 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParaRNN: An Interpretable and Parallelizable Recurrent Neural Network for Time-Dependent Data
May 04, 2026The proliferation of large-scale and structurally complex data has spurred the integration of machine learning methods into statistical modeling. Recurrent neural networks (RNNs), a foundational class of models for time-dependent data, can be viewed as nonlinear extensions of classical autoregressive moving average models. Despite their flexibility and empirical success in machine learning, RNNs often suffer from limited interpretability and slow training, which hinders their use in statistics. This paper proposes the Parallelized RNN (ParaRNN), a novel model composed of multiple small recurrent units. ParaRNN admits an additive representation that decouples recurrent dynamics into interpretable components, whose behavior can be characterized through recurrence features. This interpretability enables its applications in nonparametric regression for time-dependent data, while the design also allows efficient parallelization. The approximation capacity and non-asymptotic prediction error bounds in a nonparametric regression setting are established for ParaRNN. Empirical results on three sequential modeling tasks further demonstrate that ParaRNN achieves performance comparable to vanilla RNNs while offering improved interpretability and efficiency.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
DGCformer: Deep Graph Clustering Transformer for Multivariate Time Series Forecasting
May 14, 2024



Multivariate time series forecasting tasks are usually conducted in a channel-dependent (CD) way since it can incorporate more variable-relevant information. However, it may also involve a lot of irrelevant variables, and this even leads to worse performance than the channel-independent (CI) strategy. This paper combines the strengths of both strategies and proposes the Deep Graph Clustering Transformer (DGCformer) for multivariate time series forecasting. Specifically, it first groups these relevant variables by a graph convolutional network integrated with an autoencoder, and a former-latter masked self-attention mechanism is then considered with the CD strategy being applied to each group of variables while the CI one for different groups. Extensive experimental results on eight datasets demonstrate the superiority of our method against state-of-the-art models, and our code will be publicly available upon acceptance.
PGformer: Proxy-Bridged Game Transformer for Multi-Person Extremely Interactive Motion Prediction
Jun 12, 2023



Multi-person motion prediction is a challenging task, especially for real-world scenarios of densely interacted persons. Most previous works have been devoted to studying the case of weak interactions (e.g., hand-shaking), which typically forecast each human pose in isolation. In this paper, we focus on motion prediction for multiple persons with extreme collaborations and attempt to explore the relationships between the highly interactive persons' motion trajectories. Specifically, a novel cross-query attention (XQA) module is proposed to bilaterally learn the cross-dependencies between the two pose sequences tailored for this situation. Additionally, we introduce and build a proxy entity to bridge the involved persons, which cooperates with our proposed XQA module and subtly controls the bidirectional information flows, acting as a motion intermediary. We then adapt these designs to a Transformer-based architecture and devise a simple yet effective end-to-end framework called proxy-bridged game Transformer (PGformer) for multi-person interactive motion prediction. The effectiveness of our method has been evaluated on the challenging ExPI dataset, which involves highly interactive actions. We show that our PGformer consistently outperforms the state-of-the-art methods in both short- and long-term predictions by a large margin. Besides, our approach can also be compatible with the weakly interacted CMU-Mocap and MuPoTS-3D datasets and achieve encouraging results. Our code will become publicly available upon acceptance.
Cross-Layer Retrospective Retrieving via Layer Attention
Feb 28, 2023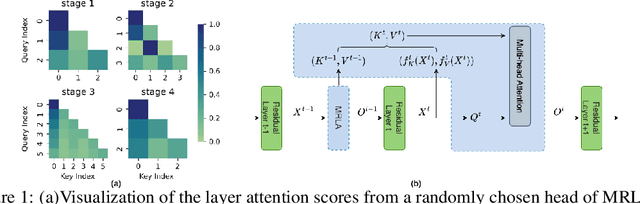
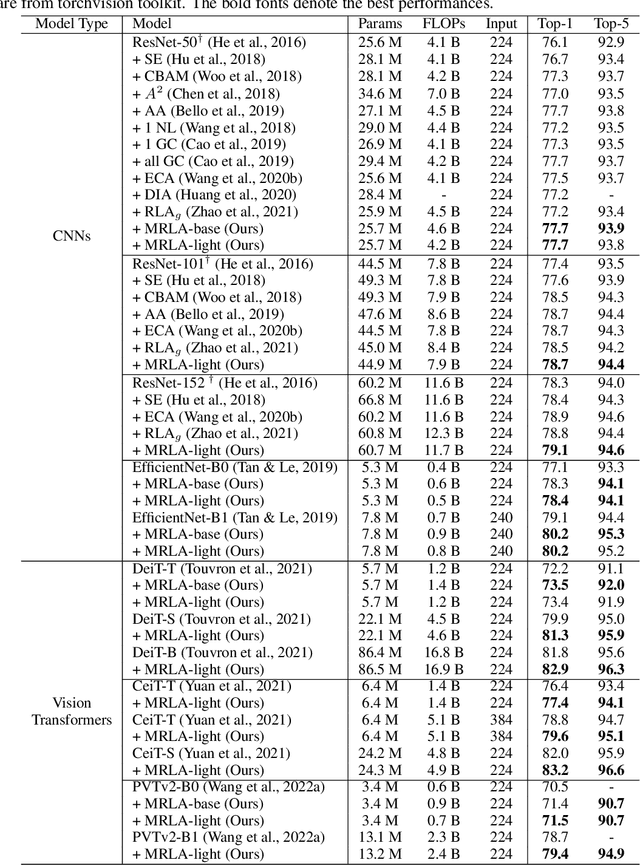
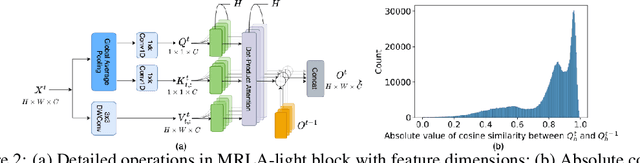
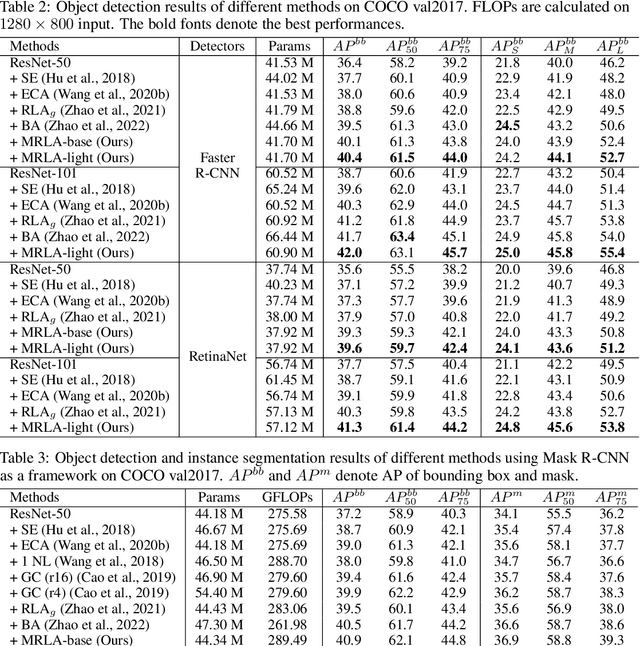
More and more evidence has shown that strengthening layer interactions can enhance the representation power of a deep neural network, while self-attention excels at learning interdependencies by retrieving query-activated information. Motivated by this, we devise a cross-layer attention mechanism, called multi-head recurrent layer attention (MRLA), that sends a query representation of the current layer to all previous layers to retrieve query-related information from different levels of receptive fields. A light-weighted version of MRLA is also proposed to reduce the quadratic computation cost. The proposed layer attention mechanism can enrich the representation power of many state-of-the-art vision networks, including CNNs and vision transformers. Its effectiveness has been extensively evaluated in image classification, object detection and instance segmentation tasks, where improvements can be consistently observed. For example, our MRLA can improve 1.6% Top-1 accuracy on ResNet-50, while only introducing 0.16M parameters and 0.07B FLOPs. Surprisingly, it can boost the performances by a large margin of 3-4% box AP and mask AP in dense prediction tasks. Our code is available at https://github.com/joyfang1106/MRLA.
A New Measure of Model Redundancy for Compressed Convolutional Neural Networks
Dec 09, 2021
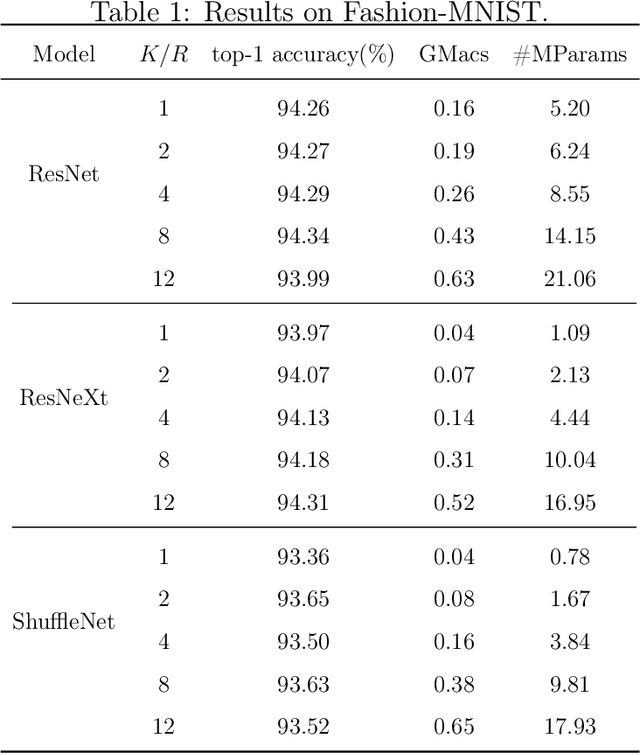
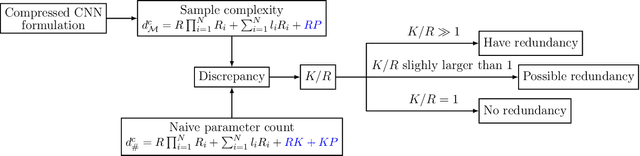
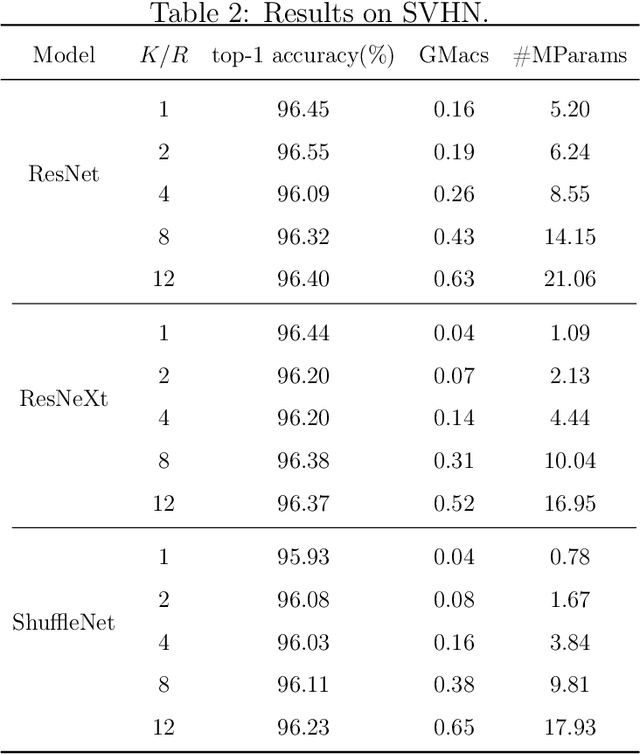
While recently many designs have been proposed to improve the model efficiency of convolutional neural networks (CNNs) on a fixed resource budget, theoretical understanding of these designs is still conspicuously lacking. This paper aims to provide a new framework for answering the question: Is there still any remaining model redundancy in a compressed CNN? We begin by developing a general statistical formulation of CNNs and compressed CNNs via the tensor decomposition, such that the weights across layers can be summarized into a single tensor. Then, through a rigorous sample complexity analysis, we reveal an important discrepancy between the derived sample complexity and the naive parameter counting, which serves as a direct indicator of the model redundancy. Motivated by this finding, we introduce a new model redundancy measure for compressed CNNs, called the $K/R$ ratio, which further allows for nonlinear activations. The usefulness of this new measure is supported by ablation studies on popular block designs and datasets.
Recurrence along Depth: Deep Convolutional Neural Networks with Recurrent Layer Aggregation
Oct 22, 2021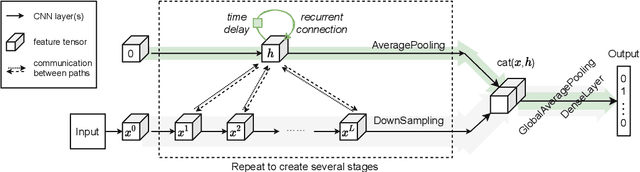
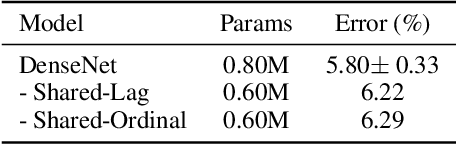
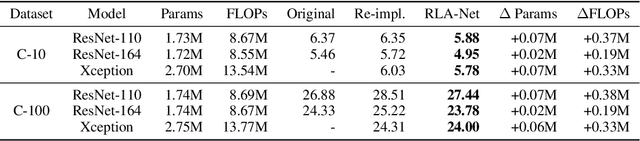
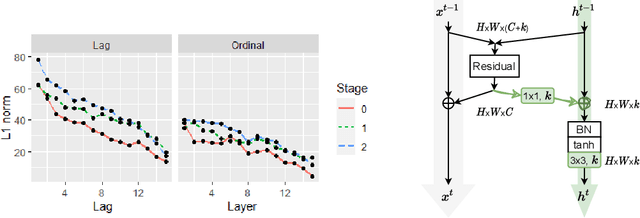
This paper introduces a concept of layer aggregation to describe how information from previous layers can be reused to better extract features at the current layer. While DenseNet is a typical example of the layer aggregation mechanism, its redundancy has been commonly criticized in the literature. This motivates us to propose a very light-weighted module, called recurrent layer aggregation (RLA), by making use of the sequential structure of layers in a deep CNN. Our RLA module is compatible with many mainstream deep CNNs, including ResNets, Xception and MobileNetV2, and its effectiveness is verified by our extensive experiments on image classification, object detection and instance segmentation tasks. Specifically, improvements can be uniformly observed on CIFAR, ImageNet and MS COCO datasets, and the corresponding RLA-Nets can surprisingly boost the performances by 2-3% on the object detection task. This evidences the power of our RLA module in helping main CNNs better learn structural information in images.
Do RNN and LSTM have Long Memory?
Jun 10, 2020
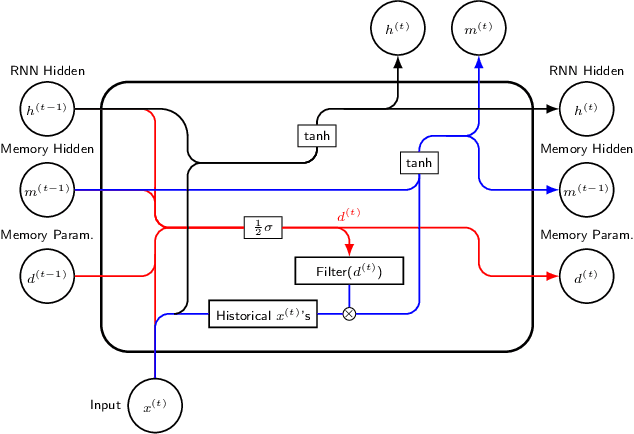
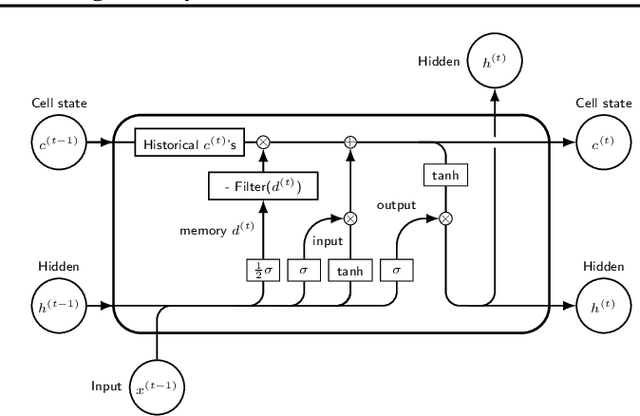
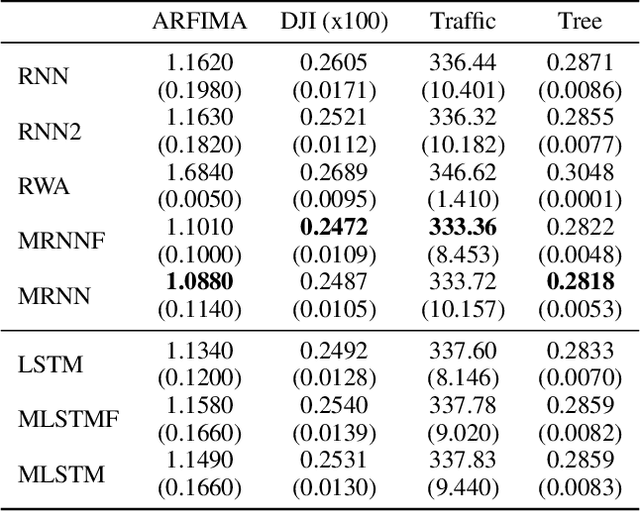
The LSTM network was proposed to overcome the difficulty in learning long-term dependence, and has made significant advancements in applications. With its success and drawbacks in mind, this paper raises the question - do RNN and LSTM have long memory? We answer it partially by proving that RNN and LSTM do not have long memory from a statistical perspective. A new definition for long memory networks is further introduced, and it requires the model weights to decay at a polynomial rate. To verify our theory, we convert RNN and LSTM into long memory networks by making a minimal modification, and their superiority is illustrated in modeling long-term dependence of various datasets.
Compact Autoregressive Network
Sep 06, 2019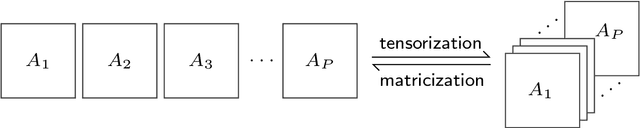
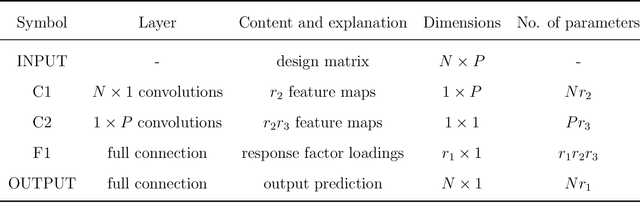
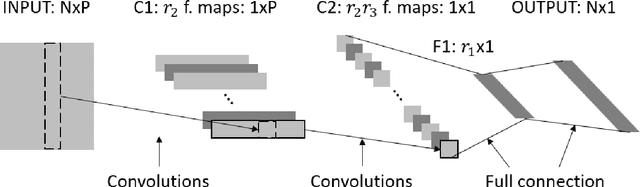
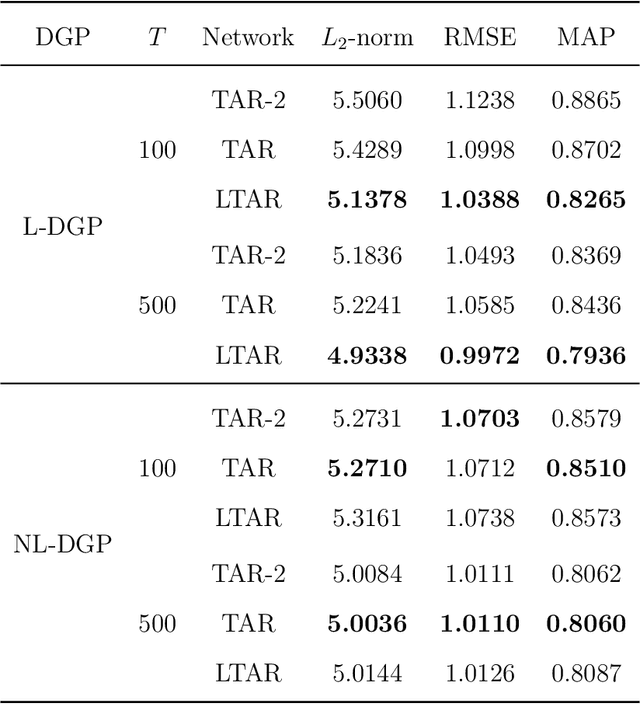
Autoregressive networks can achieve promising performance in many sequence modeling tasks with short-range dependence. However, when handling high-dimensional inputs and outputs, the huge amount of parameters in the network lead to expensive computational cost and low learning efficiency. The problem can be alleviated slightly by introducing one more narrow hidden layer to the network, but the sample size required to achieve a certain training error is still large. To address this challenge, we rearrange the weight matrices of a linear autoregressive network into a tensor form, and then make use of Tucker decomposition to represent low-rank structures. This leads to a novel compact autoregressive network, called Tucker AutoRegressive (TAR) net. Interestingly, the TAR net can be applied to sequences with long-range dependence since the dimension along the sequential order is reduced. Theoretical studies show that the TAR net improves the learning efficiency, and requires much fewer samples for model training. Experiments on synthetic and real-world datasets demonstrate the promising performance of the proposed compact network.