 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeware of Overestimated Decoding Performance Arising from Temporal Autocorrelations in Electroencephalogram Signals
May 27, 2024



Researchers have reported high decoding accuracy (>95%) using non-invasive Electroencephalogram (EEG) signals for brain-computer interface (BCI) decoding tasks like image decoding, emotion recognition, auditory spatial attention detection, etc. Since these EEG data were usually collected with well-designed paradigms in labs, the reliability and robustness of the corresponding decoding methods were doubted by some researchers, and they argued that such decoding accuracy was overestimated due to the inherent temporal autocorrelation of EEG signals. However, the coupling between the stimulus-driven neural responses and the EEG temporal autocorrelations makes it difficult to confirm whether this overestimation exists in truth. Furthermore, the underlying pitfalls behind overestimated decoding accuracy have not been fully explained due to a lack of appropriate formulation. In this work, we formulate the pitfall in various EEG decoding tasks in a unified framework. EEG data were recorded from watermelons to remove stimulus-driven neural responses. Labels were assigned to continuous EEG according to the experimental design for EEG recording of several typical datasets, and then the decoding methods were conducted. The results showed the label can be successfully decoded as long as continuous EEG data with the same label were split into training and test sets. Further analysis indicated that high accuracy of various BCI decoding tasks could be achieved by associating labels with EEG intrinsic temporal autocorrelation features. These results underscore the importance of choosing the right experimental designs and data splits in BCI decoding tasks to prevent inflated accuracies due to EEG temporal autocorrelation.
Semantic reconstruction of continuous language from MEG signals
Sep 14, 2023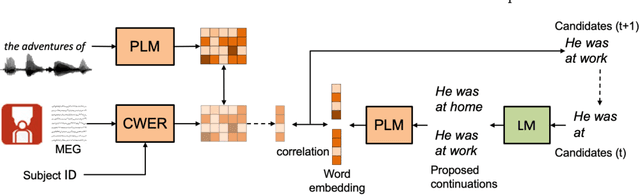
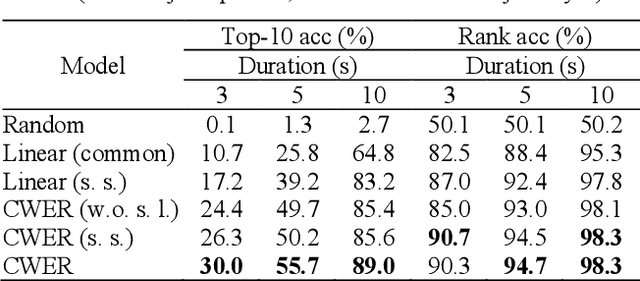
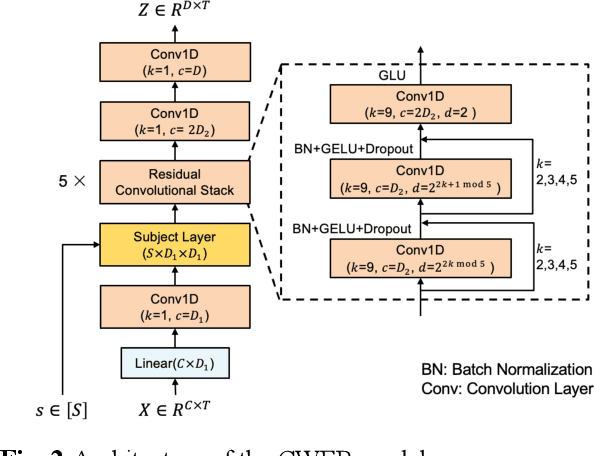
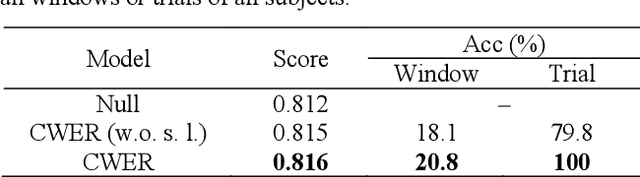
Decoding language from neural signals holds considerable theoretical and practical importance. Previous research has indicated the feasibility of decoding text or speech from invasive neural signals. However, when using non-invasive neural signals, significant challenges are encountered due to their low quality. In this study, we proposed a data-driven approach for decoding semantic of language from Magnetoencephalography (MEG) signals recorded while subjects were listening to continuous speech. First, a multi-subject decoding model was trained using contrastive learning to reconstruct continuous word embeddings from MEG data. Subsequently, a beam search algorithm was adopted to generate text sequences based on the reconstructed word embeddings. Given a candidate sentence in the beam, a language model was used to predict the subsequent words. The word embeddings of the subsequent words were correlated with the reconstructed word embedding. These correlations were then used as a measure of the probability for the next word. The results showed that the proposed continuous word embedding model can effectively leverage both subject-specific and subject-shared information. Additionally, the decoded text exhibited significant similarity to the target text, with an average BERTScore of 0.816, a score comparable to that in the previous fMRI study.