 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIRT: Improving Representation-based Models for Text Matching through Virtual Interaction
Paper and Code
Dec 08, 2021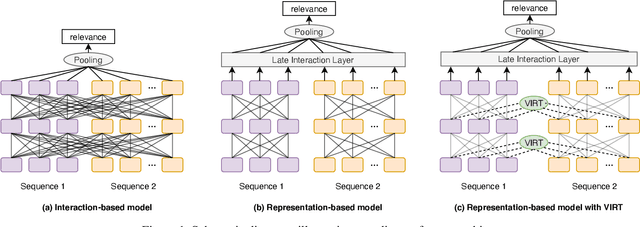
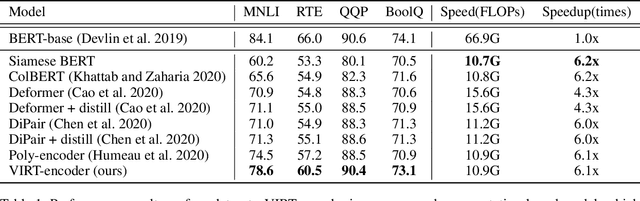

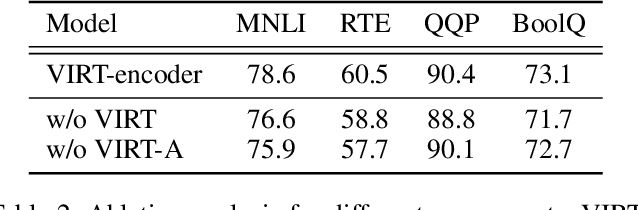
With the booming of pre-trained transformers, remarkable progress has been made on textual pair modeling to support relevant natural language applications. Two lines of approaches are developed for text matching: interaction-based models performing full interactions over the textual pair, and representation-based models encoding the pair independently with siamese encoders. The former achieves compelling performance due to its deep interaction modeling ability, yet with a sacrifice in inference latency. The latter is efficient and widely adopted for practical use, however, suffers from severe performance degradation due to the lack of interactions. Though some prior works attempt to integrate interactive knowledge into representation-based models, considering the computational cost, they only perform late interaction or knowledge transferring at the top layers. Interactive information in the lower layers is still missing, which limits the performance of representation-based solutions. To remedy this, we propose a novel \textit{Virtual} InteRacTion mechanism, termed as VIRT, to enable full and deep interaction modeling in representation-based models without \textit{actual} inference computations. Concretely, VIRT asks representation-based encoders to conduct virtual interactions to mimic the behaviors as interaction-based models do. In addition, the knowledge distilled from interaction-based encoders is taken as supervised signals to promise the effectiveness of virtual interactions. Since virtual interactions only happen at the training stage, VIRT would not increase the inference cost. Furthermore, we design a VIRT-adapted late interaction strategy to fully utilize the learned virtual interactive knowledge.