 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOutrigger local polynomial regression
Mar 11, 2026Standard local polynomial estimators of a nonparametric regression function employ a weighted least squares loss function that is tailored to the setting of homoscedastic Gaussian errors. We introduce the outrigger local polynomial estimator, which is designed to achieve distributional adaptivity across different conditional error distributions. It modifies a standard local polynomial estimator by employing an estimate of the conditional score function of the errors and an 'outrigger' that draws on the data in a broader local window to stabilise the influence of the conditional score estimate. Subject to smoothness and moment conditions, and only requiring consistency of the conditional score estimate, we first establish that even under the least favourable settings for the outrigger estimator, the asymptotic ratio of the worst-case local risks of the two estimators is at most $1$, with equality if and only if the conditional error distribution is Gaussian. Moreover, we prove that the outrigger estimator is minimax optimal over Hölder classes up to a multiplicative factor $A_{β,d}$, depending only on the smoothness $β\in (0,\infty)$ of the regression function and the dimension~$d$ of the covariates. When $β\in (0,1]$, we find that $A_{β,d} \leq 1.69$, with $\lim_{β\searrow 0} A_{β,d} = 1$. A further attraction of our proposal is that we do not require structural assumptions such as independence of errors and covariates, or symmetry of the conditional error distribution. Numerical results on simulated and real data validate our theoretical findings; our methodology is implemented in R and available at https://github.com/elliot-young/outrigger.
Efficient and Minimax-optimal In-context Nonparametric Regression with Transformers
Jan 21, 2026We study in-context learning for nonparametric regression with $α$-Hölder smooth regression functions, for some $α>0$. We prove that, with $n$ in-context examples and $d$-dimensional regression covariates, a pretrained transformer with $Θ(\log n)$ parameters and $Ω\bigl(n^{2α/(2α+d)}\log^3 n\bigr)$ pretraining sequences can achieve the minimax-optimal rate of convergence $O\bigl(n^{-2α/(2α+d)}\bigr)$ in mean squared error. Our result requires substantially fewer transformer parameters and pretraining sequences than previous results in the literature. This is achieved by showing that transformers are able to approximate local polynomial estimators efficiently by implementing a kernel-weighted polynomial basis and then running gradient descent.
Learning the score under shape constraints
Dec 16, 2025Score estimation has recently emerged as a key modern statistical challenge, due to its pivotal role in generative modelling via diffusion models. Moreover, it is an essential ingredient in a new approach to linear regression via convex $M$-estimation, where the corresponding error densities are projected onto the log-concave class. Motivated by these applications, we study the minimax risk of score estimation with respect to squared $L^2(P_0)$-loss, where $P_0$ denotes an underlying log-concave distribution on $\mathbb{R}$. Such distributions have decreasing score functions, but on its own, this shape constraint is insufficient to guarantee a finite minimax risk. We therefore define subclasses of log-concave densities that capture two fundamental aspects of the estimation problem. First, we establish the crucial impact of tail behaviour on score estimation by determining the minimax rate over a class of log-concave densities whose score function exhibits controlled growth relative to the quantile levels. Second, we explore the interplay between smoothness and log-concavity by considering the class of log-concave densities with a scale restriction and a $(β,L)$-Hölder assumption on the log-density for some $β\in [1,2]$. We show that the minimax risk over this latter class is of order $L^{2/(2β+1)}n^{-β/(2β+1)}$ up to poly-logarithmic factors, where $n$ denotes the sample size. When $β< 2$, this rate is faster than could be obtained under either the shape constraint or the smoothness assumption alone. Our upper bounds are attained by a locally adaptive, multiscale estimator constructed from a uniform confidence band for the score function. This study highlights intriguing differences between the score estimation and density estimation problems over this shape-constrained class.
Deep learning with missing data
Apr 21, 2025In the context of multivariate nonparametric regression with missing covariates, we propose Pattern Embedded Neural Networks (PENNs), which can be applied in conjunction with any existing imputation technique. In addition to a neural network trained on the imputed data, PENNs pass the vectors of observation indicators through a second neural network to provide a compact representation. The outputs are then combined in a third neural network to produce final predictions. Our main theoretical result exploits an assumption that the observation patterns can be partitioned into cells on which the Bayes regression function behaves similarly, and belongs to a compositional H\"older class. It provides a finite-sample excess risk bound that holds for an arbitrary missingness mechanism, and in combination with a complementary minimax lower bound, demonstrates that our PENN estimator attains in typical cases the minimax rate of convergence as if the cells of the partition were known in advance, up to a poly-logarithmic factor in the sample size. Numerical experiments on simulated, semi-synthetic and real data confirm that the PENN estimator consistently improves, often dramatically, on standard neural networks without pattern embedding. Code to reproduce our experiments, as well as a tutorial on how to apply our method, is publicly available.
High-probability minimax lower bounds
Jun 19, 2024The minimax risk is often considered as a gold standard against which we can compare specific statistical procedures. Nevertheless, as has been observed recently in robust and heavy-tailed estimation problems, the inherent reduction of the (random) loss to its expectation may entail a significant loss of information regarding its tail behaviour. In an attempt to avoid such a loss, we introduce the notion of a minimax quantile, and seek to articulate its dependence on the quantile level. To this end, we develop high-probability variants of the classical Le Cam and Fano methods, as well as a technique to convert local minimax risk lower bounds to lower bounds on minimax quantiles. To illustrate the power of our framework, we deploy our techniques on several examples, recovering recent results in robust mean estimation and stochastic convex optimisation, as well as obtaining several new results in covariance matrix estimation, sparse linear regression, nonparametric density estimation and isotonic regression. Our overall goal is to argue that minimax quantiles can provide a finer-grained understanding of the difficulty of statistical problems, and that, in wide generality, lower bounds on these quantities can be obtained via user-friendly tools.
Optimal convex $M$-estimation via score matching
Mar 25, 2024
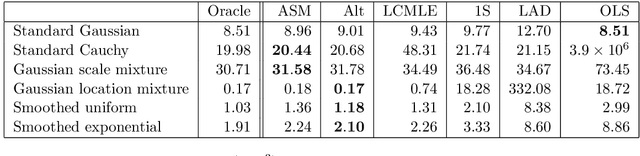

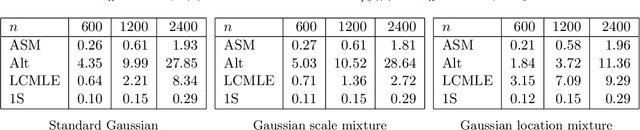
In the context of linear regression, we construct a data-driven convex loss function with respect to which empirical risk minimisation yields optimal asymptotic variance in the downstream estimation of the regression coefficients. Our semiparametric approach targets the best decreasing approximation of the derivative of the log-density of the noise distribution. At the population level, this fitting process is a nonparametric extension of score matching, corresponding to a log-concave projection of the noise distribution with respect to the Fisher divergence. The procedure is computationally efficient, and we prove that our procedure attains the minimal asymptotic covariance among all convex $M$-estimators. As an example of a non-log-concave setting, for Cauchy errors, the optimal convex loss function is Huber-like, and our procedure yields an asymptotic efficiency greater than 0.87 relative to the oracle maximum likelihood estimator of the regression coefficients that uses knowledge of this error distribution; in this sense, we obtain robustness without sacrificing much efficiency. Numerical experiments confirm the practical merits of our proposal.
Sharp-SSL: Selective high-dimensional axis-aligned random projections for semi-supervised learning
Apr 18, 2023We propose a new method for high-dimensional semi-supervised learning problems based on the careful aggregation of the results of a low-dimensional procedure applied to many axis-aligned random projections of the data. Our primary goal is to identify important variables for distinguishing between the classes; existing low-dimensional methods can then be applied for final class assignment. Motivated by a generalized Rayleigh quotient, we score projections according to the traces of the estimated whitened between-class covariance matrices on the projected data. This enables us to assign an importance weight to each variable for a given projection, and to select our signal variables by aggregating these weights over high-scoring projections. Our theory shows that the resulting Sharp-SSL algorithm is able to recover the signal coordinates with high probability when we aggregate over sufficiently many random projections and when the base procedure estimates the whitened between-class covariance matrix sufficiently well. The Gaussian EM algorithm is a natural choice as a base procedure, and we provide a new analysis of its performance in semi-supervised settings that controls the parameter estimation error in terms of the proportion of labeled data in the sample. Numerical results on both simulated data and a real colon tumor dataset support the excellent empirical performance of the method.
The Projected Covariance Measure for assumption-lean variable significance testing
Nov 03, 2022


Testing the significance of a variable or group of variables $X$ for predicting a response $Y$, given additional covariates $Z$, is a ubiquitous task in statistics. A simple but common approach is to specify a linear model, and then test whether the regression coefficient for $X$ is non-zero. However, when the model is misspecified, the test may have poor power, for example when $X$ is involved in complex interactions, or lead to many false rejections. In this work we study the problem of testing the model-free null of conditional mean independence, i.e. that the conditional mean of $Y$ given $X$ and $Z$ does not depend on $X$. We propose a simple and general framework that can leverage flexible nonparametric or machine learning methods, such as additive models or random forests, to yield both robust error control and high power. The procedure involves using these methods to perform regressions, first to estimate a form of projection of $Y$ on $X$ and $Z$ using one half of the data, and then to estimate the expected conditional covariance between this projection and $Y$ on the remaining half of the data. While the approach is general, we show that a version of our procedure using spline regression achieves what we show is the minimax optimal rate in this nonparametric testing problem. Numerical experiments demonstrate the effectiveness of our approach both in terms of maintaining Type I error control, and power, compared to several existing approaches.
Optimal subgroup selection
Sep 02, 2021

In clinical trials and other applications, we often see regions of the feature space that appear to exhibit interesting behaviour, but it is unclear whether these observed phenomena are reflected at the population level. Focusing on a regression setting, we consider the subgroup selection challenge of identifying a region of the feature space on which the regression function exceeds a pre-determined threshold. We formulate the problem as one of constrained optimisation, where we seek a low-complexity, data-dependent selection set on which, with a guaranteed probability, the regression function is uniformly at least as large as the threshold; subject to this constraint, we would like the region to contain as much mass under the marginal feature distribution as possible. This leads to a natural notion of regret, and our main contribution is to determine the minimax optimal rate for this regret in both the sample size and the Type I error probability. The rate involves a delicate interplay between parameters that control the smoothness of the regression function, as well as exponents that quantify the extent to which the optimal selection set at the population level can be approximated by families of well-behaved subsets. Finally, we expand the scope of our previous results by illustrating how they may be generalised to a treatment and control setting, where interest lies in the heterogeneous treatment effect.
Adaptive transfer learning
Jun 08, 2021

In transfer learning, we wish to make inference about a target population when we have access to data both from the distribution itself, and from a different but related source distribution. We introduce a flexible framework for transfer learning in the context of binary classification, allowing for covariate-dependent relationships between the source and target distributions that are not required to preserve the Bayes decision boundary. Our main contributions are to derive the minimax optimal rates of convergence (up to poly-logarithmic factors) in this problem, and show that the optimal rate can be achieved by an algorithm that adapts to key aspects of the unknown transfer relationship, as well as the smoothness and tail parameters of our distributional classes. This optimal rate turns out to have several regimes, depending on the interplay between the relative sample sizes and the strength of the transfer relationship, and our algorithm achieves optimality by careful, decision tree-based calibration of local nearest-neighbour procedures.