 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhishZip: A New Compression-based Algorithm for Detecting Phishing Websites
Paper and Code
Jul 22, 2020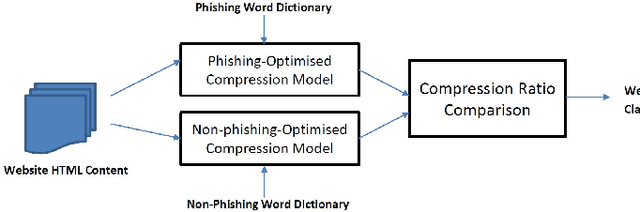
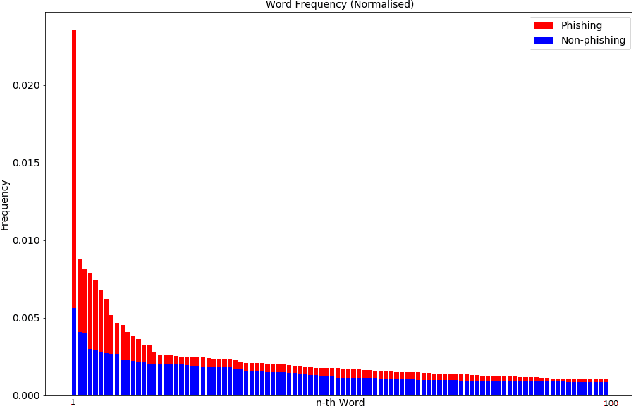
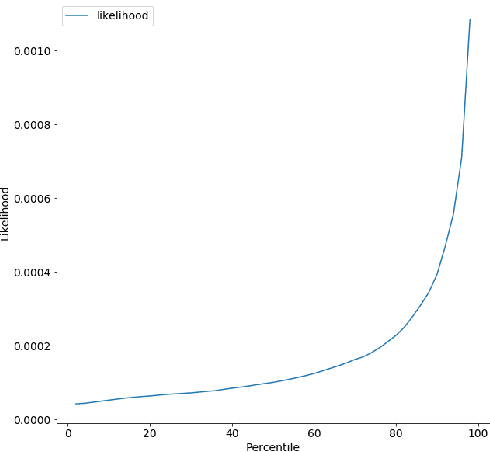
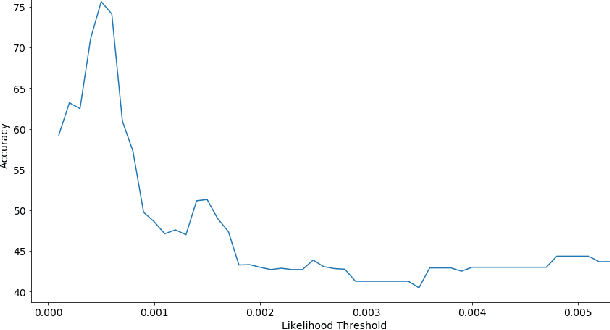
Phishing has grown significantly in the past few years and is predicted to further increase in the future. The dynamics of phishing introduce challenges in implementing a robust phishing detection system and selecting features which can represent phishing despite the change of attack. In this paper, we propose PhishZip which is a novel phishing detection approach using a compression algorithm to perform website classification and demonstrate a systematic way to construct the word dictionaries for the compression models using word occurrence likelihood analysis. PhishZip outperforms the use of best-performing HTML-based features in past studies, with a true positive rate of 80.04%. We also propose the use of compression ratio as a novel machine learning feature which significantly improves machine learning based phishing detection over previous studies. Using compression ratios as additional features, the true positive rate significantly improves by 30.3% (from 51.47% to 81.77%), while the accuracy increases by 11.84% (from 71.20% to 83.04%).