 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDNA-SE: Towards Deep Neural-Nets Assisted Semiparametric Estimation
Aug 04, 2024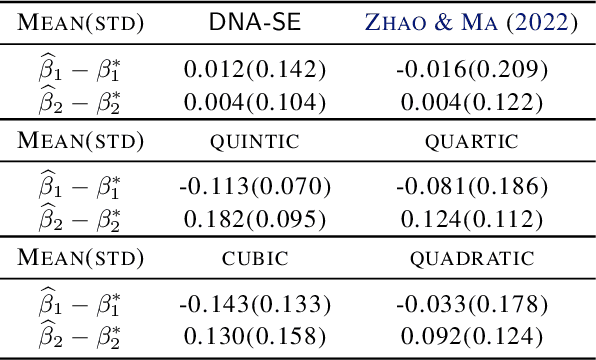
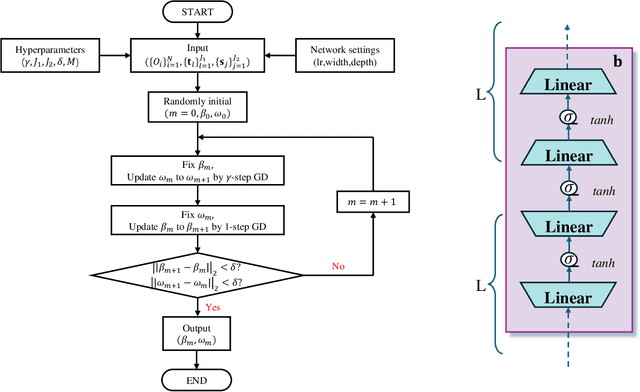

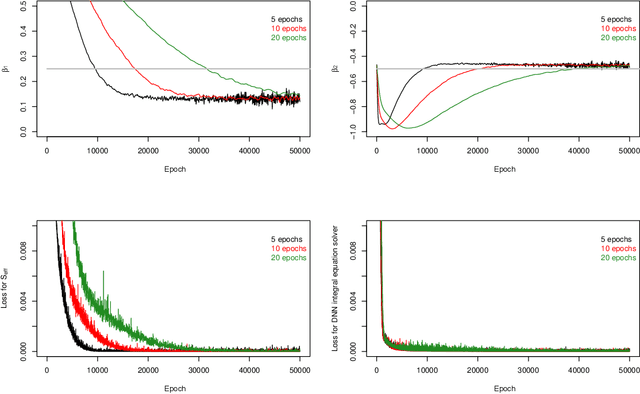
Semiparametric statistics play a pivotal role in a wide range of domains, including but not limited to missing data, causal inference, and transfer learning, to name a few. In many settings, semiparametric theory leads to (nearly) statistically optimal procedures that yet involve numerically solving Fredholm integral equations of the second kind. Traditional numerical methods, such as polynomial or spline approximations, are difficult to scale to multi-dimensional problems. Alternatively, statisticians may choose to approximate the original integral equations by ones with closed-form solutions, resulting in computationally more efficient, but statistically suboptimal or even incorrect procedures. To bridge this gap, we propose a novel framework by formulating the semiparametric estimation problem as a bi-level optimization problem; and then we develop a scalable algorithm called Deep Neural-Nets Assisted Semiparametric Estimation (DNA-SE) by leveraging the universal approximation property of Deep Neural-Nets (DNN) to streamline semiparametric procedures. Through extensive numerical experiments and a real data analysis, we demonstrate the numerical and statistical advantages of $\dnase$ over traditional methods. To the best of our knowledge, we are the first to bring DNN into semiparametric statistics as a numerical solver of integral equations in our proposed general framework.
DGCformer: Deep Graph Clustering Transformer for Multivariate Time Series Forecasting
May 14, 2024



Multivariate time series forecasting tasks are usually conducted in a channel-dependent (CD) way since it can incorporate more variable-relevant information. However, it may also involve a lot of irrelevant variables, and this even leads to worse performance than the channel-independent (CI) strategy. This paper combines the strengths of both strategies and proposes the Deep Graph Clustering Transformer (DGCformer) for multivariate time series forecasting. Specifically, it first groups these relevant variables by a graph convolutional network integrated with an autoencoder, and a former-latter masked self-attention mechanism is then considered with the CD strategy being applied to each group of variables while the CI one for different groups. Extensive experimental results on eight datasets demonstrate the superiority of our method against state-of-the-art models, and our code will be publicly available upon acceptance.