 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Behind Things: Extending Semantic Segmentation to Occluded Regions
Paper and Code
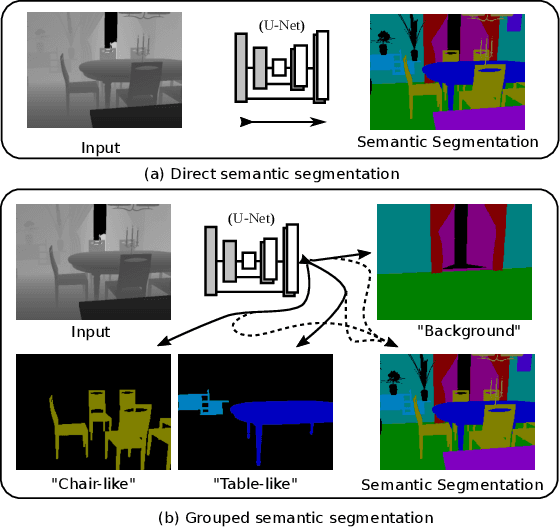

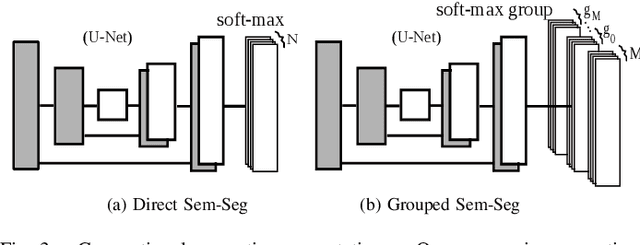

Semantic segmentation and instance level segmentation made substantial progress in recent years due to the emergence of deep neural networks (DNNs). A number of deep architectures with Convolution Neural Networks (CNNs) were proposed that surpass the traditional machine learning approaches for segmentation by a large margin. These architectures predict the directly observable semantic category of each pixel by usually optimizing a cross entropy loss. In this work we push the limit of semantic segmentation towards predicting semantic labels of directly visible as well as occluded objects or objects parts, where the network's input is a single depth image. We group the semantic categories into one background and multiple foreground object groups, and we propose a modification of the standard cross-entropy loss to cope with the settings. In our experiments we demonstrate that a CNN trained by minimizing the proposed loss is able to predict semantic categories for visible and occluded object parts without requiring to increase the network size (compared to a standard segmentation task). The results are validated on a newly generated dataset (augmented from SUNCG) dataset.