 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJANUS: A Dual-Constraint Generative Framework for Stealthy Node Injection Attacks
Sep 16, 2025Graph Neural Networks (GNNs) have demonstrated remarkable performance across various applications, yet they are vulnerable to sophisticated adversarial attacks, particularly node injection attacks. The success of such attacks heavily relies on their stealthiness, the ability to blend in with the original graph and evade detection. However, existing methods often achieve stealthiness by relying on indirect proxy metrics, lacking consideration for the fundamental characteristics of the injected content, or focusing only on imitating local structures, which leads to the problem of local myopia. To overcome these limitations, we propose a dual-constraint stealthy node injection framework, called Joint Alignment of Nodal and Universal Structures (JANUS). At the local level, we introduce a local feature manifold alignment strategy to achieve geometric consistency in the feature space. At the global level, we incorporate structured latent variables and maximize the mutual information with the generated structures, ensuring the injected structures are consistent with the semantic patterns of the original graph. We model the injection attack as a sequential decision process, which is optimized by a reinforcement learning agent. Experiments on multiple standard datasets demonstrate that the JANUS framework significantly outperforms existing methods in terms of both attack effectiveness and stealthiness.
Revisiting the Relationship between Adversarial and Clean Training: Why Clean Training Can Make Adversarial Training Better
Mar 30, 2025Adversarial training (AT) is an effective technique for enhancing adversarial robustness, but it usually comes at the cost of a decline in generalization ability. Recent studies have attempted to use clean training to assist adversarial training, yet there are contradictions among the conclusions. We comprehensively summarize the representative strategies and, with a focus on the multi - view hypothesis, provide a unified explanation for the contradictory phenomena among different studies. In addition, we conduct an in - depth analysis of the knowledge combinations transferred from clean - trained models to adversarially - trained models in previous studies, and find that they can be divided into two categories: reducing the learning difficulty and providing correct guidance. Based on this finding, we propose a new idea of leveraging clean training to further improve the performance of advanced AT methods.We reveal that the problem of generalization degradation faced by AT partly stems from the difficulty of adversarial training in learning certain sample features, and this problem can be alleviated by making full use of clean training.
Multi-view Fake News Detection Model Based on Dynamic Hypergraph
Dec 26, 2024With the rapid development of online social networks and the inadequacies in content moderation mechanisms, the detection of fake news has emerged as a pressing concern for the public. Various methods have been proposed for fake news detection, including text-based approaches as well as a series of graph-based approaches. However, the deceptive nature of fake news renders text-based approaches less effective. Propagation tree-based methods focus on the propagation process of individual news, capturing pairwise relationships but lacking the capability to capture high-order complex relationships. Large heterogeneous graph-based approaches necessitate the incorporation of substantial additional information beyond news text and user data, while hypergraph-based approaches rely on predefined hypergraph structures. To tackle these issues, we propose a novel dynamic hypergraph-based multi-view fake news detection model (DHy-MFND) that learns news embeddings across three distinct views: text-level, propagation tree-level, and hypergraph-level. By employing hypergraph structures to model complex high-order relationships among multiple news pieces and introducing dynamic hypergraph structure learning, we optimize predefined hypergraph structures while learning news embeddings. Additionally, we introduce contrastive learning to capture authenticity-relevant embeddings across different views. Extensive experiments on two benchmark datasets demonstrate the effectiveness of our proposed DHy-MFND compared with a broad range of competing baselines.
AHSG: Adversarial Attacks on High-level Semantics in Graph Neural Networks
Dec 10, 2024



Graph Neural Networks (GNNs) have garnered significant interest among researchers due to their impressive performance in graph learning tasks. However, like other deep neural networks, GNNs are also vulnerable to adversarial attacks. In existing adversarial attack methods for GNNs, the metric between the attacked graph and the original graph is usually the attack budget or a measure of global graph properties. However, we have found that it is possible to generate attack graphs that disrupt the primary semantics even within these constraints. To address this problem, we propose a Adversarial Attacks on High-level Semantics in Graph Neural Networks (AHSG), which is a graph structure attack model that ensures the retention of primary semantics. The latent representations of each node can extract rich semantic information by applying convolutional operations on graph data. These representations contain both task-relevant primary semantic information and task-irrelevant secondary semantic information. The latent representations of same-class nodes with the same primary semantics can fulfill the objective of modifying secondary semantics while preserving the primary semantics. Finally, the latent representations with attack effects is mapped to an attack graph using Projected Gradient Descent (PGD) algorithm. By attacking graph deep learning models with some advanced defense strategies, we validate that AHSG has superior attack effectiveness compared to other attack methods. Additionally, we employ Contextual Stochastic Block Models (CSBMs) as a proxy for the primary semantics to detect the attacked graph, confirming that AHSG almost does not disrupt the original primary semantics of the graph.
IENE: Identifying and Extrapolating the Node Environment for Out-of-Distribution Generalization on Graphs
Jun 02, 2024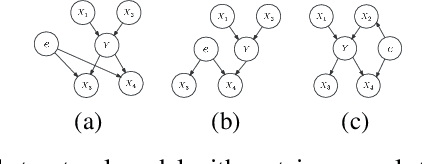

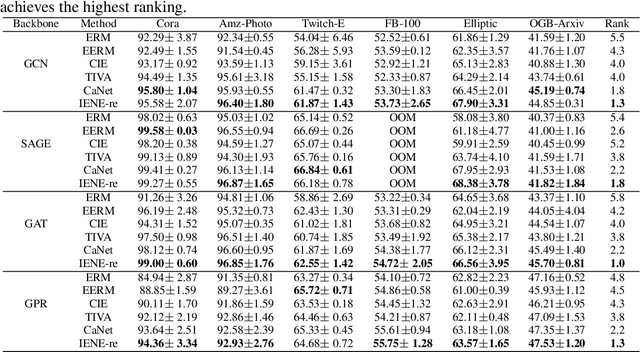
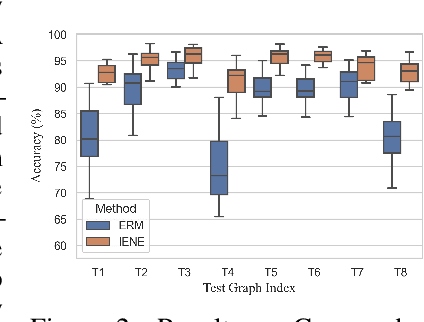
Due to the performance degradation of graph neural networks (GNNs) under distribution shifts, the work on out-of-distribution (OOD) generalization on graphs has received widespread attention. A novel perspective involves distinguishing potential confounding biases from different environments through environmental identification, enabling the model to escape environmentally-sensitive correlations and maintain stable performance under distribution shifts. However, in graph data, confounding factors not only affect the generation process of node features but also influence the complex interaction between nodes. We observe that neglecting either aspect of them will lead to a decrease in performance. In this paper, we propose IENE, an OOD generalization method on graphs based on node-level environmental identification and extrapolation techniques. It strengthens the model's ability to extract invariance from two granularities simultaneously, leading to improved generalization. Specifically, to identify invariance in features, we utilize the disentangled information bottleneck framework to achieve mutual promotion between node-level environmental estimation and invariant feature learning. Furthermore, we extrapolate topological environments through graph augmentation techniques to identify structural invariance. We implement the conceptual method with specific algorithms and provide theoretical analysis and proofs for our approach. Extensive experimental evaluations on two synthetic and four real-world OOD datasets validate the superiority of IENE, which outperforms existing techniques and provides a flexible framework for enhancing the generalization of GNNs.
Hyperedge Interaction-aware Hypergraph Neural Network
Jan 28, 2024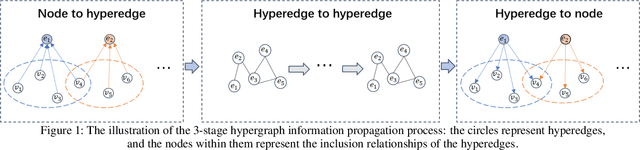

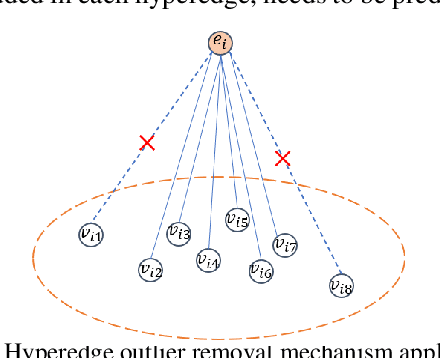
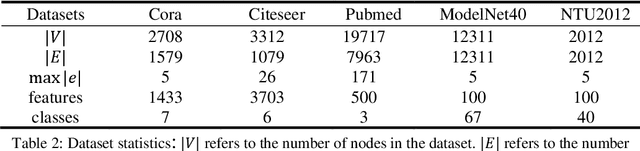
Hypergraphs provide an effective modeling approach for modeling high-order relationships in many real-world datasets. To capture such complex relationships, several hypergraph neural networks have been proposed for learning hypergraph structure, which propagate information from nodes to hyperedges and then from hyperedges back to nodes. However, most existing methods focus on information propagation between hyperedges and nodes, neglecting the interactions among hyperedges themselves. In this paper, we propose HeIHNN, a hyperedge interaction-aware hypergraph neural network, which captures the interactions among hyperedges during the convolution process and introduce a novel mechanism to enhance information flow between hyperedges and nodes. Specifically, HeIHNN integrates the interactions between hyperedges into the hypergraph convolution by constructing a three-stage information propagation process. After propagating information from nodes to hyperedges, we introduce a hyperedge-level convolution to update the hyperedge embeddings. Finally, the embeddings that capture rich information from the interaction among hyperedges will be utilized to update the node embeddings. Additionally, we introduce a hyperedge outlier removal mechanism in the information propagation stages between nodes and hyperedges, which dynamically adjusts the hypergraph structure using the learned embeddings, effectively removing outliers. Extensive experiments conducted on real-world datasets show the competitive performance of HeIHNN compared with state-of-the-art methods.
Semi-supervised learning via DQN for log anomaly detection
Jan 06, 2024



Log anomaly detection plays a critical role in ensuring the security and maintenance of modern software systems. At present, the primary approach for detecting anomalies in log data is through supervised anomaly detection. Nonetheless, existing supervised methods heavily rely on labeled data, which can be frequently limited in real-world scenarios. In this paper, we propose a semi-supervised log anomaly detection method that combines the DQN algorithm from deep reinforcement learning, which is called DQNLog. DQNLog leverages a small amount of labeled data and a large-scale unlabeled dataset, effectively addressing the challenges of imbalanced data and limited labeling. This approach not only learns known anomalies by interacting with an environment biased towards anomalies but also discovers unknown anomalies by actively exploring the unlabeled dataset. Additionally, DQNLog incorporates a cross-entropy loss term to prevent model overestimation during Deep Reinforcement Learning (DRL). Our evaluation on three widely-used datasets demonstrates that DQNLog significantly improves recall rate and F1-score while maintaining precision, validating its practicality.
Deeper and Wider Networks for Performance Metrics Prediction in Communication Networks
Dec 31, 2023In today's era, users have increasingly high expectations regarding the performance and efficiency of communication networks. Network operators aspire to achieve efficient network planning, operation, and optimization through Digital Twin Networks (DTN). The effectiveness of DTN heavily relies on the network model, with graph neural networks (GNN) playing a crucial role in network modeling. However, existing network modeling methods still lack a comprehensive understanding of communication networks. In this paper, we propose DWNet (Deeper and Wider Networks), a heterogeneous graph neural network modeling method based on data-driven approaches that aims to address end-to-end latency and jitter prediction in network models. This method stands out due to two distinctive features: firstly, it introduces deeper levels of state participation in the message passing process; secondly, it extensively integrates relevant features during the feature fusion process. Through experimental validation and evaluation, our model achieves higher prediction accuracy compared to previous research achievements, particularly when dealing with unseen network topologies during model training. Our model not only provides more accurate predictions but also demonstrates stronger generalization capabilities across diverse topological structures.
HC-Ref: Hierarchical Constrained Refinement for Robust Adversarial Training of GNNs
Dec 08, 2023Recent studies have shown that attackers can catastrophically reduce the performance of GNNs by maliciously modifying the graph structure or node features on the graph. Adversarial training, which has been shown to be one of the most effective defense mechanisms against adversarial attacks in computer vision, holds great promise for enhancing the robustness of GNNs. There is limited research on defending against attacks by performing adversarial training on graphs, and it is crucial to delve deeper into this approach to optimize its effectiveness. Therefore, based on robust adversarial training on graphs, we propose a hierarchical constraint refinement framework (HC-Ref) that enhances the anti-perturbation capabilities of GNNs and downstream classifiers separately, ultimately leading to improved robustness. We propose corresponding adversarial regularization terms that are conducive to adaptively narrowing the domain gap between the normal part and the perturbation part according to the characteristics of different layers, promoting the smoothness of the predicted distribution of both parts. Moreover, existing research on graph robust adversarial training primarily concentrates on training from the standpoint of node feature perturbations and seldom takes into account alterations in the graph structure. This limitation makes it challenging to prevent attacks based on topological changes in the graph. This paper generates adversarial examples by utilizing graph structure perturbations, offering an effective approach to defend against attack methods that are based on topological changes. Extensive experiments on two real-world graph benchmarks show that HC-Ref successfully resists various attacks and has better node classification performance compared to several baseline methods.
Fine-grained Graph Learning for Multi-view Subspace Clustering
Jan 13, 2022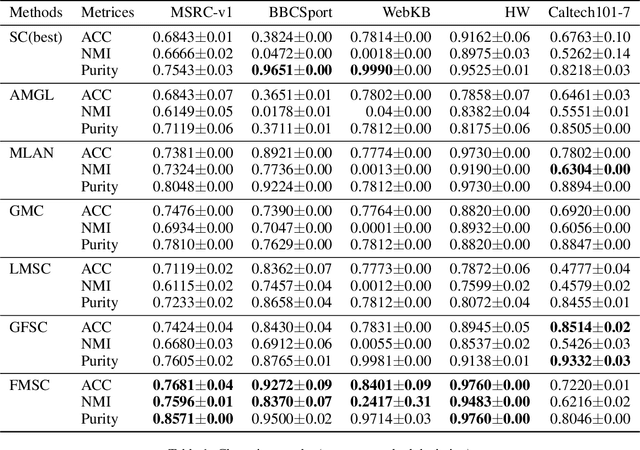
Multi-view subspace clustering has conventionally focused on integrating heterogeneous feature descriptions to capture higher-dimensional information. One popular strategy is to generate a common subspace from different views and then apply graph-based approaches to deal with clustering. However, the performance of these methods is still subject to two limitations, namely the multiple views fusion pattern and the connection between the fusion process and clustering tasks. To address these problems, we propose a novel multi-view subspace clustering framework via fine-grained graph learning, which can tell the consistency of local structures between different views and integrate all views more delicately than previous weight regularizations. Different from other models in the literature, the point-level graph regularization and the reformulation of spectral clustering are introduced to perform graphs fusion and learn the shared cluster structure together. Extensive experiments on five real-world datasets show that the proposed framework has comparable performance to the SOTA algorithms.