 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIR: Unifying Individual and Collective Exploration in Cooperative Multi-Agent Reinforcement Learning
Dec 30, 2024Exploration in cooperative multi-agent reinforcement learning (MARL) remains challenging for value-based agents due to the absence of an explicit policy. Existing approaches include individual exploration based on uncertainty towards the system and collective exploration through behavioral diversity among agents. However, the introduction of additional structures often leads to reduced training efficiency and infeasible integration of these methods. In this paper, we propose Adaptive exploration via Identity Recognition~(AIR), which consists of two adversarial components: a classifier that recognizes agent identities from their trajectories, and an action selector that adaptively adjusts the mode and degree of exploration. We theoretically prove that AIR can facilitate both individual and collective exploration during training, and experiments also demonstrate the efficiency and effectiveness of AIR across various tasks.
AIR: Unifying Individual and Cooperative Exploration in Collective Multi-Agent Reinforcement Learning
Dec 20, 2024Exploration in cooperative multi-agent reinforcement learning (MARL) remains challenging for value-based agents due to the absence of an explicit policy. Existing approaches include individual exploration based on uncertainty towards the system and collective exploration through behavioral diversity among agents. However, the introduction of additional structures often leads to reduced training efficiency and infeasible integration of these methods. In this paper, we propose Adaptive exploration via Identity Recognition~(AIR), which consists of two adversarial components: a classifier that recognizes agent identities from their trajectories, and an action selector that adaptively adjusts the mode and degree of exploration. We theoretically prove that AIR can facilitate both individual and collective exploration during training, and experiments also demonstrate the efficiency and effectiveness of AIR across various tasks.
Mastering Complex Coordination through Attention-based Dynamic Graph
Dec 07, 2023The coordination between agents in multi-agent systems has become a popular topic in many fields. To catch the inner relationship between agents, the graph structure is combined with existing methods and improves the results. But in large-scale tasks with numerous agents, an overly complex graph would lead to a boost in computational cost and a decline in performance. Here we present DAGMIX, a novel graph-based value factorization method. Instead of a complete graph, DAGMIX generates a dynamic graph at each time step during training, on which it realizes a more interpretable and effective combining process through the attention mechanism. Experiments show that DAGMIX significantly outperforms previous SOTA methods in large-scale scenarios, as well as achieving promising results on other tasks.
Dual Self-Awareness Value Decomposition Framework without Individual Global Max for Cooperative Multi-Agent Reinforcement Learning
Feb 04, 2023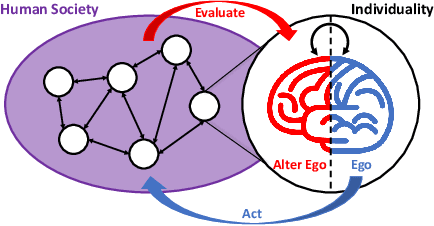



Value decomposition methods have gradually become popular in the cooperative multi-agent reinforcement learning field. However, almost all value decomposition methods follow the Individual Global Max (IGM) principle or its variants, which restricts the range of issues that value decomposition methods can resolve. Inspired by the notion of dual self-awareness in psychology, we propose a dual self-awareness value decomposition framework that entirely rejects the IGM premise. Each agent consists of an ego policy that carries out actions and an alter ego value function that takes part in credit assignment. The value function factorization can ignore the IGM assumption by using an explicit search procedure. We also suggest a novel anti-ego exploration mechanism to avoid the algorithm becoming stuck in a local optimum. As the first fully IGM-free value decomposition method, our proposed framework achieves desirable performance in various cooperative tasks.
Consensus Learning for Cooperative Multi-Agent Reinforcement Learning
Jun 06, 2022
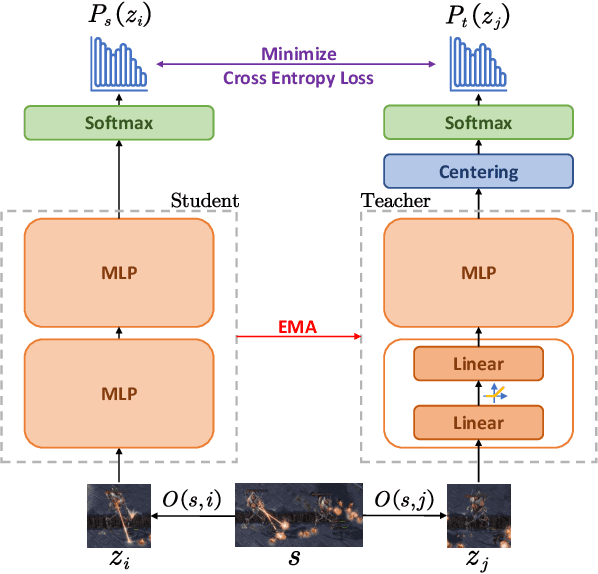


Almost all multi-agent reinforcement learning algorithms without communication follow the principle of centralized training with decentralized execution. During centralized training, agents can be guided by the same signals, such as the global state. During decentralized execution, however, agents lack the shared signal. Inspired by viewpoint invariance and contrastive learning, we propose consensus learning for cooperative multi-agent reinforcement learning in this paper. Although based on local observations, different agents can infer the same consensus in discrete space. During decentralized execution, we feed the inferred consensus as an explicit input to the network of agents, thereby developing their spirit of cooperation. Our proposed method can be extended to various multi-agent reinforcement learning algorithms. Moreover, we carry out them on some fully cooperative tasks and get convincing results.