 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine-Learning Based Detection of Coronary Artery Calcification Using Synthetic Chest X-Rays
Nov 14, 2025Coronary artery calcification (CAC) is a strong predictor of cardiovascular events, with CT-based Agatston scoring widely regarded as the clinical gold standard. However, CT is costly and impractical for large-scale screening, while chest X-rays (CXRs) are inexpensive but lack reliable ground truth labels, constraining deep learning development. Digitally reconstructed radiographs (DRRs) offer a scalable alternative by projecting CT volumes into CXR-like images while inheriting precise labels. In this work, we provide the first systematic evaluation of DRRs as a surrogate training domain for CAC detection. Using 667 CT scans from the COCA dataset, we generate synthetic DRRs and assess model capacity, super-resolution fidelity enhancement, preprocessing, and training strategies. Lightweight CNNs trained from scratch outperform large pretrained networks; pairing super-resolution with contrast enhancement yields significant gains; and curriculum learning stabilises training under weak supervision. Our best configuration achieves a mean AUC of 0.754, comparable to or exceeding prior CXR-based studies. These results establish DRRs as a scalable, label-rich foundation for CAC detection, while laying the foundation for future transfer learning and domain adaptation to real CXRs.
Automated Analysis of Learning Outcomes and Exam Questions Based on Bloom's Taxonomy
Nov 14, 2025This paper explores the automatic classification of exam questions and learning outcomes according to Bloom's Taxonomy. A small dataset of 600 sentences labeled with six cognitive categories - Knowledge, Comprehension, Application, Analysis, Synthesis, and Evaluation - was processed using traditional machine learning (ML) models (Naive Bayes, Logistic Regression, Support Vector Machines), recurrent neural network architectures (LSTM, BiLSTM, GRU, BiGRU), transformer-based models (BERT and RoBERTa), and large language models (OpenAI, Gemini, Ollama, Anthropic). Each model was evaluated under different preprocessing and augmentation strategies (for example, synonym replacement, word embeddings, etc.). Among traditional ML approaches, Support Vector Machines (SVM) with data augmentation achieved the best overall performance, reaching 94 percent accuracy, recall, and F1 scores with minimal overfitting. In contrast, the RNN models and BERT suffered from severe overfitting, while RoBERTa initially overcame it but began to show signs as training progressed. Finally, zero-shot evaluations of large language models (LLMs) indicated that OpenAI and Gemini performed best among the tested LLMs, achieving approximately 0.72-0.73 accuracy and comparable F1 scores. These findings highlight the challenges of training complex deep models on limited data and underscore the value of careful data augmentation and simpler algorithms (such as augmented SVM) for Bloom's Taxonomy classification.
Analysing Personal Attacks in U.S. Presidential Debates
Nov 14, 2025Personal attacks have become a notable feature of U.S. presidential debates and play an important role in shaping public perception during elections. Detecting such attacks can improve transparency in political discourse and provide insights for journalists, analysts and the public. Advances in deep learning and transformer-based models, particularly BERT and large language models (LLMs) have created new opportunities for automated detection of harmful language. Motivated by these developments, we present a framework for analysing personal attacks in U.S. presidential debates. Our work involves manual annotation of debate transcripts across the 2016, 2020 and 2024 election cycles, followed by statistical and language-model based analysis. We investigate the potential of fine-tuned transformer models alongside general-purpose LLMs to detect personal attacks in formal political speech. This study demonstrates how task-specific adaptation of modern language models can contribute to a deeper understanding of political communication.
Answering Students' Questions on Course Forums Using Multiple Chain-of-Thought Reasoning and Finetuning RAG-Enabled LLM
Nov 13, 2025The course forums are increasingly significant and play vital role in facilitating student discussions and answering their questions related to the course. It provides a platform for students to post their questions related to the content and admin issues related to the course. However, there are several challenges due to the increase in the number of students enrolled in the course. The primary challenge is that students' queries cannot be responded immediately and the instructors have to face lots of repetitive questions. To mitigate these issues, we propose a question answering system based on large language model with retrieval augmented generation (RAG) method. This work focuses on designing a question answering system with open source Large Language Model (LLM) and fine-tuning it on the relevant course dataset. To further improve the performance, we use a local knowledge base and applied RAG method to retrieve relevant documents relevant to students' queries, where the local knowledge base contains all the course content. To mitigate the hallucination of LLMs, We also integrate it with multi chain-of-thought reasoning to overcome the challenge of hallucination in LLMs. In this work, we experiment fine-tuned LLM with RAG method on the HotpotQA dataset. The experimental results demonstrate that the fine-tuned LLM with RAG method has a strong performance on question answering task.
Improving Graduate Outcomes by Identifying Skills Gaps and Recommending Courses Based on Career Interests
Nov 12, 2025


This paper aims to address the challenge of selecting relevant courses for students by proposing the design and development of a course recommendation system. The course recommendation system utilises a combination of data analytics techniques and machine learning algorithms to recommend courses that align with current industry trends and requirements. In order to provide customised suggestions, the study entails the design and implementation of an extensive algorithmic framework that combines machine learning methods, user preferences, and academic criteria. The system employs data mining and collaborative filtering techniques to examine past courses and individual career goals in order to provide course recommendations. Moreover, to improve the accessibility and usefulness of the recommendation system, special attention is given to the development of an easy-to-use front-end interface. The front-end design prioritises visual clarity, interaction, and simplicity through iterative prototyping and user input revisions, guaranteeing a smooth and captivating user experience. We refined and optimised the proposed system by incorporating user feedback, ensuring that it effectively meets the needs and preferences of its target users. The proposed course recommendation system could be a useful tool for students, instructors, and career advisers to use in promoting lifelong learning and professional progression as it fills the gap between university learning and industry expectations. We hope that the proposed course recommendation system will help university students in making data-drive and industry-informed course decisions, in turn, improving graduate outcomes for the university sector.
Predicting Coronary Artery Calcium Severity based on Non-Contrast Cardiac CT images using Deep Learning
Nov 10, 2025
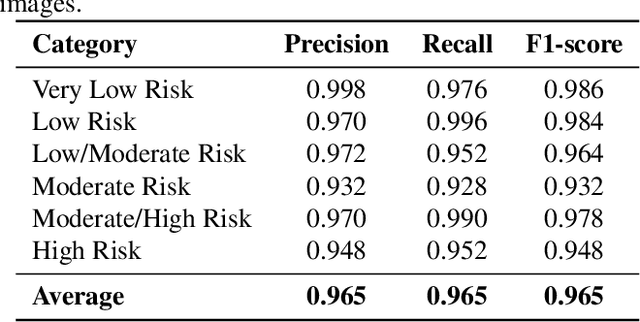
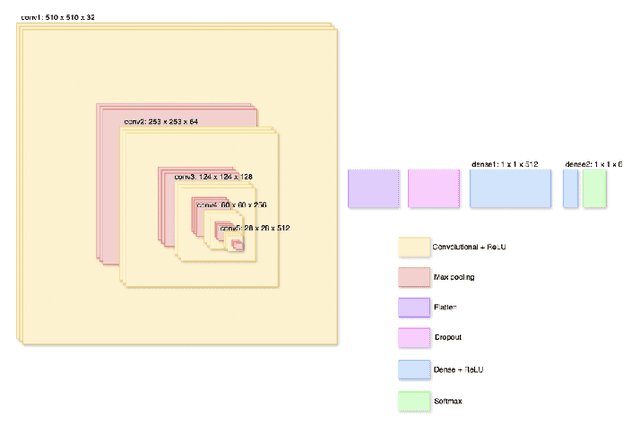
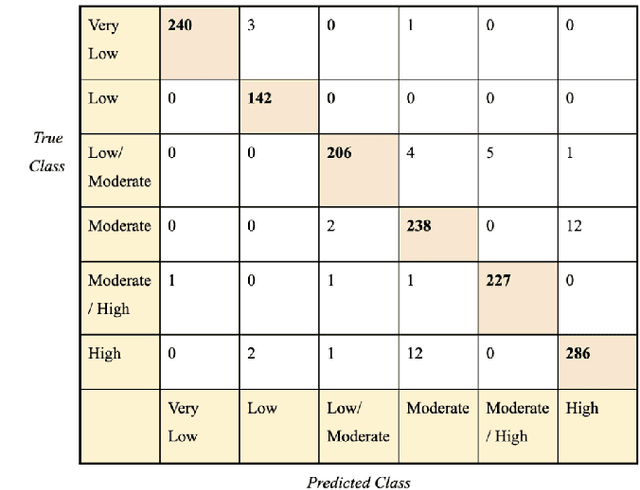
Cardiovascular disease causes high rates of mortality worldwide. Coronary artery calcium (CAC) scoring is a powerful tool to stratify the risk of atherosclerotic cardiovascular disease. Current scoring practices require time-intensive semiautomatic analysis of cardiac computed tomography by radiologists and trained radiographers. The purpose of this study is to develop a deep learning convolutional neural networks (CNN) model to classify the calcium score in cardiac, non-contrast computed tomography images into one of six clinical categories. A total of 68 patient scans were retrospectively obtained together with their respective reported semiautomatic calcium score using an ECG-gated GE Discovery 570 Cardiac SPECT/CT camera. The dataset was divided into training, validation and test sets. Using the semiautomatic CAC score as the reference label, the model demonstrated high performance on a six-class CAC scoring categorisation task. Of the scans analysed, the model misclassified 32 cases, tending towards overestimating the CAC in 26 out of 32 misclassifications. Overall, the model showed high agreement (Cohen's kappa of 0.962), an overall accuracy of 96.5% and high generalisability. The results suggest that the model outputs were accurate and consistent with current semiautomatic practice, with good generalisability to test data. The model demonstrates the viability of a CNN model to stratify the calcium score into an expanded set of six clinical categories.
LangLingual: A Personalised, Exercise-oriented English Language Learning Tool Leveraging Large Language Models
Oct 27, 2025Language educators strive to create a rich experience for learners, while they may be restricted in the extend of feedback and practice they can provide. We present the design and development of LangLingual, a conversational agent built using the LangChain framework and powered by Large Language Models. The system is specifically designed to provide real-time, grammar-focused feedback, generate context-aware language exercises and track learner proficiency over time. The paper discusses the architecture, implementation and evaluation of LangLingual in detail. The results indicate strong usability, positive learning outcomes and encouraging learner engagement.
LWT-ARTERY-LABEL: A Lightweight Framework for Automated Coronary Artery Identification
Aug 09, 2025Coronary artery disease (CAD) remains the leading cause of death globally, with computed tomography coronary angiography (CTCA) serving as a key diagnostic tool. However, coronary arterial analysis using CTCA, such as identifying artery-specific features from computational modelling, is labour-intensive and time-consuming. Automated anatomical labelling of coronary arteries offers a potential solution, yet the inherent anatomical variability of coronary trees presents a significant challenge. Traditional knowledge-based labelling methods fall short in leveraging data-driven insights, while recent deep-learning approaches often demand substantial computational resources and overlook critical clinical knowledge. To address these limitations, we propose a lightweight method that integrates anatomical knowledge with rule-based topology constraints for effective coronary artery labelling. Our approach achieves state-of-the-art performance on benchmark datasets, providing a promising alternative for automated coronary artery labelling.
Designing a Robust Radiology Report Generation System
Nov 02, 2024Recent advances in deep learning have enabled researchers to explore tasks at the intersection of computer vision and natural language processing, such as image captioning, visual question answering, visual dialogue, and visual language navigation. Taking inspiration from image captioning, the task of radiology report generation aims at automatically generating radiology reports by having a comprehensive understanding of medical images. However, automatically generating radiology reports from medical images is a challenging task due to the complexity, diversity, and nature of medical images. In this paper, we outline the design of a robust radiology report generation system by integrating different modules and highlighting best practices drawing upon lessons from our past work and also from relevant studies in the literature. We also discuss the impact of integrating different components to form a single integrated system. We believe that these best practices, when implemented, could improve automatic radiology report generation, augment radiologists in decision making, and expedite diagnostic workflow, in turn improve healthcare and save human lives.
Clinical Context-aware Radiology Report Generation from Medical Images using Transformers
Aug 21, 2024Recent developments in the field of Natural Language Processing, especially language models such as the transformer have brought state-of-the-art results in language understanding and language generation. In this work, we investigate the use of the transformer model for radiology report generation from chest X-rays. We also highlight limitations in evaluating radiology report generation using only the standard language generation metrics. We then applied a transformer based radiology report generation architecture, and also compare the performance of a transformer based decoder with the recurrence based decoder. Experiments were performed using the IU-CXR dataset, showing superior results to its LSTM counterpart and being significantly faster. Finally, we identify the need of evaluating radiology report generation system using both language generation metrics and classification metrics, which helps to provide robust measure of generated reports in terms of their coherence and diagnostic value.