 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised learning via DQN for log anomaly detection
Jan 06, 2024



Log anomaly detection plays a critical role in ensuring the security and maintenance of modern software systems. At present, the primary approach for detecting anomalies in log data is through supervised anomaly detection. Nonetheless, existing supervised methods heavily rely on labeled data, which can be frequently limited in real-world scenarios. In this paper, we propose a semi-supervised log anomaly detection method that combines the DQN algorithm from deep reinforcement learning, which is called DQNLog. DQNLog leverages a small amount of labeled data and a large-scale unlabeled dataset, effectively addressing the challenges of imbalanced data and limited labeling. This approach not only learns known anomalies by interacting with an environment biased towards anomalies but also discovers unknown anomalies by actively exploring the unlabeled dataset. Additionally, DQNLog incorporates a cross-entropy loss term to prevent model overestimation during Deep Reinforcement Learning (DRL). Our evaluation on three widely-used datasets demonstrates that DQNLog significantly improves recall rate and F1-score while maintaining precision, validating its practicality.
FORCE: A Framework of Rule-Based Conversational Recommender System
Mar 18, 2022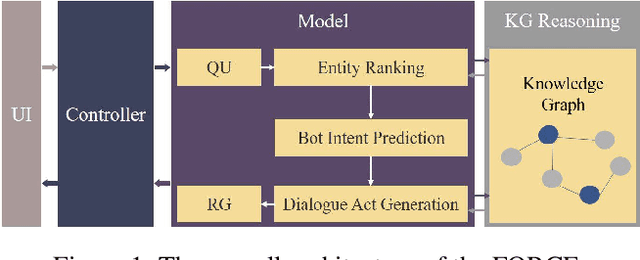
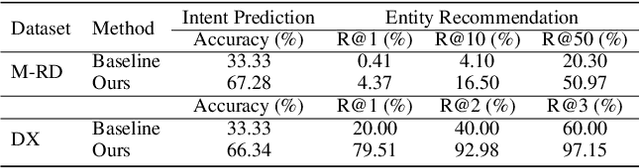
The conversational recommender systems (CRSs) have received extensive attention in recent years. However, most of the existing works focus on various deep learning models, which are largely limited by the requirement of large-scale human-annotated datasets. Such methods are not able to deal with the cold-start scenarios in industrial products. To alleviate the problem, we propose FORCE, a Framework Of Rule-based Conversational Recommender system that helps developers to quickly build CRS bots by simple configuration. We conduct experiments on two datasets in different languages and domains to verify its effectiveness and usability.
Learning Neural Templates for Recommender Dialogue System
Sep 25, 2021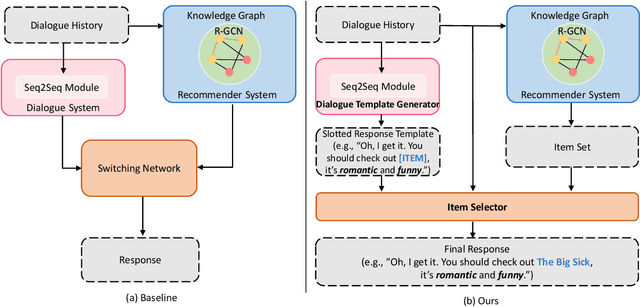

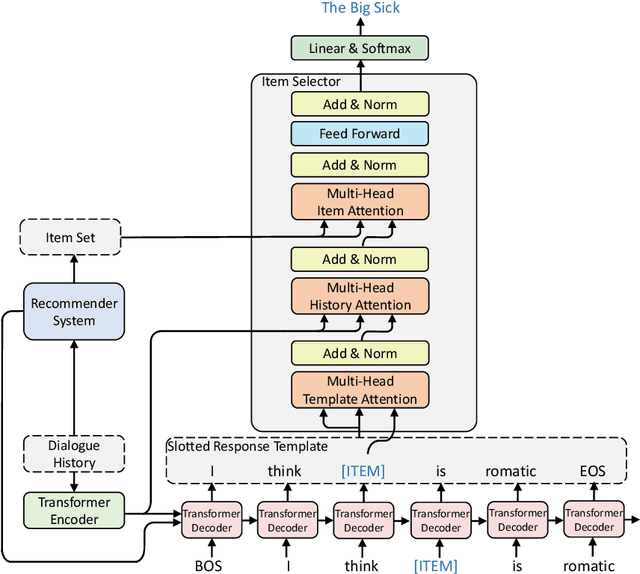

Though recent end-to-end neural models have shown promising progress on Conversational Recommender System (CRS), two key challenges still remain. First, the recommended items cannot be always incorporated into the generated replies precisely and appropriately. Second, only the items mentioned in the training corpus have a chance to be recommended in the conversation. To tackle these challenges, we introduce a novel framework called NTRD for recommender dialogue system that decouples the dialogue generation from the item recommendation. NTRD has two key components, i.e., response template generator and item selector. The former adopts an encoder-decoder model to generate a response template with slot locations tied to target items, while the latter fills in slot locations with the proper items using a sufficient attention mechanism. Our approach combines the strengths of both classical slot filling approaches (that are generally controllable) and modern neural NLG approaches (that are generally more natural and accurate). Extensive experiments on the benchmark ReDial show our NTRD significantly outperforms the previous state-of-the-art methods. Besides, our approach has the unique advantage to produce novel items that do not appear in the training set of dialogue corpus. The code is available at \url{https://github.com/jokieleung/NTRD}.