 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Post Hoc Case Based Explanation with Feature Highlighting
Paper and Code
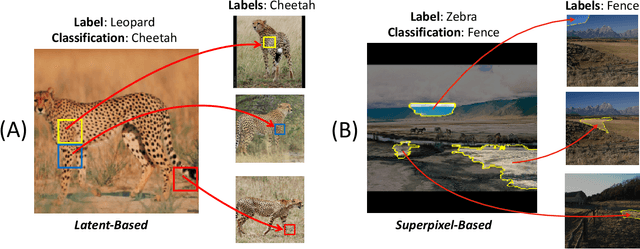
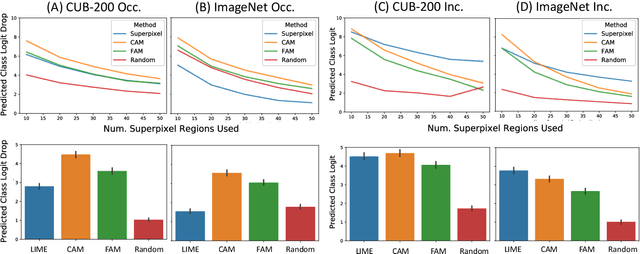
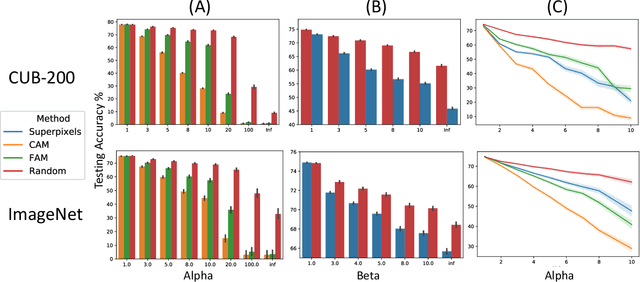
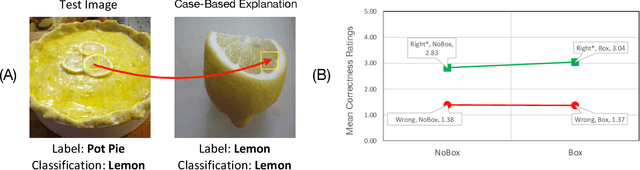
Explainable AI (XAI) has been proposed as a valuable tool to assist in downstream tasks involving human and AI collaboration. Perhaps the most psychologically valid XAI techniques are case based approaches which display 'whole' exemplars to explain the predictions of black box AI systems. However, for such post hoc XAI methods dealing with images, there has been no attempt to improve their scope by using multiple clear feature 'parts' of the images to explain the predictions while linking back to relevant cases in the training data, thus allowing for more comprehensive explanations that are faithful to the underlying model. Here, we address this gap by proposing two general algorithms (latent and super pixel based) which can isolate multiple clear feature parts in a test image, and then connect them to the explanatory cases found in the training data, before testing their effectiveness in a carefully designed user study. Results demonstrate that the proposed approach appropriately calibrates a users feelings of 'correctness' for ambiguous classifications in real world data on the ImageNet dataset, an effect which does not happen when just showing the explanation without feature highlighting.