 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizable IoT Traffic Representations for Cross-Network Device Identification
Jan 27, 2026Machine learning models have demonstrated strong performance in classifying network traffic and identifying Internet-of-Things (IoT) devices, enabling operators to discover and manage IoT assets at scale. However, many existing approaches rely on end-to-end supervised pipelines or task-specific fine-tuning, resulting in traffic representations that are tightly coupled to labeled datasets and deployment environments, which can limit generalizability. In this paper, we study the problem of learning generalizable traffic representations for IoT device identification. We design compact encoder architectures that learn per-flow embeddings from unlabeled IoT traffic and evaluate them using a frozen-encoder protocol with a simple supervised classifier. Our specific contributions are threefold. (1) We develop unsupervised encoder--decoder models that learn compact traffic representations from unlabeled IoT network flows and assess their quality through reconstruction-based analysis. (2) We show that these learned representations can be used effectively for IoT device-type classification using simple, lightweight classifiers trained on frozen embeddings. (3) We provide a systematic benchmarking study against the state-of-the-art pretrained traffic encoders, showing that larger models do not necessarily yield more robust representations for IoT traffic. Using more than 18 million real IoT traffic flows collected across multiple years and deployment environments, we learn traffic representations from unlabeled data and evaluate device-type classification on disjoint labeled subsets, achieving macro F1-scores exceeding 0.9 for device-type classification and demonstrating robustness under cross-environment deployment.
Cascading Failures in Smart Grids under Random, Targeted and Adaptive Attacks
Jun 25, 2022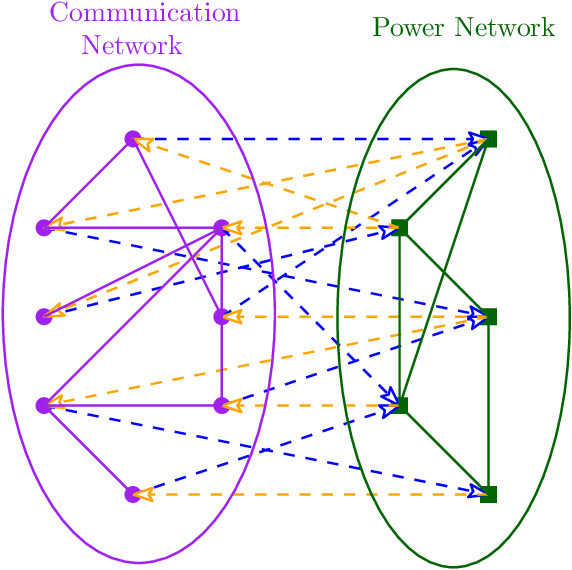
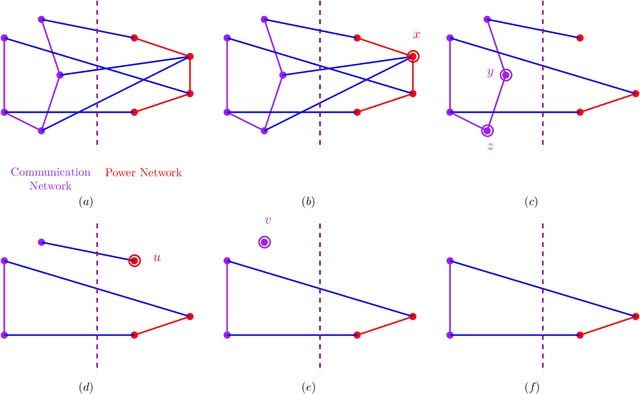
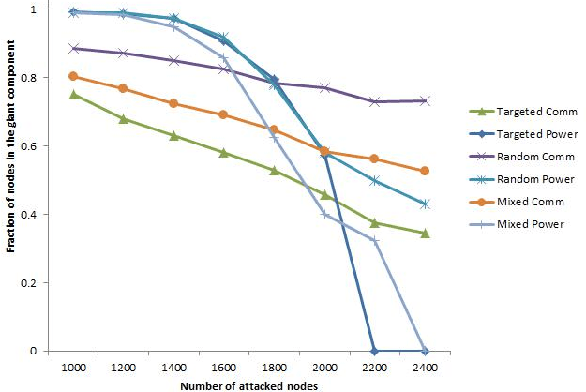
We study cascading failures in smart grids, where an attacker selectively compromises the nodes with probabilities proportional to their degrees, betweenness, or clustering coefficient. This implies that nodes with high degrees, betweenness, or clustering coefficients are attacked with higher probability. We mathematically and experimentally analyze the sizes of the giant components of the networks under different types of targeted attacks, and compare the results with the corresponding sizes under random attacks. We show that networks disintegrate faster for targeted attacks compared to random attacks. A targeted attack on a small fraction of high degree nodes disintegrates one or both of the networks, whereas both the networks contain giant components for random attack on the same fraction of nodes. An important observation is that an attacker has an advantage if it compromises nodes based on their betweenness, rather than based on degree or clustering coefficient. We next study adaptive attacks, where an attacker compromises nodes in rounds. Here, some nodes are compromised in each round based on their degree, betweenness or clustering coefficients, instead of compromising all nodes together. In this case, the degree, betweenness, or clustering coefficient is calculated before the start of each round, instead of at the beginning. We show experimentally that an adversary has an advantage in this adaptive approach, compared to compromising the same number of nodes all at once.
SPRITE: A Scalable Privacy-Preserving and Verifiable Collaborative Learning for Industrial IoT
Mar 22, 2022



Recently collaborative learning is widely applied to model sensitive data generated in Industrial IoT (IIoT). It enables a large number of devices to collectively train a global model by collaborating with a server while keeping the datasets on their respective premises. However, existing approaches are limited by high overheads and may also suffer from falsified aggregated results returned by a malicious server. Hence, we propose a Scalable, Privacy-preserving and veRIfiable collaboraTive lEarning (SPRITE) algorithm to train linear and logistic regression models for IIoT. We aim to reduce burden from resource-constrained IIoT devices and trust dependence on cloud by introducing fog as a middleware. SPRITE employs threshold secret sharing to guarantee privacy-preservation and robustness to IIoT device dropout whereas verifiable additive homomorphic secret sharing to ensure verifiability during model aggregation. We prove the security of SPRITE in an honest-but-curious setting where the cloud is untrustworthy. We validate SPRITE to be scalable and lightweight through theoretical overhead analysis and extensive testbed experimentation on an IIoT use-case with two real-world industrial datasets. For a large-scale industrial setup, SPRITE records 65% and 55% improved performance over its competitor for linear and logistic regressions respectively while reducing communication overhead for an IIoT device by 90%.