 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Vision Transformer with Cross Feature Attention
Paper and Code
Jul 15, 2022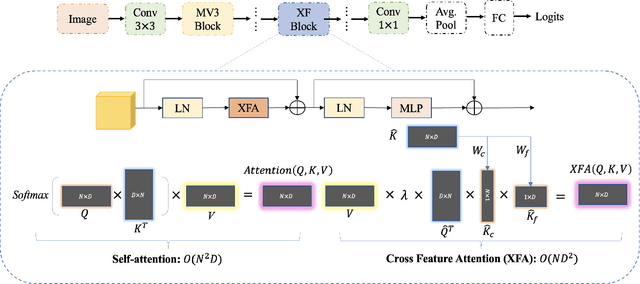
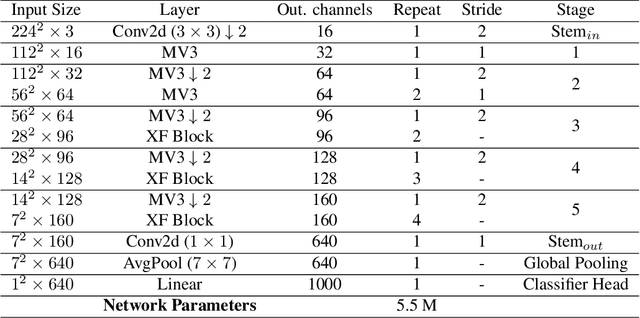


Recent advances in vision transformers (ViTs) have achieved great performance in visual recognition tasks. Convolutional neural networks (CNNs) exploit spatial inductive bias to learn visual representations, but these networks are spatially local. ViTs can learn global representations with their self-attention mechanism, but they are usually heavy-weight and unsuitable for mobile devices. In this paper, we propose cross feature attention (XFA) to bring down computation cost for transformers, and combine efficient mobile CNNs to form a novel efficient light-weight CNN-ViT hybrid model, XFormer, which can serve as a general-purpose backbone to learn both global and local representation. Experimental results show that XFormer outperforms numerous CNN and ViT-based models across different tasks and datasets. On ImageNet1K dataset, XFormer achieves top-1 accuracy of 78.5% with 5.5 million parameters, which is 2.2% and 6.3% more accurate than EfficientNet-B0 (CNN-based) and DeiT (ViT-based) for similar number of parameters. Our model also performs well when transferring to object detection and semantic segmentation tasks. On MS COCO dataset, XFormer exceeds MobileNetV2 by 10.5 AP (22.7 -> 33.2 AP) in YOLOv3 framework with only 6.3M parameters and 3.8G FLOPs. On Cityscapes dataset, with only a simple all-MLP decoder, XFormer achieves mIoU of 78.5 and FPS of 15.3, surpassing state-of-the-art lightweight segmentation networks.