 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Kalman-based hybrid car following strategy using TD3 and CACC
Dec 26, 2023In autonomous driving, the hybrid strategy of deep reinforcement learning and cooperative adaptive cruise control (CACC) can fully utilize the advantages of the two algorithms and significantly improve the performance of car following. However, it is challenging for the traditional hybrid strategy based on fixed coefficients to adapt to mixed traffic flow scenarios, which may decrease the performance and even lead to accidents. To address the above problems, a hybrid car following strategy based on an adaptive Kalman Filter is proposed by regarding CACC and Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithms. Different from traditional hybrid strategy based on fixed coefficients, the Kalman gain H, using as an adaptive coefficient, is derived from multi-timestep predictions and Monte Carlo Tree Search. At the end of study, simulation results with 4157745 timesteps indicate that, compared with the TD3 and HCFS algorithms, the proposed algorithm in this study can substantially enhance the safety of car following in mixed traffic flow without compromising the comfort and efficiency.
Hybrid Car-Following Strategy based on Deep Deterministic Policy Gradient and Cooperative Adaptive Cruise Control
Feb 24, 2021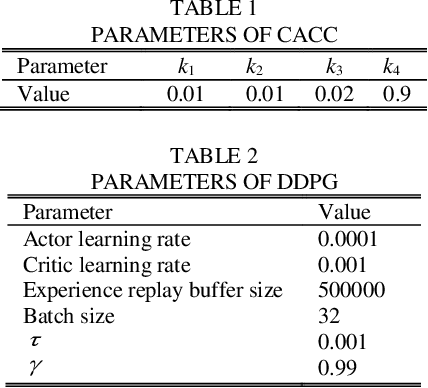
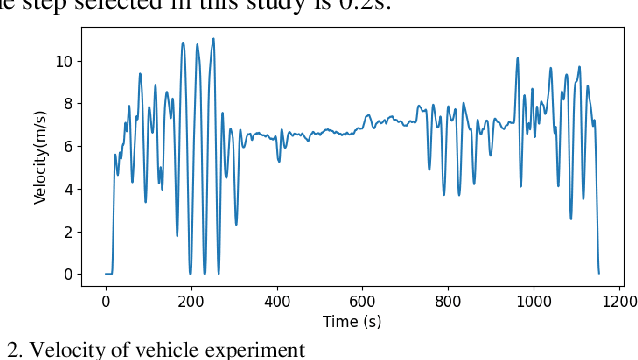
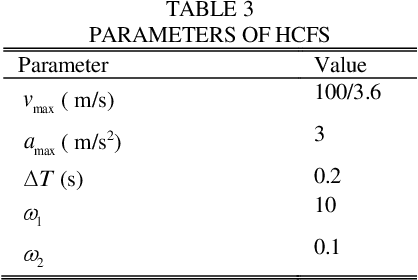
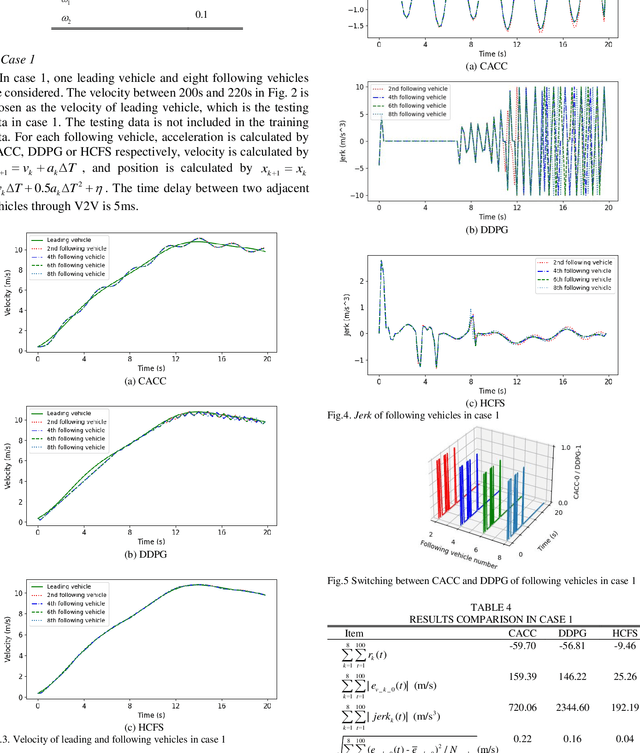
Deep deterministic policy gradient (DDPG) based car-following strategy can break through the constraints of the differential equation model due to the ability of exploration on complex environments. However, the car-following performance of DDPG is usually degraded by unreasonable reward function design, insufficient training and low sampling efficiency. In order to solve this kind of problem, a hybrid car-following strategy based on DDPG and cooperative adaptive cruise control (CACC) is proposed. Firstly, the car-following process is modeled as markov decision process to calculate CACC and DDPG simultaneously at each frame. Given a current state, two actions are obtained from CACC and DDPG, respectively. Then an optimal action, corresponding to the one offering a larger reward, is chosen as the output of the hybrid strategy. Meanwhile, a rule is designed to ensure that the change rate of acceleration is smaller than the desired value. Therefore, the proposed strategy not only guarantees the basic performance of car-following through CACC, but also makes full use of the advantages of exploration on complex environments via DDPG. Finally, simulation results show that the car-following performance of proposed strategy is improved significantly as compared with that of DDPG and CACC in the whole state space.