 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG2A2: An Automated Graph Generator with Attributes and Anomalies
Oct 14, 2022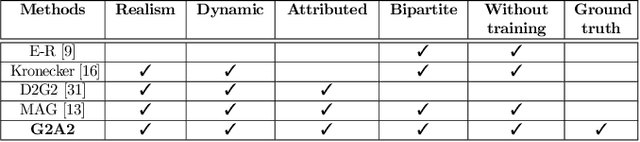
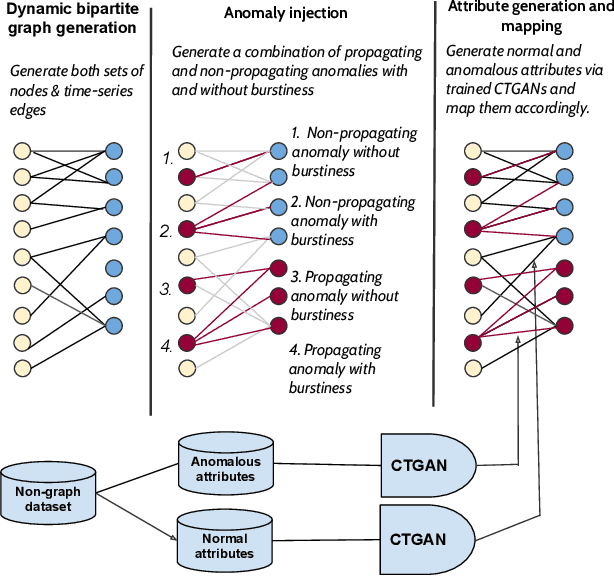
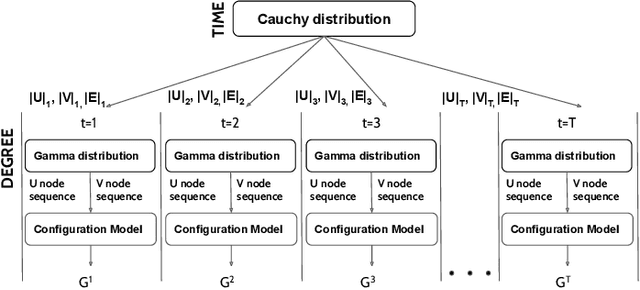

Many data-mining applications use dynamic attributed graphs to represent relational information; but due to security and privacy concerns, there is a dearth of available datasets that can be represented as dynamic attributed graphs. Even when such datasets are available, they do not have ground truth that can be used to train deep-learning models. Thus, we present G2A2, an automated graph generator with attributes and anomalies, which encompasses (1) probabilistic models to generate a dynamic bipartite graph, representing time-evolving connections between two independent sets of entities, (2) realistic injection of anomalies using a novel algorithm that captures the general properties of graph anomalies across domains, and (3) a deep generative model to produce realistic attributes, learned from an existing real-world dataset. Using the maximum mean discrepancy (MMD) metric to evaluate the realism of a G2A2-generated graph against three real-world graphs, G2A2 outperforms Kronecker graph generation by reducing the MMD distance by up to six-fold (6x).
A Deep-Learning Framework for Improving COVID-19 CT Image Quality and Diagnostic Accuracy
Dec 16, 2021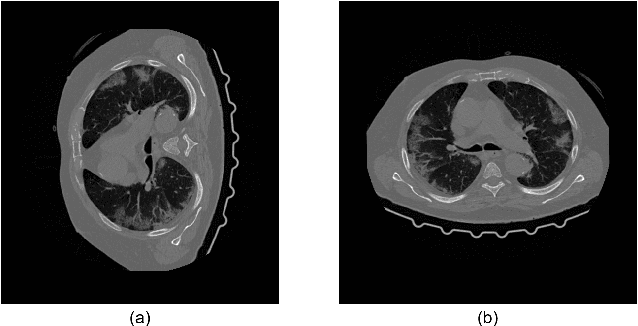
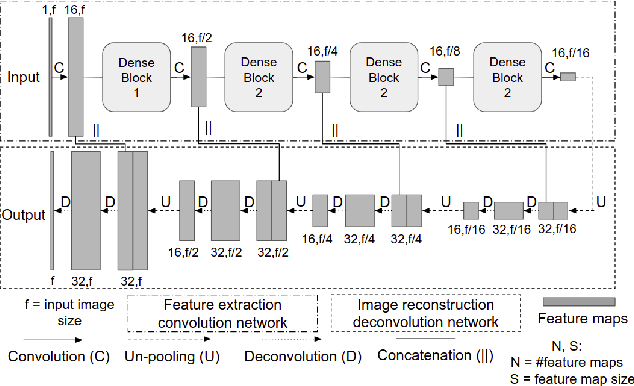
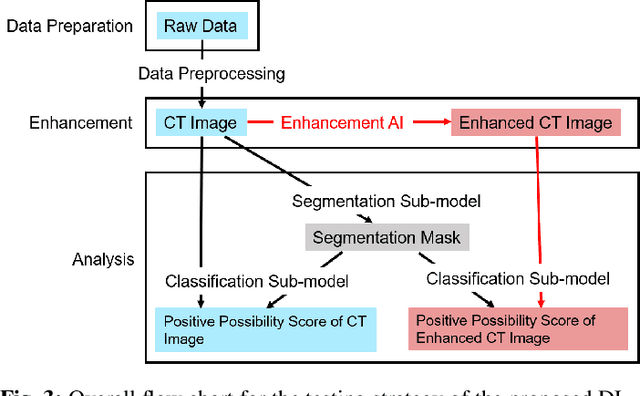
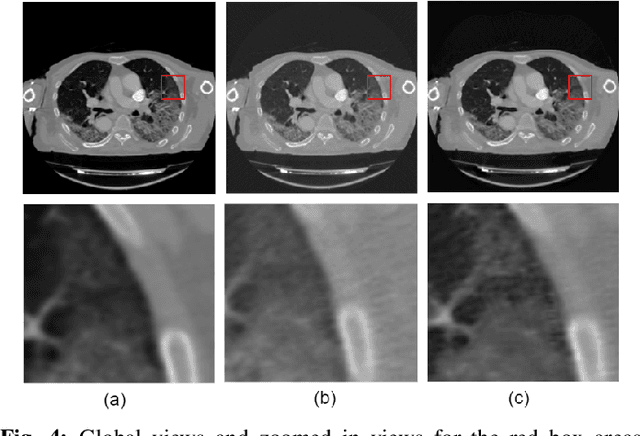
We present a deep-learning based computing framework for fast-and-accurate CT (DL-FACT) testing of COVID-19. Our CT-based DL framework was developed to improve the testing speed and accuracy of COVID-19 (plus its variants) via a DL-based approach for CT image enhancement and classification. The image enhancement network is adapted from DDnet, short for DenseNet and Deconvolution based network. To demonstrate its speed and accuracy, we evaluated DL-FACT across several sources of COVID-19 CT images. Our results show that DL-FACT can significantly shorten the turnaround time from days to minutes and improve the COVID-19 testing accuracy up to 91%. DL-FACT could be used as a software tool for medical professionals in diagnosing and monitoring COVID-19.
Topology-Guided Sampling for Fast and Accurate Community Detection
Aug 15, 2021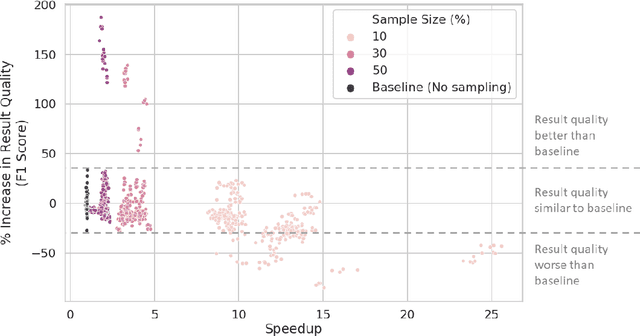
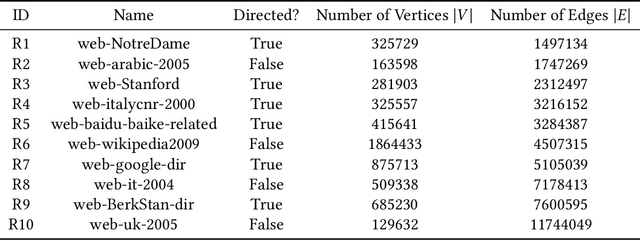
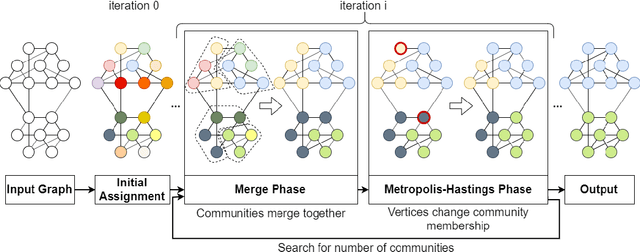
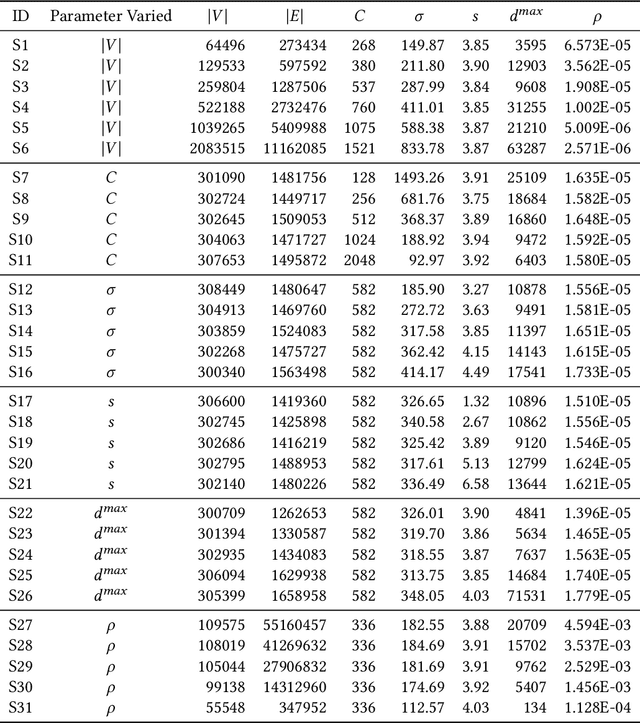
Community detection is a well-studied problem with applications in domains ranging from computer networking to bioinformatics. While there are many algorithms that perform community detection, the more accurate and statistically robust algorithms tend to be slow and hard to parallelize. One way to speed up such algorithms is through data reduction. However, this approach has not been thoroughly studied, and the quality of results obtained with this approach varies with the graph it is applied to. In this manuscript, we present an approach based on topology-guided sampling for accelerating stochastic block partitioning - a community detection algorithm that works well on graphs with complex and heterogeneous community structure. We also introduce a degree-based thresholding scheme that improves the efficacy of our approach at the expense of speedup. Finally, we perform a series of experiments on synthetically generated graphs to determine how various graph parameters affect the quality of results and speedup obtained with our approach, and we validate our approach on real-world data. Our results show that our approach can lead to a speedup of up to 15X over stochastic block partitioning without sampling while maintaining result quality and can even lead to improvements of over 150% in result quality in terms of F1 score on certain kinds of graphs.