 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizable IoT Traffic Representations for Cross-Network Device Identification
Jan 27, 2026Machine learning models have demonstrated strong performance in classifying network traffic and identifying Internet-of-Things (IoT) devices, enabling operators to discover and manage IoT assets at scale. However, many existing approaches rely on end-to-end supervised pipelines or task-specific fine-tuning, resulting in traffic representations that are tightly coupled to labeled datasets and deployment environments, which can limit generalizability. In this paper, we study the problem of learning generalizable traffic representations for IoT device identification. We design compact encoder architectures that learn per-flow embeddings from unlabeled IoT traffic and evaluate them using a frozen-encoder protocol with a simple supervised classifier. Our specific contributions are threefold. (1) We develop unsupervised encoder--decoder models that learn compact traffic representations from unlabeled IoT network flows and assess their quality through reconstruction-based analysis. (2) We show that these learned representations can be used effectively for IoT device-type classification using simple, lightweight classifiers trained on frozen embeddings. (3) We provide a systematic benchmarking study against the state-of-the-art pretrained traffic encoders, showing that larger models do not necessarily yield more robust representations for IoT traffic. Using more than 18 million real IoT traffic flows collected across multiple years and deployment environments, we learn traffic representations from unlabeled data and evaluate device-type classification on disjoint labeled subsets, achieving macro F1-scores exceeding 0.9 for device-type classification and demonstrating robustness under cross-environment deployment.
Instance-Wise Monotonic Calibration by Constrained Transformation
Jul 09, 2025Deep neural networks often produce miscalibrated probability estimates, leading to overconfident predictions. A common approach for calibration is fitting a post-hoc calibration map on unseen validation data that transforms predicted probabilities. A key desirable property of the calibration map is instance-wise monotonicity (i.e., preserving the ranking of probability outputs). However, most existing post-hoc calibration methods do not guarantee monotonicity. Previous monotonic approaches either use an under-parameterized calibration map with limited expressive ability or rely on black-box neural networks, which lack interpretability and robustness. In this paper, we propose a family of novel monotonic post-hoc calibration methods, which employs a constrained calibration map parameterized linearly with respect to the number of classes. Our proposed approach ensures expressiveness, robustness, and interpretability while preserving the relative ordering of the probability output by formulating the proposed calibration map as a constrained optimization problem. Our proposed methods achieve state-of-the-art performance across datasets with different deep neural network models, outperforming existing calibration methods while being data and computation-efficient. Our code is available at https://github.com/YunruiZhang/Calibration-by-Constrained-Transformation
Nosy Layers, Noisy Fixes: Tackling DRAs in Federated Learning Systems using Explainable AI
May 16, 2025Federated Learning (FL) has emerged as a powerful paradigm for collaborative model training while keeping client data decentralized and private. However, it is vulnerable to Data Reconstruction Attacks (DRA) such as "LoKI" and "Robbing the Fed", where malicious models sent from the server to the client can reconstruct sensitive user data. To counter this, we introduce DRArmor, a novel defense mechanism that integrates Explainable AI with targeted detection and mitigation strategies for DRA. Unlike existing defenses that focus on the entire model, DRArmor identifies and addresses the root cause (i.e., malicious layers within the model that send gradients with malicious intent) by analyzing their contribution to the output and detecting inconsistencies in gradient values. Once these malicious layers are identified, DRArmor applies defense techniques such as noise injection, pixelation, and pruning to these layers rather than the whole model, minimizing the attack surface and preserving client data privacy. We evaluate DRArmor's performance against the advanced LoKI attack across diverse datasets, including MNIST, CIFAR-10, CIFAR-100, and ImageNet, in a 200-client FL setup. Our results demonstrate DRArmor's effectiveness in mitigating data leakage, achieving high True Positive and True Negative Rates of 0.910 and 0.890, respectively. Additionally, DRArmor maintains an average accuracy of 87%, effectively protecting client privacy without compromising model performance. Compared to existing defense mechanisms, DRArmor reduces the data leakage rate by 62.5% with datasets containing 500 samples per client.
FastFlow: Early Yet Robust Network Flow Classification using the Minimal Number of Time-Series Packets
Apr 02, 2025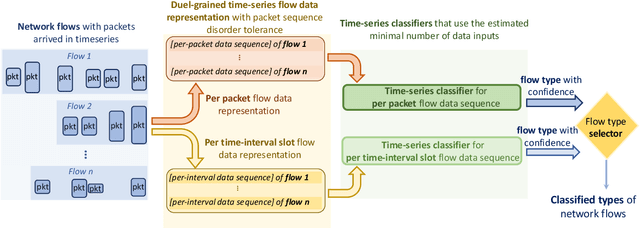
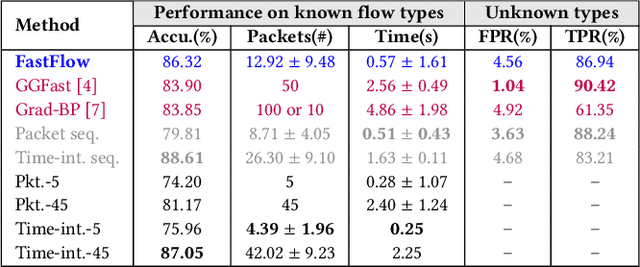
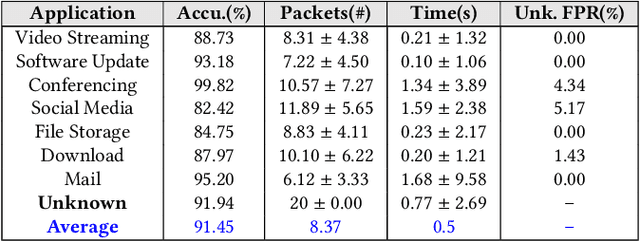
Network traffic classification is of great importance for network operators in their daily routines, such as analyzing the usage patterns of multimedia applications and optimizing network configurations. Internet service providers (ISPs) that operate high-speed links expect network flow classifiers to accurately classify flows early, using the minimal number of necessary initial packets per flow. These classifiers must also be robust to packet sequence disorders in candidate flows and capable of detecting unseen flow types that are not within the existing classification scope, which are not well achieved by existing methods. In this paper, we develop FastFlow, a time-series flow classification method that accurately classifies network flows as one of the known types or the unknown type, which dynamically selects the minimal number of packets to balance accuracy and efficiency. Toward the objectives, we first develop a flow representation process that converts packet streams at both per-packet and per-slot granularity for precise packet statistics with robustness to packet sequence disorders. Second, we develop a sequential decision-based classification model that leverages LSTM architecture trained with reinforcement learning. Our model makes dynamic decisions on the minimal number of time-series data points per flow for the confident classification as one of the known flow types or an unknown one. We evaluated our method on public datasets and demonstrated its superior performance in early and accurate flow classification. Deployment insights on the classification of over 22.9 million flows across seven application types and 33 content providers in a campus network over one week are discussed, showing that FastFlow requires an average of only 8.37 packets and 0.5 seconds to classify the application type of a flow with over 91% accuracy and over 96% accuracy for the content providers.
Revisit Time Series Classification Benchmark: The Impact of Temporal Information for Classification
Mar 26, 2025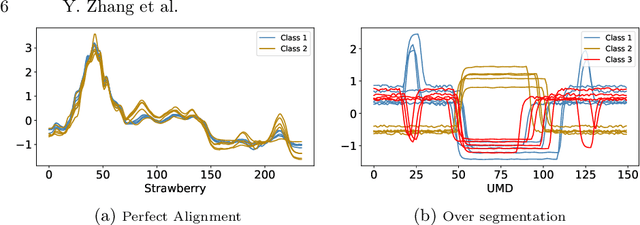
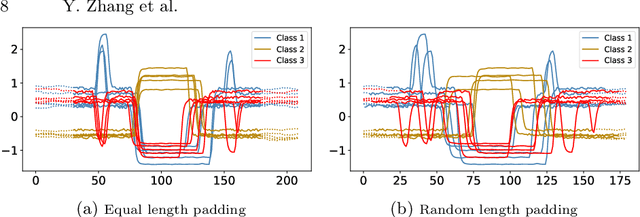
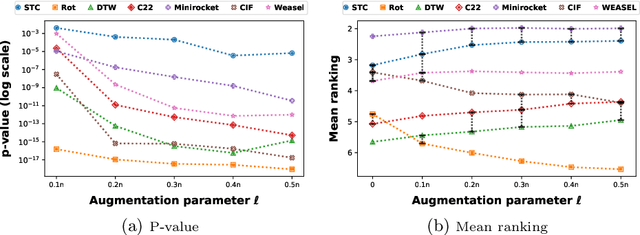
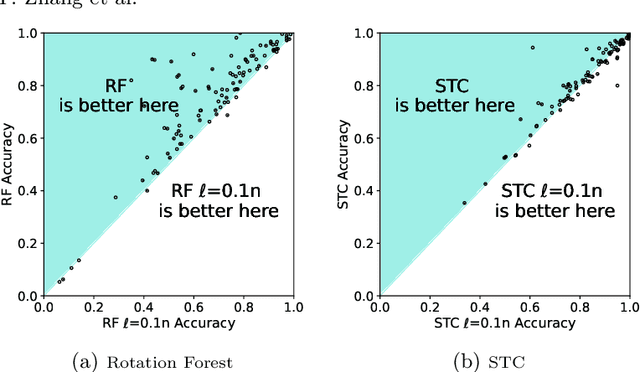
Time series classification is usually regarded as a distinct task from tabular data classification due to the importance of temporal information. However, in this paper, by performing permutation tests that disrupt temporal information on the UCR time series classification archive, the most widely used benchmark for time series classification, we identify a significant proportion of datasets where temporal information has little to no impact on classification. Many of these datasets are tabular in nature or rely mainly on tabular features, leading to potentially biased evaluations of time series classifiers focused on temporal information. To address this, we propose UCR Augmented, a benchmark based on the UCR time series classification archive designed to evaluate classifiers' ability to extract and utilize temporal information. Testing classifiers from seven categories on this benchmark revealed notable shifts in performance rankings. Some previously overlooked approaches perform well, while others see their performance decline significantly when temporal information is crucial. UCR Augmented provides a more robust framework for assessing time series classifiers, ensuring fairer evaluations. Our code is available at https://github.com/YunruiZhang/Revisit-Time-Series-Classification-Benchmark.
AA-DLADMM: An Accelerated ADMM-based Framework for Training Deep Neural Networks
Jan 08, 2024Stochastic gradient descent (SGD) and its many variants are the widespread optimization algorithms for training deep neural networks. However, SGD suffers from inevitable drawbacks, including vanishing gradients, lack of theoretical guarantees, and substantial sensitivity to input. The Alternating Direction Method of Multipliers (ADMM) has been proposed to address these shortcomings as an effective alternative to the gradient-based methods. It has been successfully employed for training deep neural networks. However, ADMM-based optimizers have a slow convergence rate. This paper proposes an Anderson Acceleration for Deep Learning ADMM (AA-DLADMM) algorithm to tackle this drawback. The main intention of the AA-DLADMM algorithm is to employ Anderson acceleration to ADMM by considering it as a fixed-point iteration and attaining a nearly quadratic convergence rate. We verify the effectiveness and efficiency of the proposed AA-DLADMM algorithm by conducting extensive experiments on four benchmark datasets contrary to other state-of-the-art optimizers.
Pedestrian Trajectory Prediction Using Dynamics-based Deep Learning
Sep 16, 2023Pedestrian trajectory prediction plays an important role in autonomous driving systems and robotics. Recent work utilising prominent deep learning models for pedestrian motion prediction makes limited a priori assumptions about human movements, resulting in a lack of explainability and explicit constraints enforced on predicted trajectories. This paper presents a dynamics-based deep learning framework where a novel asymptotically stable dynamical system is integrated into a deep learning model. Our novel asymptotically stable dynamical system is used to model human goal-targeted motion by enforcing the human walking trajectory converges to a predicted goal position and provides a deep learning model with prior knowledge and explainability. Our deep learning model utilises recent innovations from transformer networks and is used to learn some features of human motion, such as collision avoidance, for our proposed dynamical system. The experimental results show that our framework outperforms recent prominent models in pedestrian trajectory prediction on five benchmark human motion datasets.
Detecting Anomalous Microflows in IoT Volumetric Attacks via Dynamic Monitoring of MUD Activity
Apr 11, 2023IoT networks are increasingly becoming target of sophisticated new cyber-attacks. Anomaly-based detection methods are promising in finding new attacks, but there are certain practical challenges like false-positive alarms, hard to explain, and difficult to scale cost-effectively. The IETF recent standard called Manufacturer Usage Description (MUD) seems promising to limit the attack surface on IoT devices by formally specifying their intended network behavior. In this paper, we use SDN to enforce and monitor the expected behaviors of each IoT device, and train one-class classifier models to detect volumetric attacks. Our specific contributions are fourfold. (1) We develop a multi-level inferencing model to dynamically detect anomalous patterns in network activity of MUD-compliant traffic flows via SDN telemetry, followed by packet inspection of anomalous flows. This provides enhanced fine-grained visibility into distributed and direct attacks, allowing us to precisely isolate volumetric attacks with microflow (5-tuple) resolution. (2) We collect traffic traces (benign and a variety of volumetric attacks) from network behavior of IoT devices in our lab, generate labeled datasets, and make them available to the public. (3) We prototype a full working system (modules are released as open-source), demonstrates its efficacy in detecting volumetric attacks on several consumer IoT devices with high accuracy while maintaining low false positives, and provides insights into cost and performance of our system. (4) We demonstrate how our models scale in environments with a large number of connected IoTs (with datasets collected from a network of IP cameras in our university campus) by considering various training strategies (per device unit versus per device type), and balancing the accuracy of prediction against the cost of models in terms of size and training time.
Quantifying and Managing Impacts of Concept Drifts on IoT Traffic Inference in Residential ISP Networks
Jan 17, 2023



Millions of vulnerable consumer IoT devices in home networks are the enabler for cyber crimes putting user privacy and Internet security at risk. Internet service providers (ISPs) are best poised to play key roles in mitigating risks by automatically inferring active IoT devices per household and notifying users of vulnerable ones. Developing a scalable inference method that can perform robustly across thousands of home networks is a non-trivial task. This paper focuses on the challenges of developing and applying data-driven inference models when labeled data of device behaviors is limited and the distribution of data changes (concept drift) across time and space domains. Our contributions are three-fold: (1) We collect and analyze network traffic of 24 types of consumer IoT devices from 12 real homes over six weeks to highlight the challenge of temporal and spatial concept drifts in network behavior of IoT devices; (2) We analyze the performance of two inference strategies, namely "global inference" (a model trained on a combined set of all labeled data from training homes) and "contextualized inference" (several models each trained on the labeled data from a training home) in the presence of concept drifts; and (3) To manage concept drifts, we develop a method that dynamically applies the ``closest'' model (from a set) to network traffic of unseen homes during the testing phase, yielding better performance in 20% of scenarios.
AdIoTack: Quantifying and Refining Resilience of Decision Tree Ensemble Inference Models against Adversarial Volumetric Attacks on IoT Networks
Mar 18, 2022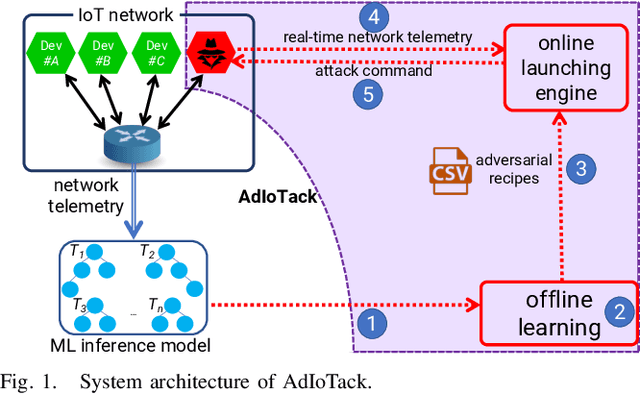
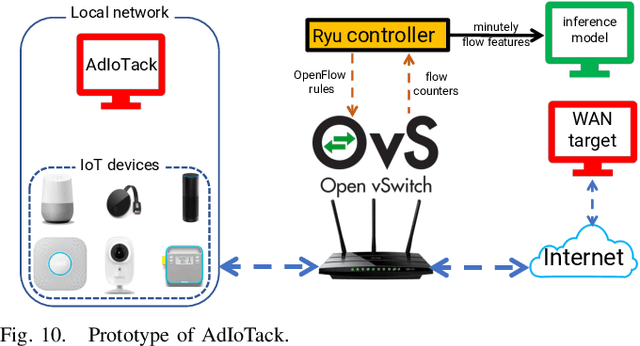
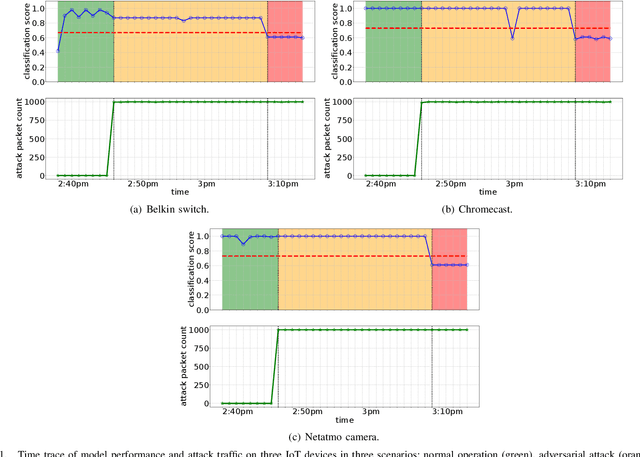
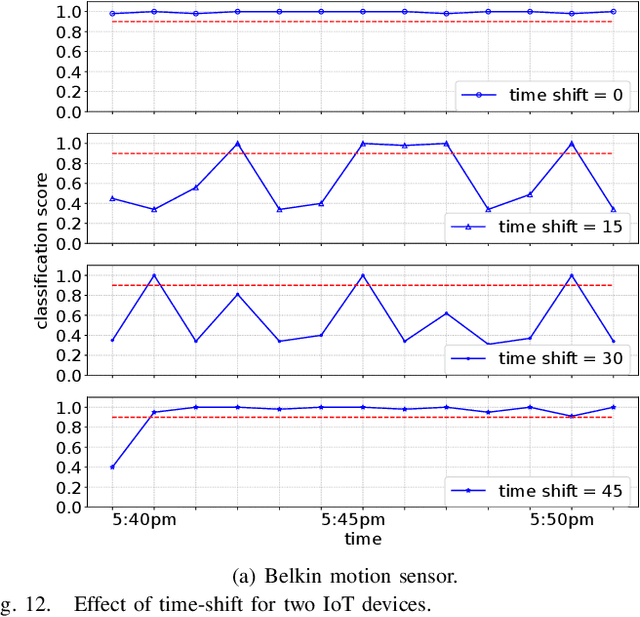
Machine Learning-based techniques have shown success in cyber intelligence. However, they are increasingly becoming targets of sophisticated data-driven adversarial attacks resulting in misprediction, eroding their ability to detect threats on network devices. In this paper, we present AdIoTack, a system that highlights vulnerabilities of decision trees against adversarial attacks, helping cybersecurity teams quantify and refine the resilience of their trained models for monitoring IoT networks. To assess the model for the worst-case scenario, AdIoTack performs white-box adversarial learning to launch successful volumetric attacks that decision tree ensemble models cannot flag. Our first contribution is to develop a white-box algorithm that takes a trained decision tree ensemble model and the profile of an intended network-based attack on a victim class as inputs. It then automatically generates recipes that specify certain packets on top of the indented attack packets (less than 15% overhead) that together can bypass the inference model unnoticed. We ensure that the generated attack instances are feasible for launching on IP networks and effective in their volumetric impact. Our second contribution develops a method to monitor the network behavior of connected devices actively, inject adversarial traffic (when feasible) on behalf of a victim IoT device, and successfully launch the intended attack. Our third contribution prototypes AdIoTack and validates its efficacy on a testbed consisting of a handful of real IoT devices monitored by a trained inference model. We demonstrate how the model detects all non-adversarial volumetric attacks on IoT devices while missing many adversarial ones. The fourth contribution develops systematic methods for applying patches to trained decision tree ensemble models, improving their resilience against adversarial volumetric attacks.