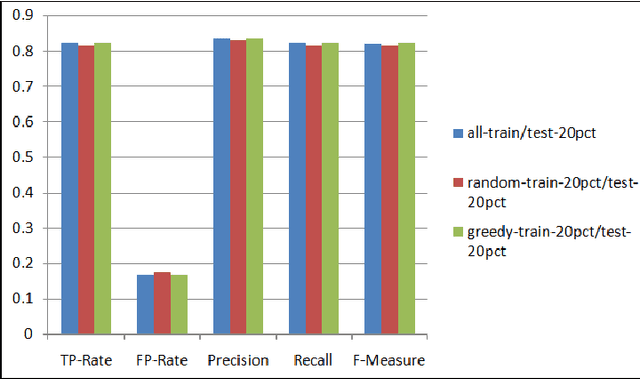
As the number of applications that use machine learning algorithms increases, the need for labeled data useful for training such algorithms intensifies. Getting labels typically involves employing humans to do the annotation, which directly translates to training and working costs. Crowdsourcing platforms have made labeling cheaper and faster, but they still involve significant costs, especially for the cases where the potential set of candidate data to be labeled is large. In this paper we describe a methodology and a prototype system aiming at addressing this challenge for Web-scale problems in an industrial setting. We discuss ideas on how to efficiently select the data to use for training of machine learning algorithms in an attempt to reduce cost. We show results achieving good performance with reduced cost by carefully selecting which instances to label. Our proposed algorithm is presented as part of a framework for managing and generating training datasets, which includes, among other components, a human computation element.