 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiCSI: A Binary Encoding and Fingerprint-Based Matching Algorithm for Wi-Fi Indoor Positioning
Dec 03, 2024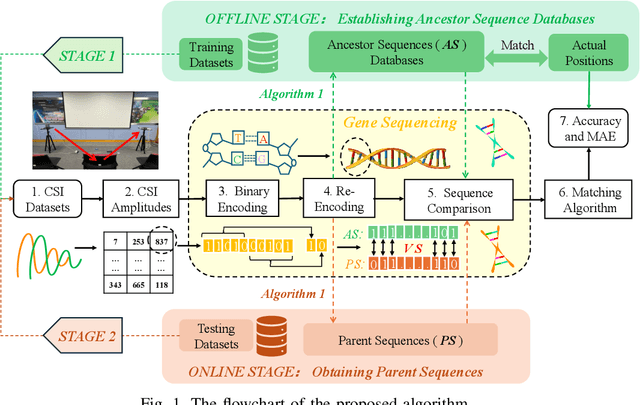
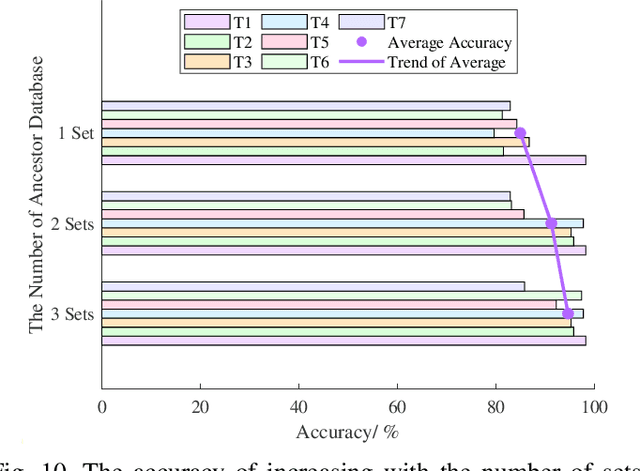
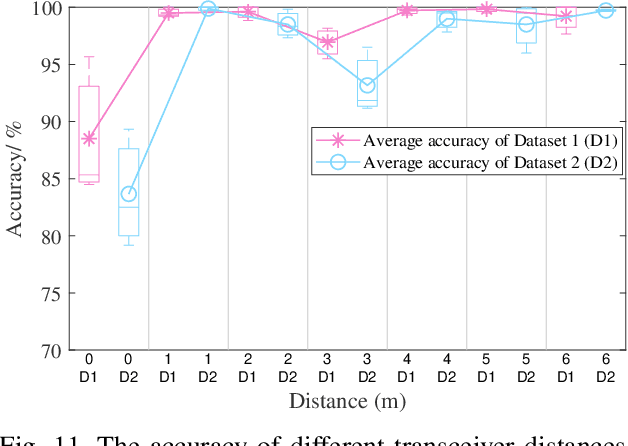
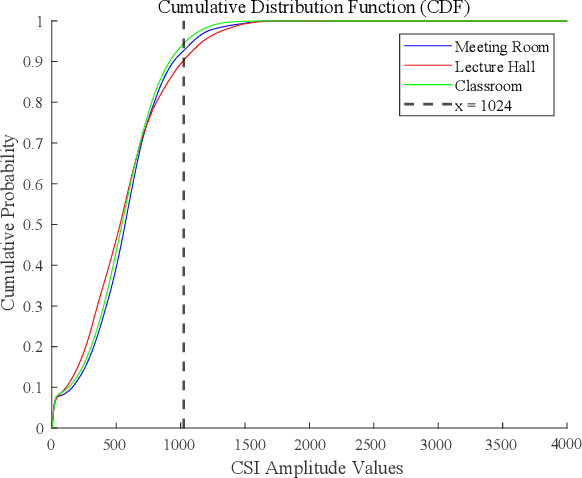
Traditional global positioning systems often underperform indoors, whereas Wi-Fi has become an effective medium for various radio sensing services. Specifically, utilizing channel state information (CSI) from Wi-Fi networks provides a non-contact method for precise indoor positioning; yet, accurately interpreting the complex CSI matrix to develop a reliable strategy for physical similarity measurement remains challenging. This paper presents BiCSI, which merges binary encoding with fingerprint-based techniques to improve position matching for detecting semi-stationary targets. Inspired by gene sequencing processes, BiCSI initially converts CSI matrices into binary sequences and employs Hamming distances to evaluate signal similarity. The results show that BiCSI achieves an average accuracy above 98% and a mean absolute error (MAE) of less than three centimeters, outperforming algorithms directly dependent on physical measurements by at least two-fold. Moreover, the proposed method for extracting feature vectors from CSI matrices as fingerprints significantly reduces data storage requirements to the kilobyte range, far below the megabytes typically required by conventional machine learning models. Additionally, the results demonstrate that the proposed algorithm adapts well to multiple physical similarity metrics, and remains robust over different time periods, enhancing its utility and versatility in various scenarios.
RSSI-Assisted CSI-Based Passenger Counting with Multiple Wi-Fi Receivers
Oct 15, 2024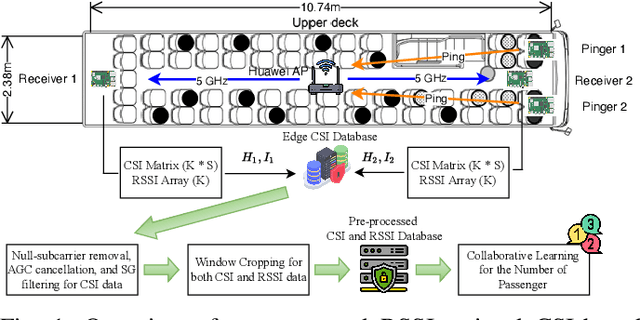
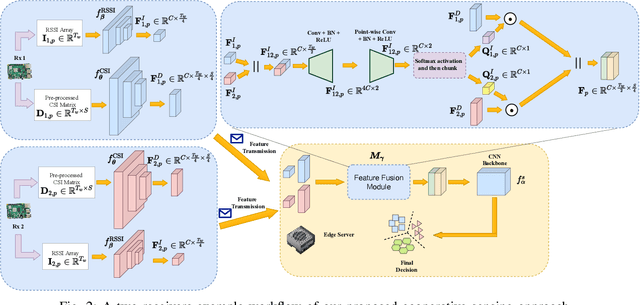
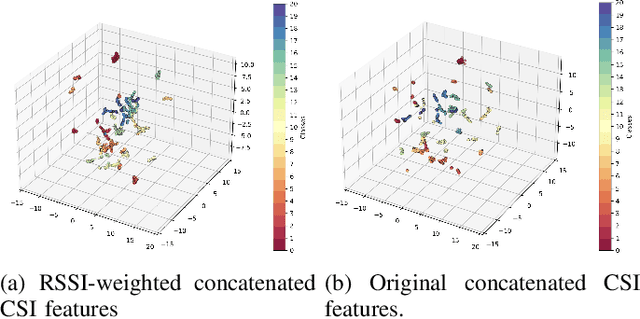
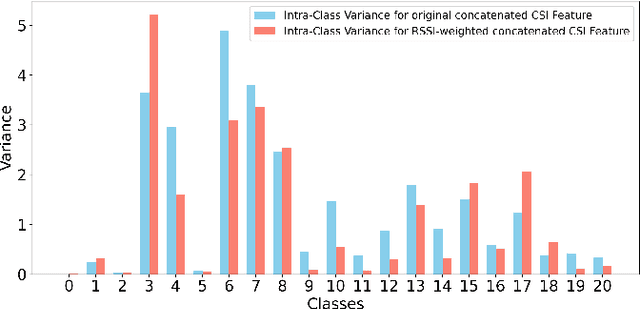
Passenger counting is crucial for public transport vehicle scheduling and traffic capacity evaluation. However, most existing methods are either costly or with low counting accuracy, leading to the recent use of Wi-Fi signals for this purpose. In this paper, we develop an efficient edge computing-based passenger counting system consists of multiple Wi-Fi receivers and an edge server. It leverages channel state information (CSI) and received signal strength indicator (RSSI) to facilitate the collaboration among multiple receivers. Specifically, we design a novel CSI feature fusion module called Adaptive RSSI-weighted CSI Feature Concatenation, which integrates locally extracted CSI and RSSI features from multiple receivers for information fusion at the edge server. Performance of our proposed system is evaluated using a real-world dataset collected from a double-decker bus in Hong Kong, with up to 20 passengers. The experimental results reveal that our system achieves an average accuracy and F1-score of over 94%, surpassing other cooperative sensing baselines by at least 2.27% in accuracy and 2.34% in F1-score.
Exemplar-based Generative Facial Editing
May 31, 2020

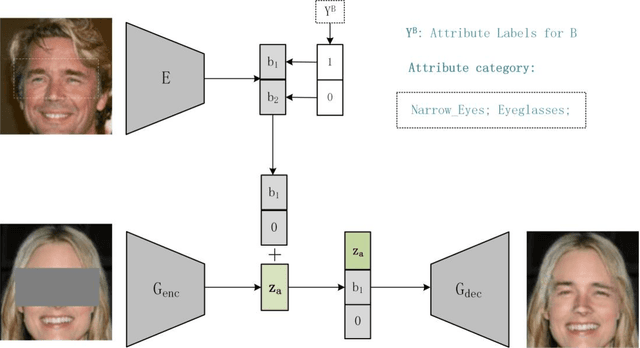

Image synthesis has witnessed substantial progress due to the increasing power of generative model. This paper we propose a novel generative approach for exemplar based facial editing in the form of the region inpainting. Our method first masks the facial editing region to eliminates the pixel constraints of the original image, then exemplar based facial editing can be achieved by learning the corresponding information from the reference image to complete the masked region. In additional, we impose the attribute labels constraint to model disentangled encodings in order to avoid undesired information being transferred from the exemplar to the original image editing region. Experimental results demonstrate our method can produce diverse and personalized face editing results and provide far more user control flexibility than nearly all existing methods.
MulGAN: Facial Attribute Editing by Exemplar
Dec 28, 2019



Recent studies on face attribute editing by exemplars have achieved promising results due to the increasing power of deep convolutional networks and generative adversarial networks. These methods encode attribute-related information in images into the predefined region of the latent feature space by employing a pair of images with opposite attributes as input to train model, the face attribute transfer between the input image and the exemplar can be achieved by exchanging their attribute-related latent feature region. However, they suffer from three limitations: (1) the model must be trained using a pair of images with opposite attributes as input; (2) weak capability of editing multiple attributes by exemplars; (3) poor quality of generating image. Instead of imposing opposite-attribute constraints on the input image in order to make the attribute information of images be encoded in the predefined region of the latent feature space, in this work we directly apply the attribute labels constraint to the predefined region of the latent feature space. Meanwhile, an attribute classification loss is employed to make the model learn to extract the attribute-related information of images into the predefined latent feature region of the corresponding attribute, which enables our method to transfer multiple attributes of the exemplar simultaneously. Besides, a novel model structure is designed to enhance attribute transfer capabilities by exemplars while improve the quality of the generated image. Experiments demonstrate the effectiveness of our model on overcoming the above three limitations by comparing with other methods on the CelebA dataset.