 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMGCP: A Multi-Grained Correlation based Prediction Network for Multivariate Time Series
May 30, 2024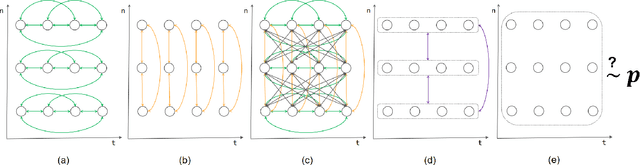
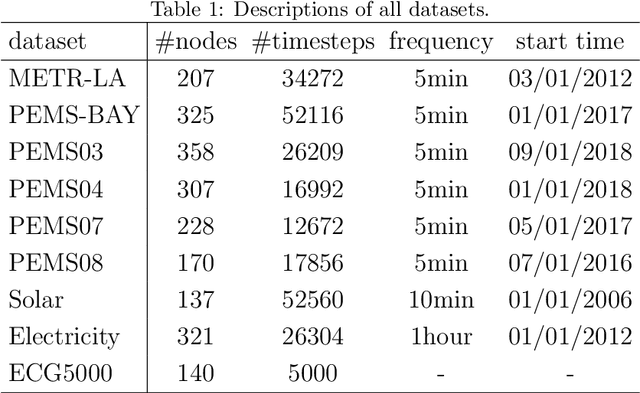
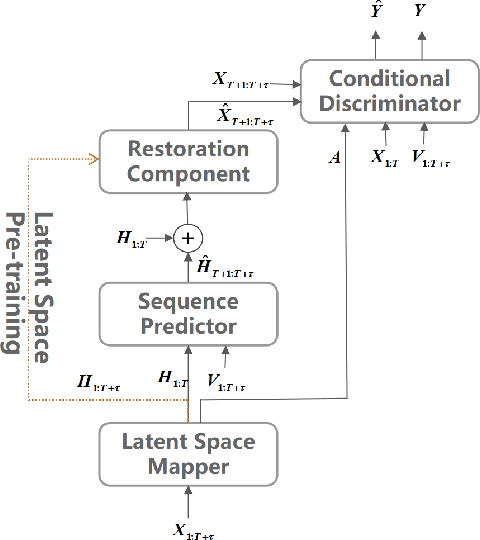
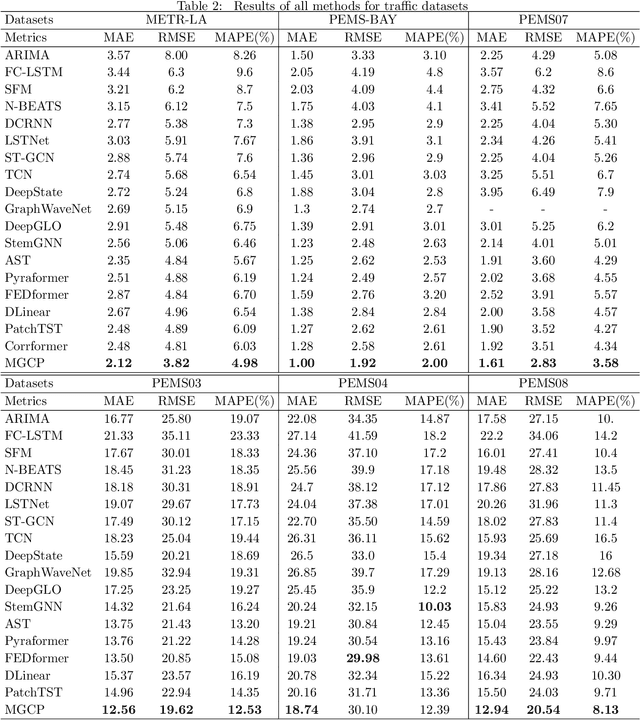
Multivariate time series prediction is widely used in daily life, which poses significant challenges due to the complex correlations that exist at multi-grained levels. Unfortunately, the majority of current time series prediction models fail to simultaneously learn the correlations of multivariate time series at multi-grained levels, resulting in suboptimal performance. To address this, we propose a Multi-Grained Correlations-based Prediction (MGCP) Network, which simultaneously considers the correlations at three granularity levels to enhance prediction performance. Specifically, MGCP utilizes Adaptive Fourier Neural Operators and Graph Convolutional Networks to learn the global spatiotemporal correlations and inter-series correlations, enabling the extraction of potential features from multivariate time series at fine-grained and medium-grained levels. Additionally, MGCP employs adversarial training with an attention mechanism-based predictor and conditional discriminator to optimize prediction results at coarse-grained level, ensuring high fidelity between the generated forecast results and the actual data distribution. Finally, we compare MGCP with several state-of-the-art time series prediction algorithms on real-world benchmark datasets, and our results demonstrate the generality and effectiveness of the proposed model.
Maintaining Discrimination and Fairness in Class Incremental Learning
Nov 16, 2019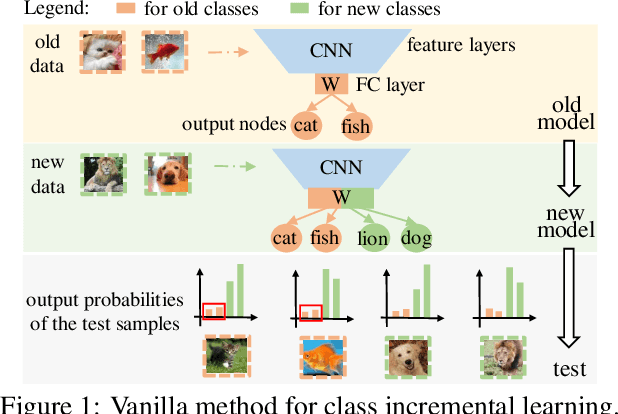
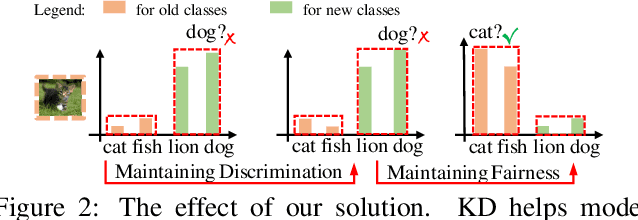
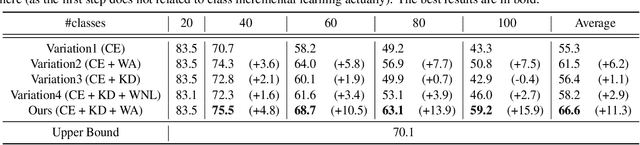
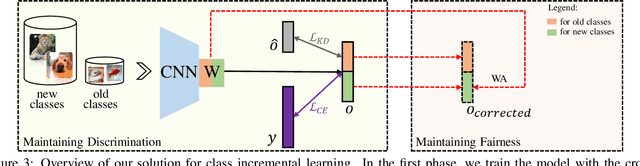
Deep neural networks (DNNs) have been applied in class incremental learning, which aims to solve common real-world problems of learning new classes continually. One drawback of standard DNNs is that they are prone to catastrophic forgetting. Knowledge distillation (KD) is a commonly used technique to alleviate this problem. In this paper, we demonstrate it can indeed help the model to output more discriminative results within old classes. However, it cannot alleviate the problem that the model tends to classify objects into new classes, causing the positive effect of KD to be hidden and limited. We observed that an important factor causing catastrophic forgetting is that the weights in the last fully connected (FC) layer are highly biased in class incremental learning. In this paper, we propose a simple and effective solution motivated by the aforementioned observations to address catastrophic forgetting. Firstly, we utilize KD to maintain the discrimination within old classes. Then, to further maintain the fairness between old classes and new classes, we propose Weight Aligning (WA) that corrects the biased weights in the FC layer after normal training process. Unlike previous work, WA does not require any extra parameters or a validation set in advance, as it utilizes the information provided by the biased weights themselves. The proposed method is evaluated on ImageNet-1000, ImageNet-100, and CIFAR-100 under various settings. Experimental results show that the proposed method can effectively alleviate catastrophic forgetting and significantly outperform state-of-the-art methods.