 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Question Answering in the Medical Domain
Sep 20, 2023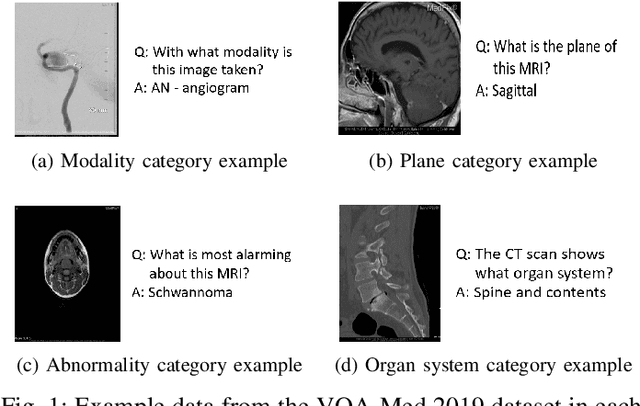
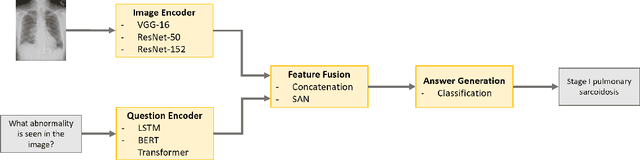
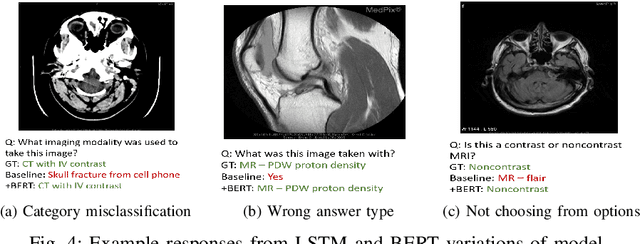
Medical visual question answering (Med-VQA) is a machine learning task that aims to create a system that can answer natural language questions based on given medical images. Although there has been rapid progress on the general VQA task, less progress has been made on Med-VQA due to the lack of large-scale annotated datasets. In this paper, we present domain-specific pre-training strategies, including a novel contrastive learning pretraining method, to mitigate the problem of small datasets for the Med-VQA task. We find that the model benefits from components that use fewer parameters. We also evaluate and discuss the model's visual reasoning using evidence verification techniques. Our proposed model obtained an accuracy of 60% on the VQA-Med 2019 test set, giving comparable results to other state-of-the-art Med-VQA models.