 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization vs. Memorization in the Presence of Statistical Biases in Transformers
Sep 06, 2024This study aims to understand how statistical biases affect the model's ability to generalize to in-distribution and out-of-distribution data on algorithmic tasks. Prior research indicates that transformers may inadvertently learn to rely on these spurious correlations, leading to an overestimation of their generalization capabilities. To investigate this, we evaluate transformer models on several synthetic algorithmic tasks, systematically introducing and varying the presence of these biases. We also analyze how different components of the transformer models impact their generalization. Our findings suggest that statistical biases impair the model's performance on out-of-distribution data, providing a overestimation of its generalization capabilities. The models rely heavily on these spurious correlations for inference, as indicated by their performance on tasks including such biases.
On the Importance of Regularisation & Auxiliary Information in OOD Detection
Jul 15, 2021


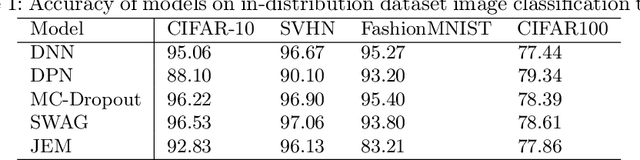
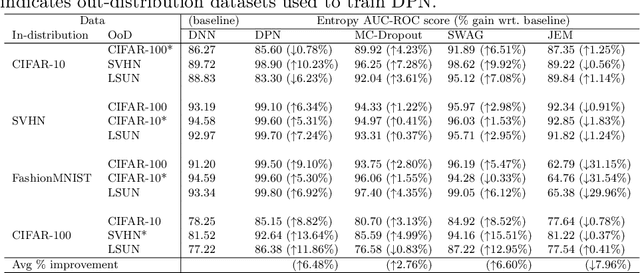
Neural networks are often utilised in critical domain applications (e.g.~self-driving cars, financial markets, and aerospace engineering), even though they exhibit overconfident predictions for ambiguous inputs. This deficiency demonstrates a fundamental flaw indicating that neural networks often overfit on spurious correlations. To address this problem in this work we present two novel objectives that improve the ability of a network to detect out-of-distribution samples and therefore avoid overconfident predictions for ambiguous inputs. We empirically demonstrate that our methods outperform the baseline and perform better than the majority of existing approaches, while performing competitively those that they don't outperform. Additionally, we empirically demonstrate the robustness of our approach against common corruptions and demonstrate the importance of regularisation and auxiliary information in out-of-distribution detection.
Ramifications of Approximate Posterior Inference for Bayesian Deep Learning in Adversarial and Out-of-Distribution Settings
Oct 03, 2020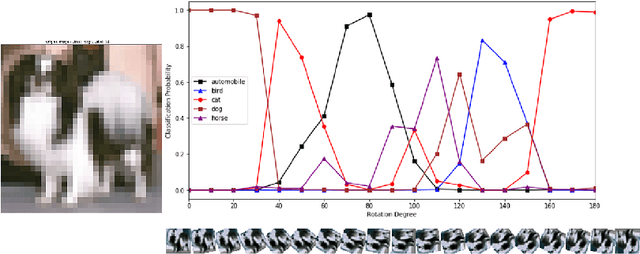
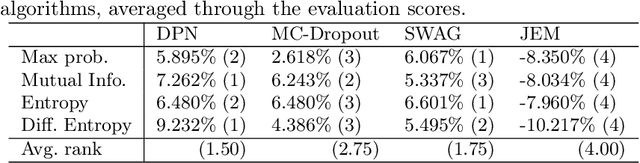
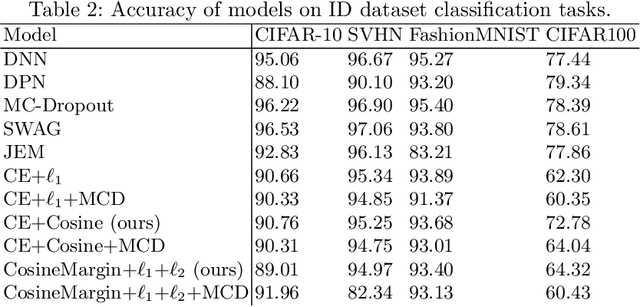
Deep neural networks have been successful in diverse discriminative classification tasks, although, they are poorly calibrated often assigning high probability to misclassified predictions. Potential consequences could lead to trustworthiness and accountability of the models when deployed in real applications, where predictions are evaluated based on their confidence scores. Existing solutions suggest the benefits attained by combining deep neural networks and Bayesian inference to quantify uncertainty over the models' predictions for ambiguous datapoints. In this work we propose to validate and test the efficacy of likelihood based models in the task of out of distribution detection (OoD). Across different datasets and metrics we show that Bayesian deep learning models on certain occasions marginally outperform conventional neural networks and in the event of minimal overlap between in/out distribution classes, even the best models exhibit a reduction in AUC scores in detecting OoD data. Preliminary investigations indicate the potential inherent role of bias due to choices of initialisation, architecture or activation functions. We hypothesise that the sensitivity of neural networks to unseen inputs could be a multi-factor phenomenon arising from the different architectural design choices often amplified by the curse of dimensionality. Furthermore, we perform a study to find the effect of the adversarial noise resistance methods on in and out-of-distribution performance, as well as, also investigate adversarial noise robustness of Bayesian deep learners.
On the Validity of Bayesian Neural Networks for Uncertainty Estimation
Dec 29, 2019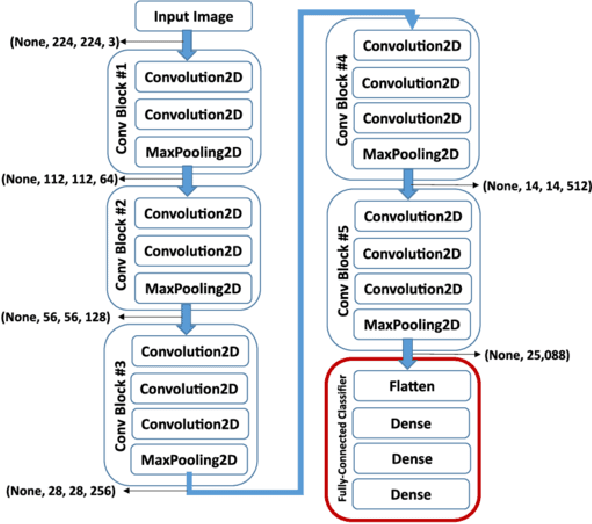
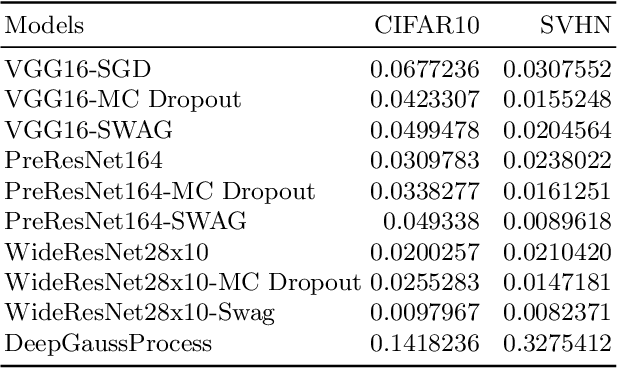
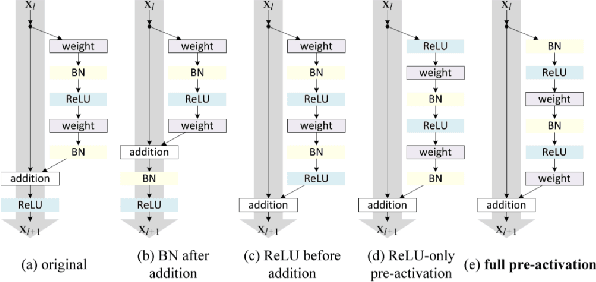

Deep neural networks (DNN) are versatile parametric models utilised successfully in a diverse number of tasks and domains. However, they have limitations---particularly from their lack of robustness and over-sensitivity to out of distribution samples. Bayesian Neural Networks, due to their formulation under the Bayesian framework, provide a principled approach to building neural networks that address these limitations. This paper describes a study that empirically evaluates and compares Bayesian Neural Networks to their equivalent point estimate Deep Neural Networks to quantify the predictive uncertainty induced by their parameters, as well as their performance in view of this uncertainty. In this study, we evaluated and compared three point estimate deep neural networks against comparable Bayesian neural network alternatives using two well-known benchmark image classification datasets (CIFAR-10 and SVHN).
A Categorisation of Post-hoc Explanations for Predictive Models
Apr 04, 2019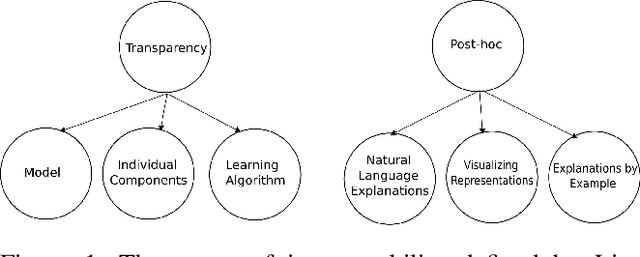
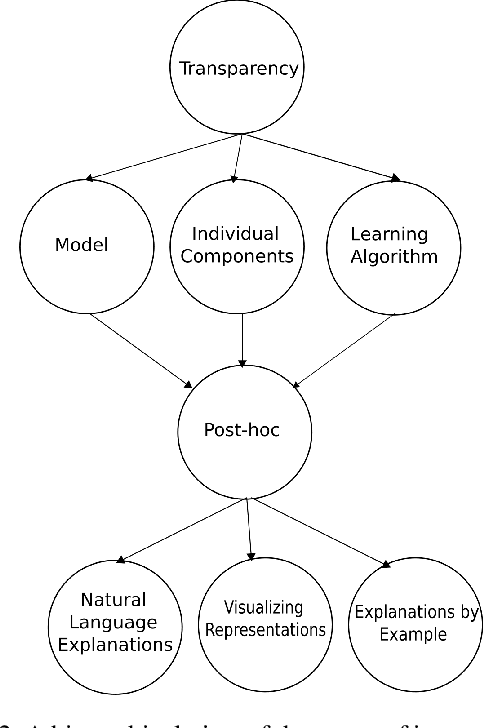

The ubiquity of machine learning based predictive models in modern society naturally leads people to ask how trustworthy those models are? In predictive modeling, it is quite common to induce a trade-off between accuracy and interpretability. For instance, doctors would like to know how effective some treatment will be for a patient or why the model suggested a particular medication for a patient exhibiting those symptoms? We acknowledge that the necessity for interpretability is a consequence of an incomplete formalisation of the problem, or more precisely of multiple meanings adhered to a particular concept. For certain problems, it is not enough to get the answer (what), the model also has to provide an explanation of how it came to that conclusion (why), because a correct prediction, only partially solves the original problem. In this article we extend existing categorisation of techniques to aid model interpretability and test this categorisation.